 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Siamese MAE Pretraining for Longitudinal Medical Images
Dec 29, 2025Temporally aware image representations are crucial for capturing disease progression in 3D volumes of longitudinal medical datasets. However, recent state-of-the-art self-supervised learning approaches like Masked Autoencoding (MAE), despite their strong representation learning capabilities, lack temporal awareness. In this paper, we propose STAMP (Stochastic Temporal Autoencoder with Masked Pretraining), a Siamese MAE framework that encodes temporal information through a stochastic process by conditioning on the time difference between the 2 input volumes. Unlike deterministic Siamese approaches, which compare scans from different time points but fail to account for the inherent uncertainty in disease evolution, STAMP learns temporal dynamics stochastically by reframing the MAE reconstruction loss as a conditional variational inference objective. We evaluated STAMP on two OCT and one MRI datasets with multiple visits per patient. STAMP pretrained ViT models outperformed both existing temporal MAE methods and foundation models on different late stage Age-Related Macular Degeneration and Alzheimer's Disease progression prediction which require models to learn the underlying non-deterministic temporal dynamics of the diseases.
A graph neural network-based multispectral-view learning model for diabetic macular ischemia detection from color fundus photographs
Feb 25, 2025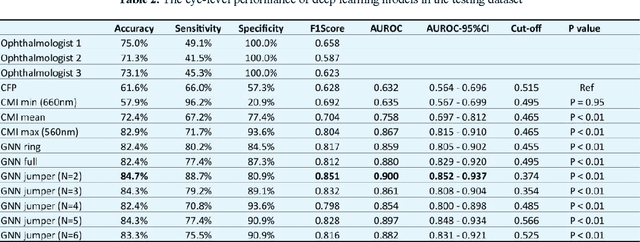

Diabetic macular ischemia (DMI), marked by the loss of retinal capillaries in the macular area, contributes to vision impairment in patients with diabetes. Although color fundus photographs (CFPs), combined with artificial intelligence (AI), have been extensively applied in detecting various eye diseases, including diabetic retinopathy (DR), their applications in detecting DMI remain unexplored, partly due to skepticism among ophthalmologists regarding its feasibility. In this study, we propose a graph neural network-based multispectral view learning (GNN-MSVL) model designed to detect DMI from CFPs. The model leverages higher spectral resolution to capture subtle changes in fundus reflectance caused by ischemic tissue, enhancing sensitivity to DMI-related features. The proposed approach begins with computational multispectral imaging (CMI) to reconstruct 24-wavelength multispectral fundus images from CFPs. ResNeXt101 is employed as the backbone for multi-view learning to extract features from the reconstructed images. Additionally, a GNN with a customized jumper connection strategy is designed to enhance cross-spectral relationships, facilitating comprehensive and efficient multispectral view learning. The study included a total of 1,078 macula-centered CFPs from 1,078 eyes of 592 patients with diabetes, of which 530 CFPs from 530 eyes of 300 patients were diagnosed with DMI. The model achieved an accuracy of 84.7 percent and an area under the receiver operating characteristic curve (AUROC) of 0.900 (95 percent CI: 0.852-0.937) on eye-level, outperforming both the baseline model trained from CFPs and human experts (p-values less than 0.01). These findings suggest that AI-based CFP analysis holds promise for detecting DMI, contributing to its early and low-cost screening.
