 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Siamese MAE Pretraining for Longitudinal Medical Images
Dec 29, 2025Temporally aware image representations are crucial for capturing disease progression in 3D volumes of longitudinal medical datasets. However, recent state-of-the-art self-supervised learning approaches like Masked Autoencoding (MAE), despite their strong representation learning capabilities, lack temporal awareness. In this paper, we propose STAMP (Stochastic Temporal Autoencoder with Masked Pretraining), a Siamese MAE framework that encodes temporal information through a stochastic process by conditioning on the time difference between the 2 input volumes. Unlike deterministic Siamese approaches, which compare scans from different time points but fail to account for the inherent uncertainty in disease evolution, STAMP learns temporal dynamics stochastically by reframing the MAE reconstruction loss as a conditional variational inference objective. We evaluated STAMP on two OCT and one MRI datasets with multiple visits per patient. STAMP pretrained ViT models outperformed both existing temporal MAE methods and foundation models on different late stage Age-Related Macular Degeneration and Alzheimer's Disease progression prediction which require models to learn the underlying non-deterministic temporal dynamics of the diseases.
Automatic detection and prediction of nAMD activity change in retinal OCT using Siamese networks and Wasserstein Distance for ordinality
Jan 24, 2025Neovascular age-related macular degeneration (nAMD) is a leading cause of vision loss among older adults, where disease activity detection and progression prediction are critical for nAMD management in terms of timely drug administration and improving patient outcomes. Recent advancements in deep learning offer a promising solution for predicting changes in AMD from optical coherence tomography (OCT) retinal volumes. In this work, we proposed deep learning models for the two tasks of the public MARIO Challenge at MICCAI 2024, designed to detect and forecast changes in nAMD severity with longitudinal retinal OCT. For the first task, we employ a Vision Transformer (ViT) based Siamese Network to detect changes in AMD severity by comparing scan embeddings of a patient from different time points. To train a model to forecast the change after 3 months, we exploit, for the first time, an Earth Mover (Wasserstein) Distance-based loss to harness the ordinal relation within the severity change classes. Both models ranked high on the preliminary leaderboard, demonstrating that their predictive capabilities could facilitate nAMD treatment management.
Forecasting Disease Progression with Parallel Hyperplanes in Longitudinal Retinal OCT
Sep 30, 2024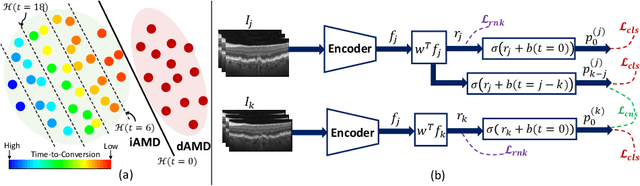
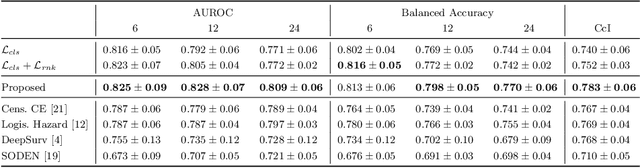
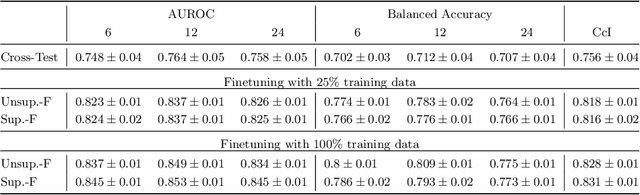
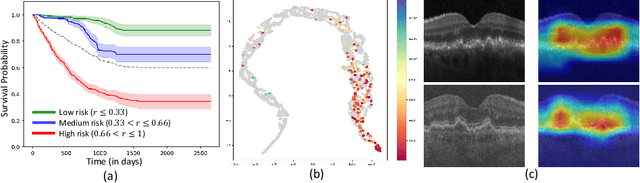
Predicting future disease progression risk from medical images is challenging due to patient heterogeneity, and subtle or unknown imaging biomarkers. Moreover, deep learning (DL) methods for survival analysis are susceptible to image domain shifts across scanners. We tackle these issues in the task of predicting late dry Age-related Macular Degeneration (dAMD) onset from retinal OCT scans. We propose a novel DL method for survival prediction to jointly predict from the current scan a risk score, inversely related to time-to-conversion, and the probability of conversion within a time interval $t$. It uses a family of parallel hyperplanes generated by parameterizing the bias term as a function of $t$. In addition, we develop unsupervised losses based on intra-subject image pairs to ensure that risk scores increase over time and that future conversion predictions are consistent with AMD stage prediction using actual scans of future visits. Such losses enable data-efficient fine-tuning of the trained model on new unlabeled datasets acquired with a different scanner. Extensive evaluation on two large datasets acquired with different scanners resulted in a mean AUROCs of 0.82 for Dataset-1 and 0.83 for Dataset-2, across prediction intervals of 6,12 and 24 months.
