 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Big, Generate Quick: LLM-to-SLM for Fast Autoregressive Decoding
Paper and Code
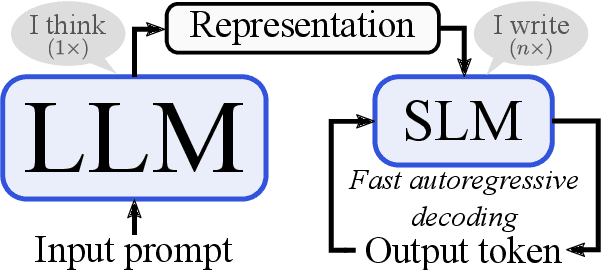
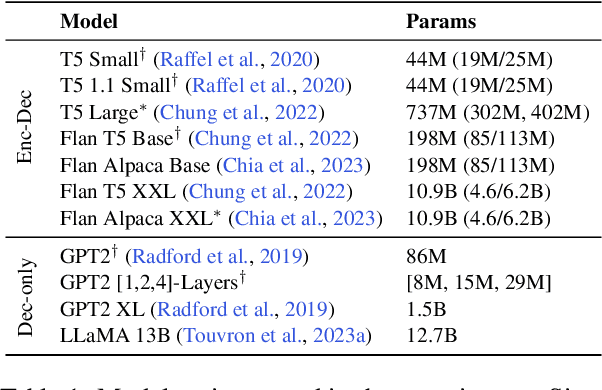
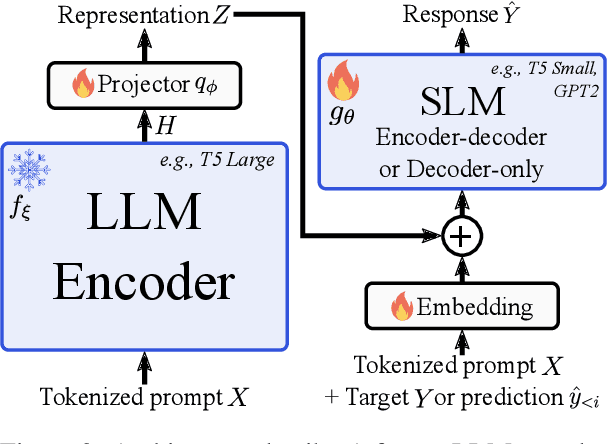
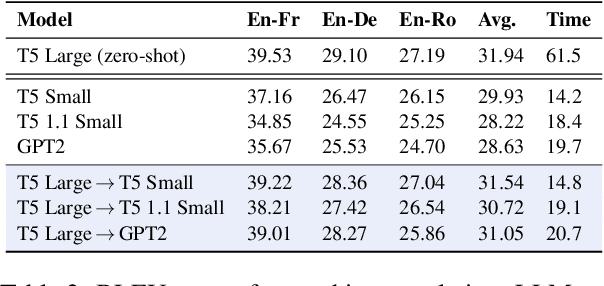
Large language models (LLMs) have become ubiquitous in practice and are widely used for generation tasks such as translation, summarization and instruction following. However, their enormous size and reliance on autoregressive decoding increase deployment costs and complicate their use in latency-critical applications. In this work, we propose a hybrid approach that combines language models of different sizes to increase the efficiency of autoregressive decoding while maintaining high performance. Our method utilizes a pretrained frozen LLM that encodes all prompt tokens once in parallel, and uses the resulting representations to condition and guide a small language model (SLM), which then generates the response more efficiently. We investigate the combination of encoder-decoder LLMs with both encoder-decoder and decoder-only SLMs from different model families and only require fine-tuning of the SLM. Experiments with various benchmarks show substantial speedups of up to $4\times$, with minor performance penalties of $1-2\%$ for translation and summarization tasks compared to the LLM.