Forecasting Disease Progression with Parallel Hyperplanes in Longitudinal Retinal OCT
Sep 30, 2024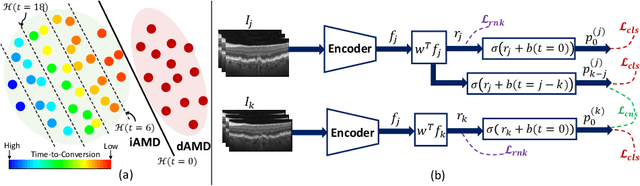
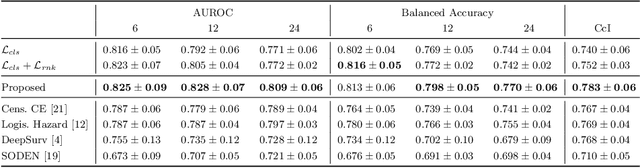
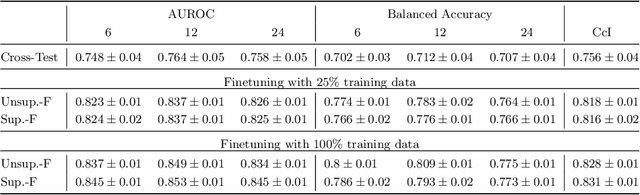
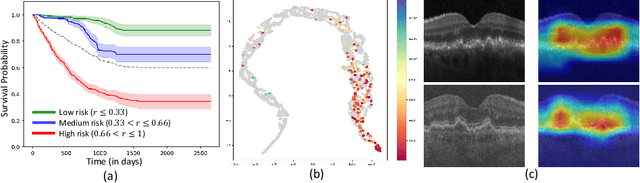
Predicting future disease progression risk from medical images is challenging due to patient heterogeneity, and subtle or unknown imaging biomarkers. Moreover, deep learning (DL) methods for survival analysis are susceptible to image domain shifts across scanners. We tackle these issues in the task of predicting late dry Age-related Macular Degeneration (dAMD) onset from retinal OCT scans. We propose a novel DL method for survival prediction to jointly predict from the current scan a risk score, inversely related to time-to-conversion, and the probability of conversion within a time interval $t$. It uses a family of parallel hyperplanes generated by parameterizing the bias term as a function of $t$. In addition, we develop unsupervised losses based on intra-subject image pairs to ensure that risk scores increase over time and that future conversion predictions are consistent with AMD stage prediction using actual scans of future visits. Such losses enable data-efficient fine-tuning of the trained model on new unlabeled datasets acquired with a different scanner. Extensive evaluation on two large datasets acquired with different scanners resulted in a mean AUROCs of 0.82 for Dataset-1 and 0.83 for Dataset-2, across prediction intervals of 6,12 and 24 months.
Specialist vision-language models for clinical ophthalmology
Jul 11, 2024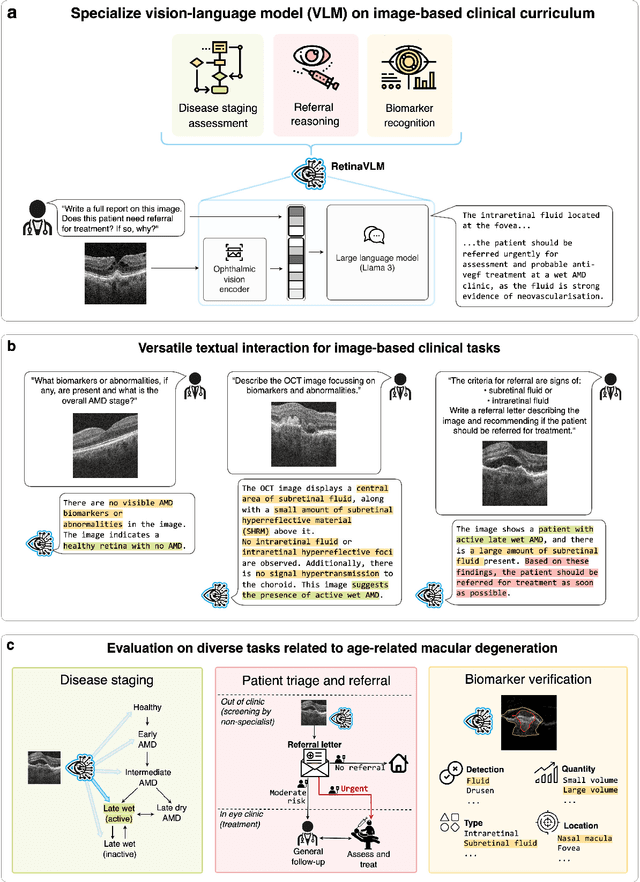

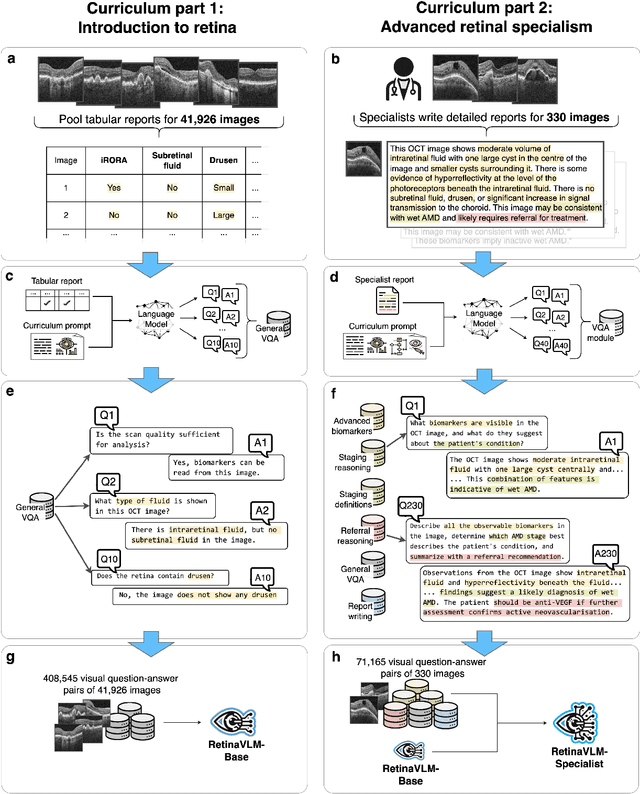

Clinicians spend a significant amount of time reviewing medical images and transcribing their findings regarding patient diagnosis, referral and treatment in text form. Vision-language models (VLMs), which automatically interpret images and summarize their findings as text, have enormous potential to alleviate clinical workloads and increase patient access to high-quality medical care. While foundational models have stirred considerable interest in the medical community, it is unclear whether their general capabilities translate to real-world clinical utility. In this work, we show that foundation VLMs markedly underperform compared to practicing ophthalmologists on specialist tasks crucial to the care of patients with age-related macular degeneration (AMD). To address this, we initially