 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetadata-enhanced contrastive learning from retinal optical coherence tomography images
Aug 04, 2022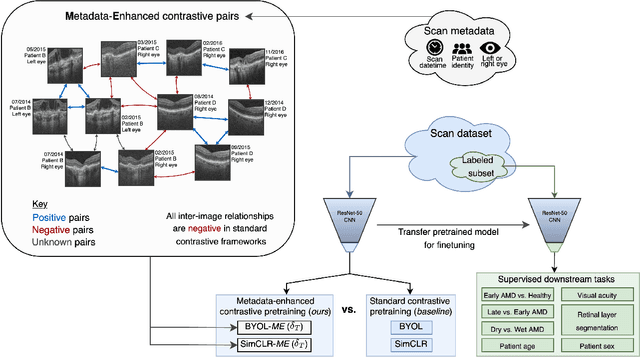
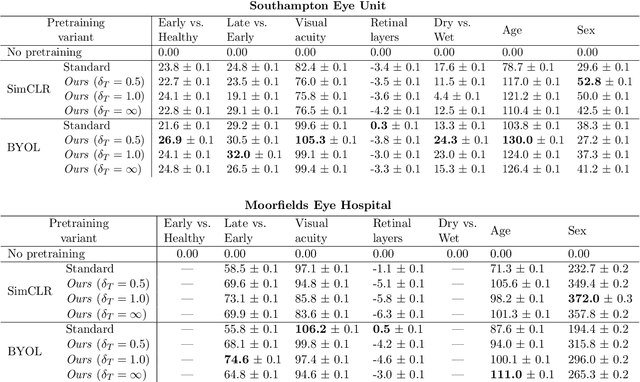
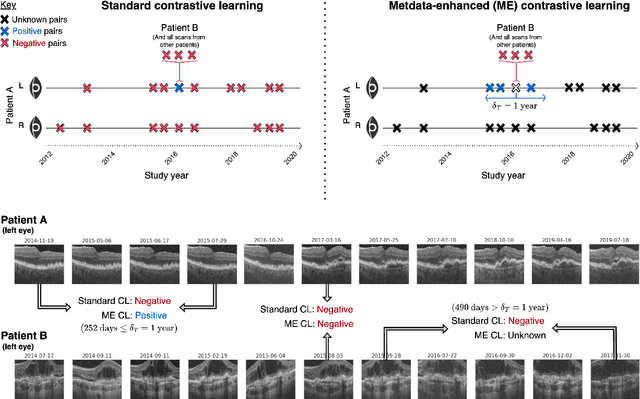
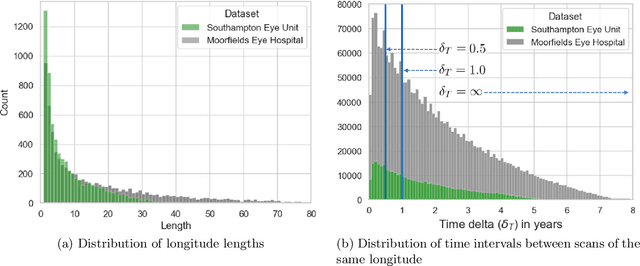
Supervised deep learning algorithms hold great potential to automate screening, monitoring and grading of medical images. However, training performant models has typically required vast quantities of labelled data, which is scarcely available in the medical domain. Self-supervised contrastive frameworks relax this dependency by first learning from unlabelled images. In this work we show that pretraining with two contrastive methods, SimCLR and BYOL, improves the utility of deep learning with regard to the clinical assessment of age-related macular degeneration (AMD). In experiments using two large clinical datasets containing 170,427 optical coherence tomography (OCT) images of 7,912 patients, we evaluate benefits attributed to pretraining across seven downstream tasks ranging from AMD stage and type classification to prediction of functional endpoints to segmentation of retinal layers, finding performance significantly increased in six out of seven tasks with fewer labels. However, standard contrastive frameworks have two known weaknesses that are detrimental to pretraining in the medical domain. Several of the image transformations used to create positive contrastive pairs are not applicable to greyscale medical scans. Furthermore, medical images often depict the same anatomical region and disease severity, resulting in numerous misleading negative pairs. To address these issues we develop a novel metadata-enhanced approach that exploits the rich set of inherently available patient information. To this end we employ records for patient identity, eye position (i.e. left or right) and time series data to indicate the typically unknowable set of inter-image contrastive relationships. By leveraging this often neglected information our metadata-enhanced contrastive pretraining leads to further benefits and outperforms conventional contrastive methods in five out of seven downstream tasks.