Time-Equivariant Contrastive Learning for Degenerative Disease Progression in Retinal OCT
May 15, 2024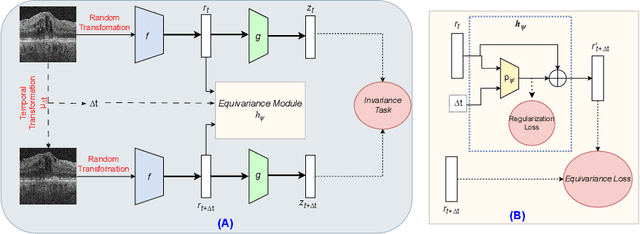
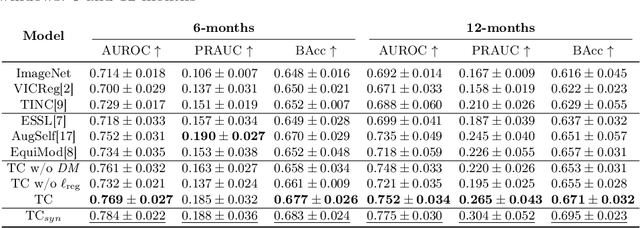
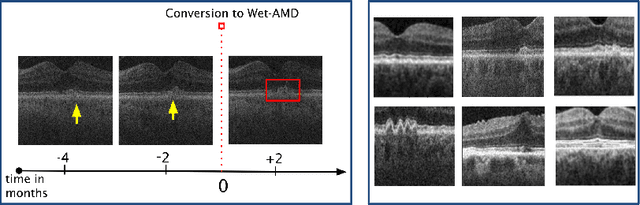
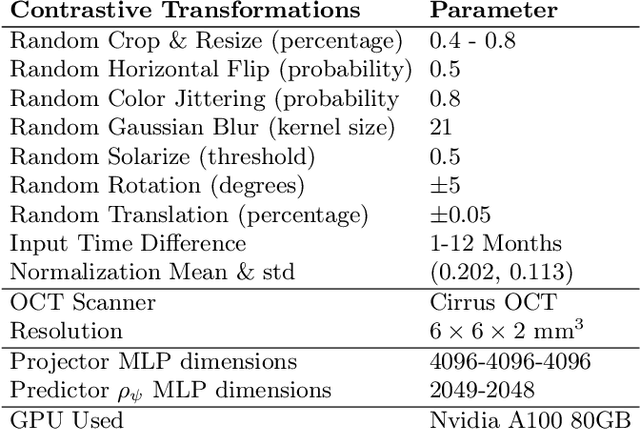
Contrastive pretraining provides robust representations by ensuring their invariance to different image transformations while simultaneously preventing representational collapse. Equivariant contrastive learning, on the other hand, provides representations sensitive to specific image transformations while remaining invariant to others. By introducing equivariance to time-induced transformations, such as disease-related anatomical changes in longitudinal imaging, the model can effectively capture such changes in the representation space. In this work, we pro-pose a Time-equivariant Contrastive Learning (TC) method. First, an encoder embeds two unlabeled scans from different time points of the same patient into the representation space. Next, a temporal equivariance module is trained to predict the representation of a later visit based on the representation from one of the previous visits and the corresponding time interval with a novel regularization loss term while preserving the invariance property to irrelevant image transformations. On a large longitudinal dataset, our model clearly outperforms existing equivariant contrastive methods in predicting progression from intermediate age-related macular degeneration (AMD) to advanced wet-AMD within a specified time-window.
3DTINC: Time-Equivariant Non-Contrastive Learning for Predicting Disease Progression from Longitudinal OCTs
Dec 28, 2023



Self-supervised learning (SSL) has emerged as a powerful technique for improving the efficiency and effectiveness of deep learning models. Contrastive methods are a prominent family of SSL that extract similar representations of two augmented views of an image while pushing away others in the representation space as negatives. However, the state-of-the-art contrastive methods require large batch sizes and augmentations designed for natural images that are impractical for 3D medical images. To address these limitations, we propose a new longitudinal SSL method, 3DTINC, based on non-contrastive learning. It is designed to learn perturbation-invariant features for 3D optical coherence tomography (OCT) volumes, using augmentations specifically designed for OCT. We introduce a new non-contrastive similarity loss term that learns temporal information implicitly from intra-patient scans acquired at different times. Our experiments show that this temporal information is crucial for predicting progression of retinal diseases, such as age-related macular degeneration (AMD). After pretraining with 3DTINC, we evaluated the learned representations and the prognostic models on two large-scale longitudinal datasets of retinal OCTs where we predict the conversion to wet-AMD within a six months interval. Our results demonstrate that each component of our contributions is crucial for learning meaningful representations useful in predicting disease progression from longitudinal volumetric scans.