identified the essential capabilities required for image-based clinical decision-making, and then developed a curriculum to selectively train VLMs in these skills. The resulting model, RetinaVLM, can be instructed to write reports that significantly outperform those written by leading foundation medical VLMs in disease staging (F1 score of 0.63 vs. 0.11) and patient referral (0.67 vs. 0.39), and approaches the diagnostic performance of junior ophthalmologists (who achieve 0.77 and 0.78 on the respective tasks). Furthermore, in a reader study involving two senior ophthalmologists with up to 32 years of experience, RetinaVLM's reports were found to be similarly correct (78.6% vs. 82.1%) and complete (both 78.6%) as reports written by junior ophthalmologists with up to 10 years of experience. These results demonstrate that our curriculum-based approach provides a blueprint for specializing generalist foundation medical VLMs to handle real-world clinical tasks.
Spatiotemporal Representation Learning for Short and Long Medical Image Time Series
Mar 12, 2024Analyzing temporal developments is crucial for the accurate prognosis of many medical conditions. Temporal changes that occur over short time scales are key to assessing the health of physiological functions, such as the cardiac cycle. Moreover, tracking longer term developments that occur over months or years in evolving processes, such as age-related macular degeneration (AMD), is essential for accurate prognosis. Despite the importance of both short and long term analysis to clinical decision making, they remain understudied in medical deep learning. State of the art methods for spatiotemporal representation learning, developed for short natural videos, prioritize the detection of temporal constants rather than temporal developments. Moreover, they do not account for varying time intervals between acquisitions, which are essential for contextualizing observed changes. To address these issues, we propose two approaches. First, we combine clip-level contrastive learning with a novel temporal embedding to adapt to irregular time series. Second, we propose masking and predicting latent frame representations of the temporal sequence. Our two approaches outperform all prior methods on temporally-dependent tasks including cardiac output estimation and three prognostic AMD tasks. Overall, this enables the automated analysis of temporal patterns which are typically overlooked in applications of deep learning to medicine.
