 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProjective Skip-Connections for Segmentation Along a Subset of Dimensions in Retinal OCT
Aug 02, 2021
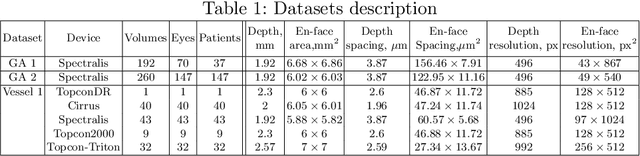
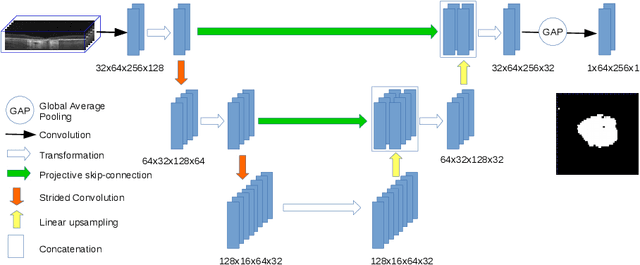
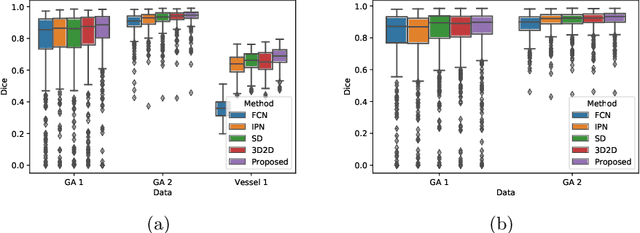
In medical imaging, there are clinically relevant segmentation tasks where the output mask is a projection to a subset of input image dimensions. In this work, we propose a novel convolutional neural network architecture that can effectively learn to produce a lower-dimensional segmentation mask than the input image. The network restores encoded representation only in a subset of input spatial dimensions and keeps the representation unchanged in the others. The newly proposed projective skip-connections allow linking the encoder and decoder in a UNet-like structure. We evaluated the proposed method on two clinically relevant tasks in retinal Optical Coherence Tomography (OCT): geographic atrophy and retinal blood vessel segmentation. The proposed method outperformed the current state-of-the-art approaches on all the OCT datasets used, consisting of 3D volumes and corresponding 2D en-face masks. The proposed architecture fills the methodological gap between image classification and ND image segmentation.