SAMedOCT: Adapting Segment Anything Model (SAM) for Retinal OCT
Aug 31, 2023The Segment Anything Model (SAM) has gained significant attention in the field of image segmentation due to its impressive capabilities and prompt-based interface. While SAM has already been extensively evaluated in various domains, its adaptation to retinal OCT scans remains unexplored. To bridge this research gap, we conduct a comprehensive evaluation of SAM and its adaptations on a large-scale public dataset of OCTs from RETOUCH challenge. Our evaluation covers diverse retinal diseases, fluid compartments, and device vendors, comparing SAM against state-of-the-art retinal fluid segmentation methods. Through our analysis, we showcase adapted SAM's efficacy as a powerful segmentation model in retinal OCT scans, although still lagging behind established methods in some circumstances. The findings highlight SAM's adaptability and robustness, showcasing its utility as a valuable tool in retinal OCT image analysis and paving the way for further advancements in this domain.
Self-supervised learning via inter-modal reconstruction and feature projection networks for label-efficient 3D-to-2D segmentation
Jul 13, 2023Deep learning has become a valuable tool for the automation of certain medical image segmentation tasks, significantly relieving the workload of medical specialists. Some of these tasks require segmentation to be performed on a subset of the input dimensions, the most common case being 3D-to-2D. However, the performance of existing methods is strongly conditioned by the amount of labeled data available, as there is currently no data efficient method, e.g. transfer learning, that has been validated on these tasks. In this work, we propose a novel convolutional neural network (CNN) and self-supervised learning (SSL) method for label-efficient 3D-to-2D segmentation. The CNN is composed of a 3D encoder and a 2D decoder connected by novel 3D-to-2D blocks. The SSL method consists of reconstructing image pairs of modalities with different dimensionality. The approach has been validated in two tasks with clinical relevance: the en-face segmentation of geographic atrophy and reticular pseudodrusen in optical coherence tomography. Results on different datasets demonstrate that the proposed CNN significantly improves the state of the art in scenarios with limited labeled data by up to 8% in Dice score. Moreover, the proposed SSL method allows further improvement of this performance by up to 23%, and we show that the SSL is beneficial regardless of the network architecture.
Learning Spatio-Temporal Model of Disease Progression with NeuralODEs from Longitudinal Volumetric Data
Nov 08, 2022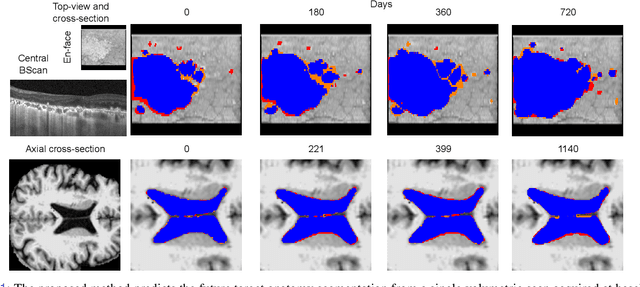
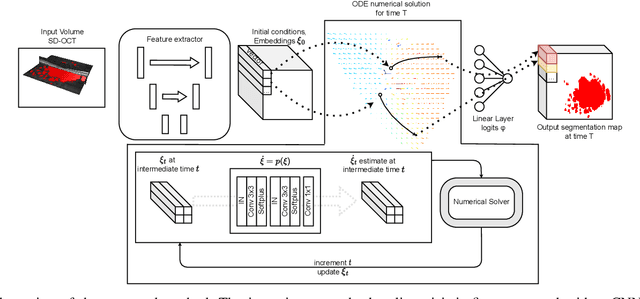
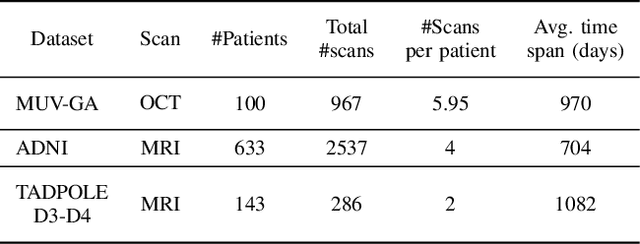

Robust forecasting of the future anatomical changes inflicted by an ongoing disease is an extremely challenging task that is out of grasp even for experienced healthcare professionals. Such a capability, however, is of great importance since it can improve patient management by providing information on the speed of disease progression already at the admission stage, or it can enrich the clinical trials with fast progressors and avoid the need for control arms by the means of digital twins. In this work, we develop a deep learning method that models the evolution of age-related disease by processing a single medical scan and providing a segmentation of the target anatomy at a requested future point in time. Our method represents a time-invariant physical process and solves a large-scale problem of modeling temporal pixel-level changes utilizing NeuralODEs. In addition, we demonstrate the approaches to incorporate the prior domain-specific constraints into our method and define temporal Dice loss for learning temporal objectives. To evaluate the applicability of our approach across different age-related diseases and imaging modalities, we developed and tested the proposed method on the datasets with 967 retinal OCT volumes of 100 patients with Geographic Atrophy, and 2823 brain MRI volumes of 633 patients with Alzheimer's Disease. For Geographic Atrophy, the proposed method outperformed the related baseline models in the atrophy growth prediction. For Alzheimer's Disease, the proposed method demonstrated remarkable performance in predicting the brain ventricle changes induced by the disease, achieving the state-of-the-art result on TADPOLE challenge.