3DTINC: Time-Equivariant Non-Contrastive Learning for Predicting Disease Progression from Longitudinal OCTs
Dec 28, 2023



Self-supervised learning (SSL) has emerged as a powerful technique for improving the efficiency and effectiveness of deep learning models. Contrastive methods are a prominent family of SSL that extract similar representations of two augmented views of an image while pushing away others in the representation space as negatives. However, the state-of-the-art contrastive methods require large batch sizes and augmentations designed for natural images that are impractical for 3D medical images. To address these limitations, we propose a new longitudinal SSL method, 3DTINC, based on non-contrastive learning. It is designed to learn perturbation-invariant features for 3D optical coherence tomography (OCT) volumes, using augmentations specifically designed for OCT. We introduce a new non-contrastive similarity loss term that learns temporal information implicitly from intra-patient scans acquired at different times. Our experiments show that this temporal information is crucial for predicting progression of retinal diseases, such as age-related macular degeneration (AMD). After pretraining with 3DTINC, we evaluated the learned representations and the prognostic models on two large-scale longitudinal datasets of retinal OCTs where we predict the conversion to wet-AMD within a six months interval. Our results demonstrate that each component of our contributions is crucial for learning meaningful representations useful in predicting disease progression from longitudinal volumetric scans.
Pretrained Deep 2.5D Models for Efficient Predictive Modeling from Retinal OCT
Jul 25, 2023In the field of medical imaging, 3D deep learning models play a crucial role in building powerful predictive models of disease progression. However, the size of these models presents significant challenges, both in terms of computational resources and data requirements. Moreover, achieving high-quality pretraining of 3D models proves to be even more challenging. To address these issues, hybrid 2.5D approaches provide an effective solution for utilizing 3D volumetric data efficiently using 2D models. Combining 2D and 3D techniques offers a promising avenue for optimizing performance while minimizing memory requirements. In this paper, we explore 2.5D architectures based on a combination of convolutional neural networks (CNNs), long short-term memory (LSTM), and Transformers. In addition, leveraging the benefits of recent non-contrastive pretraining approaches in 2D, we enhanced the performance and data efficiency of 2.5D techniques even further. We demonstrate the effectiveness of architectures and associated pretraining on a task of predicting progression to wet age-related macular degeneration (AMD) within a six-month period on two large longitudinal OCT datasets.
Detailed retinal vessel segmentation without human annotations using simulated optical coherence tomography angiographs
Jun 19, 2023Optical coherence tomography angiography (OCTA) is a non-invasive imaging modality that can acquire high-resolution volumes of the retinal vasculature and aid the diagnosis of ocular, neurological and cardiac diseases. Segmentation of the visible blood vessels is a common first step when extracting quantitative biomarkers from these images. Classical segmentation algorithms based on thresholding are strongly affected by image artifacts and limited signal-to-noise ratio. The use of modern, deep learning-based segmentation methods has been inhibited by a lack of large datasets with detailed annotations of the blood vessels. To address this issue, recent work has employed transfer learning, where a segmentation network is trained on synthetic OCTA images and is then applied to real data. However, the previously proposed simulation models are incapable of faithfully modeling the retinal vasculature and do not provide effective domain adaptation. Because of this, current methods are not able to fully segment the retinal vasculature, in particular the smallest capillaries. In this work, we present a lightweight simulation of the retinal vascular network based on space colonization for faster and more realistic OCTA synthesis. Moreover, we introduce three contrast adaptation pipelines to decrease the domain gap between real and artificial images. We demonstrate the superior performance of our approach in extensive quantitative and qualitative experiments on three public datasets that compare our method to traditional computer vision algorithms and supervised training using human annotations. Finally, we make our entire pipeline publicly available, including the source code, pretrained models, and a large dataset of synthetic OCTA images.
