 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfinite Mixture Prototypes for Few-Shot Learning
Feb 12, 2019



We propose infinite mixture prototypes to adaptively represent both simple and complex data distributions for few-shot learning. Our infinite mixture prototypes represent each class by a set of clusters, unlike existing prototypical methods that represent each class by a single cluster. By inferring the number of clusters, infinite mixture prototypes interpolate between nearest neighbor and prototypical representations, which improves accuracy and robustness in the few-shot regime. We show the importance of adaptive capacity for capturing complex data distributions such as alphabets, with 25% absolute accuracy improvements over prototypical networks, while still maintaining or improving accuracy on the standard Omniglot and mini-ImageNet benchmarks. In clustering labeled and unlabeled data by the same clustering rule, infinite mixture prototypes achieves state-of-the-art semi-supervised accuracy. As a further capability, we show that infinite mixture prototypes can perform purely unsupervised clustering, unlike existing prototypical methods.
Continual Learning with Deep Generative Replay
Dec 12, 2017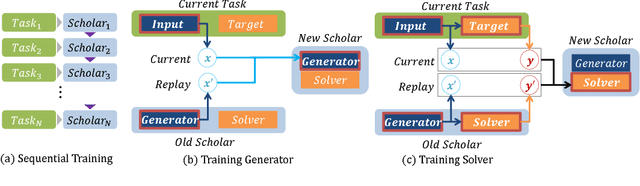
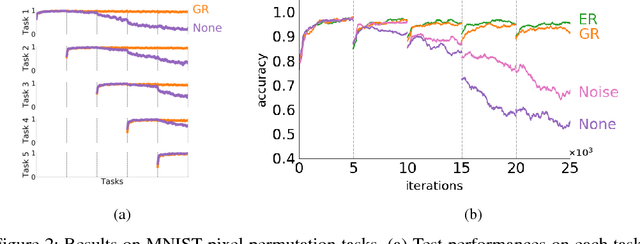
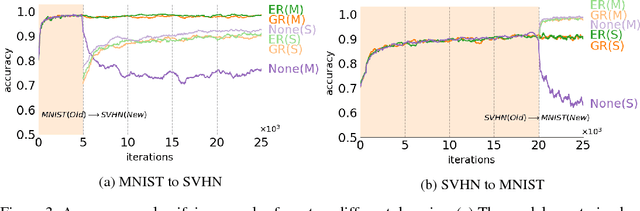
Attempts to train a comprehensive artificial intelligence capable of solving multiple tasks have been impeded by a chronic problem called catastrophic forgetting. Although simply replaying all previous data alleviates the problem, it requires large memory and even worse, often infeasible in real world applications where the access to past data is limited. Inspired by the generative nature of hippocampus as a short-term memory system in primate brain, we propose the Deep Generative Replay, a novel framework with a cooperative dual model architecture consisting of a deep generative model ("generator") and a task solving model ("solver"). With only these two models, training data for previous tasks can easily be sampled and interleaved with those for a new task. We test our methods in several sequential learning settings involving image classification tasks.