 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Bayesian Imitation Learning with Logic over Programs
Paper and Code
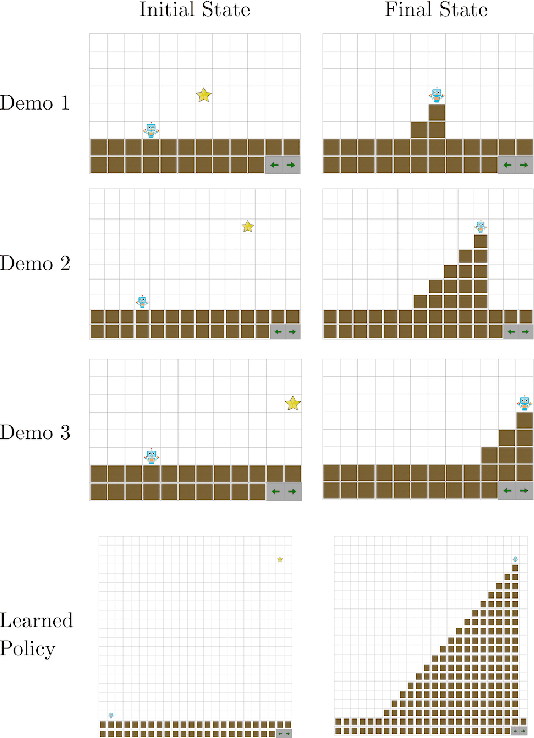



We describe an expressive class of policies that can be efficiently learned from a few demonstrations. Policies are represented as logical combinations of programs drawn from a small domain-specific language (DSL). We define a prior over policies with a probabilistic grammar and derive an approximate Bayesian inference algorithm to learn policies from demonstrations. In experiments, we study five strategy games played on a 2D grid with one shared DSL. After a few demonstrations of each game, the inferred policies generalize to new game instances that differ substantially from the demonstrations. We argue that the proposed method is an apt choice for policy learning tasks that have scarce training data and feature significant, structured variation between task instances.