Segmentation of Bruch's Membrane in retinal OCT with AMD using anatomical priors and uncertainty quantification
Oct 30, 2022Bruch's membrane (BM) segmentation on optical coherence tomography (OCT) is a pivotal step for the diagnosis and follow-up of age-related macular degeneration (AMD), one of the leading causes of blindness in the developed world. Automated BM segmentation methods exist, but they usually do not account for the anatomical coherence of the results, neither provide feedback on the confidence of the prediction. These factors limit the applicability of these systems in real-world scenarios. With this in mind, we propose an end-to-end deep learning method for automated BM segmentation in AMD patients. An Attention U-Net is trained to output a probability density function of the BM position, while taking into account the natural curvature of the surface. Besides the surface position, the method also estimates an A-scan wise uncertainty measure of the segmentation output. Subsequently, the A-scans with high uncertainty are interpolated using thin plate splines (TPS). We tested our method with ablation studies on an internal dataset with 138 patients covering all three AMD stages, and achieved a mean absolute localization error of 4.10 um. In addition, the proposed segmentation method was compared against the state-of-the-art methods and showed a superior performance on an external publicly available dataset from a different patient cohort and OCT device, demonstrating strong generalization ability.
SD-LayerNet: Semi-supervised retinal layer segmentation in OCT using disentangled representation with anatomical priors
Jul 01, 2022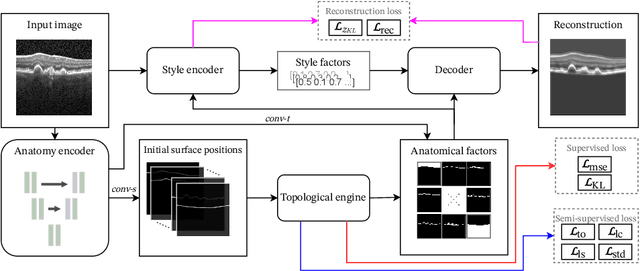
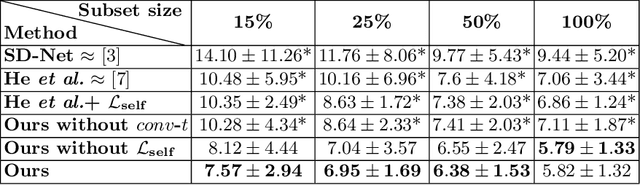
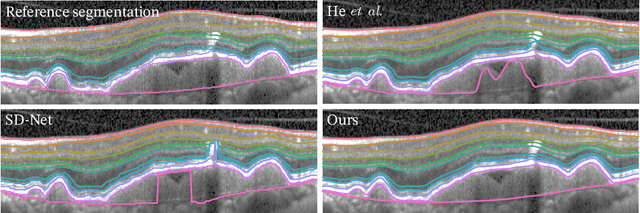

Optical coherence tomography (OCT) is a non-invasive 3D modality widely used in ophthalmology for imaging the retina. Achieving automated, anatomically coherent retinal layer segmentation on OCT is important for the detection and monitoring of different retinal diseases, like Age-related Macular Disease (AMD) or Diabetic Retinopathy. However, the majority of state-of-the-art layer segmentation methods are based on purely supervised deep-learning, requiring a large amount of pixel-level annotated data that is expensive and hard to obtain. With this in mind, we introduce a semi-supervised paradigm into the retinal layer segmentation task that makes use of the information present in large-scale unlabeled datasets as well as anatomical priors. In particular, a novel fully differentiable approach is used for converting surface position regression into a pixel-wise structured segmentation, allowing to use both 1D surface and 2D layer representations in a coupled fashion to train the model. In particular, these 2D segmentations are used as anatomical factors that, together with learned style factors, compose disentangled representations used for reconstructing the input image. In parallel, we propose a set of anatomical priors to improve network training when a limited amount of labeled data is available. We demonstrate on the real-world dataset of scans with intermediate and wet-AMD that our method outperforms state-of-the-art when using our full training set, but more importantly largely exceeds state-of-the-art when it is trained with a fraction of the labeled data.