Morph-SSL: Self-Supervision with Longitudinal Morphing to Predict AMD Progression from OCT
Apr 17, 2023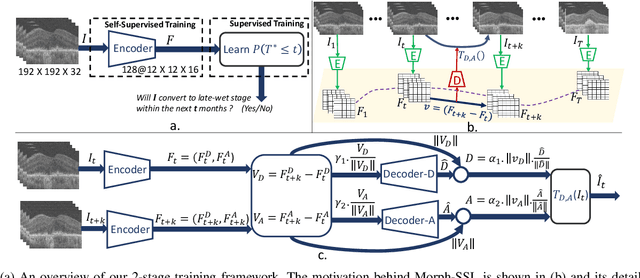
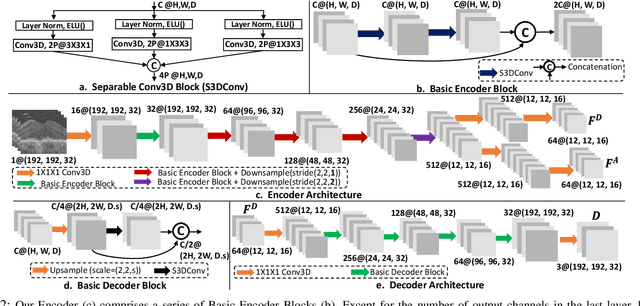

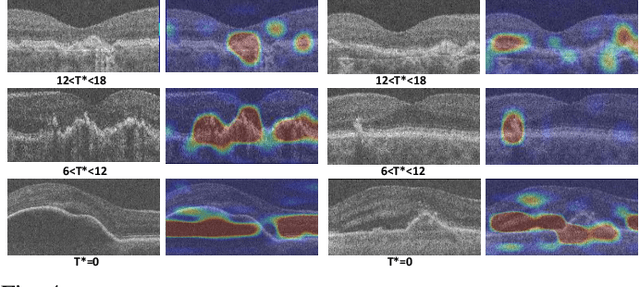
The lack of reliable biomarkers makes predicting the conversion from intermediate to neovascular age-related macular degeneration (iAMD, nAMD) a challenging task. We develop a Deep Learning (DL) model to predict the future risk of conversion of an eye from iAMD to nAMD from its current OCT scan. Although eye clinics generate vast amounts of longitudinal OCT scans to monitor AMD progression, only a small subset can be manually labeled for supervised DL. To address this issue, we propose Morph-SSL, a novel Self-supervised Learning (SSL) method for longitudinal data. It uses pairs of unlabelled OCT scans from different visits and involves morphing the scan from the previous visit to the next. The Decoder predicts the transformation for morphing and ensures a smooth feature manifold that can generate intermediate scans between visits through linear interpolation. Next, the Morph-SSL trained features are input to a Classifier which is trained in a supervised manner to model the cumulative probability distribution of the time to conversion with a sigmoidal function. Morph-SSL was trained on unlabelled scans of 399 eyes (3570 visits). The Classifier was evaluated with a five-fold cross-validation on 2418 scans from 343 eyes with clinical labels of the conversion date. The Morph-SSL features achieved an AUC of 0.766 in predicting the conversion to nAMD within the next 6 months, outperforming the same network when trained end-to-end from scratch or pre-trained with popular SSL methods. Automated prediction of the future risk of nAMD onset can enable timely treatment and individualized AMD management.
Clustering disease trajectories in contrastive feature space for biomarker discovery in age-related macular degeneration
Jan 11, 2023Age-related macular degeneration (AMD) is the leading cause of blindness in the elderly. Despite this, the exact dynamics of disease progression are poorly understood. There is a clear need for imaging biomarkers in retinal optical coherence tomography (OCT) that aid the diagnosis, prognosis and management of AMD. However, current grading systems, which coarsely group disease stage into broad categories describing early and intermediate AMD, have very limited prognostic value for the conversion to late AMD. In this paper, we are the first to analyse disease progression as clustered trajectories in a self-supervised feature space. Our method first pretrains an encoder with contrastive learning to project images from longitudinal time series to points in feature space. This enables the creation of disease trajectories, which are then denoised, partitioned and grouped into clusters. These clusters, found in two datasets containing time series of 7,912 patients imaged over eight years, were correlated with known OCT biomarkers. This reinforced efforts by four expert ophthalmologists to investigate clusters, during a clinical comparison and interpretation task, as candidates for time-dependent biomarkers that describe progression of AMD.