 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFighting Sampling Bias: A Framework for Training and Evaluating Credit Scoring Models
Jul 17, 2024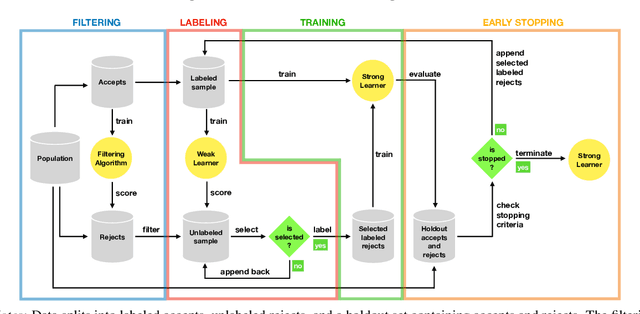

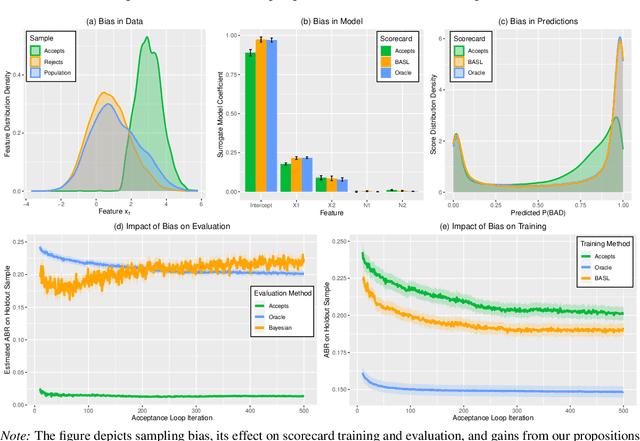
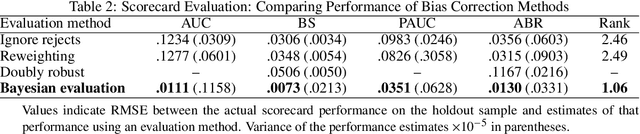
Scoring models support decision-making in financial institutions. Their estimation and evaluation are based on the data of previously accepted applicants with known repayment behavior. This creates sampling bias: the available labeled data offers a partial picture of the distribution of candidate borrowers, which the model is supposed to score. The paper addresses the adverse effect of sampling bias on model training and evaluation. To improve scorecard training, we propose bias-aware self-learning - a reject inference framework that augments the biased training data by inferring labels for selected rejected applications. For scorecard evaluation, we propose a Bayesian framework that extends standard accuracy measures to the biased setting and provides a reliable estimate of future scorecard performance. Extensive experiments on synthetic and real-world data confirm the superiority of our propositions over various benchmarks in predictive performance and profitability. By sensitivity analysis, we also identify boundary conditions affecting their performance. Notably, we leverage real-world data from a randomized controlled trial to assess the novel methodologies on holdout data that represent the true borrower population. Our findings confirm that reject inference is a difficult problem with modest potential to improve scorecard performance. Addressing sampling bias during scorecard evaluation is a much more promising route to improve scoring practices. For example, our results suggest a profit improvement of about eight percent, when using Bayesian evaluation to decide on acceptance rates.
Shallow Self-Learning for Reject Inference in Credit Scoring
Sep 13, 2019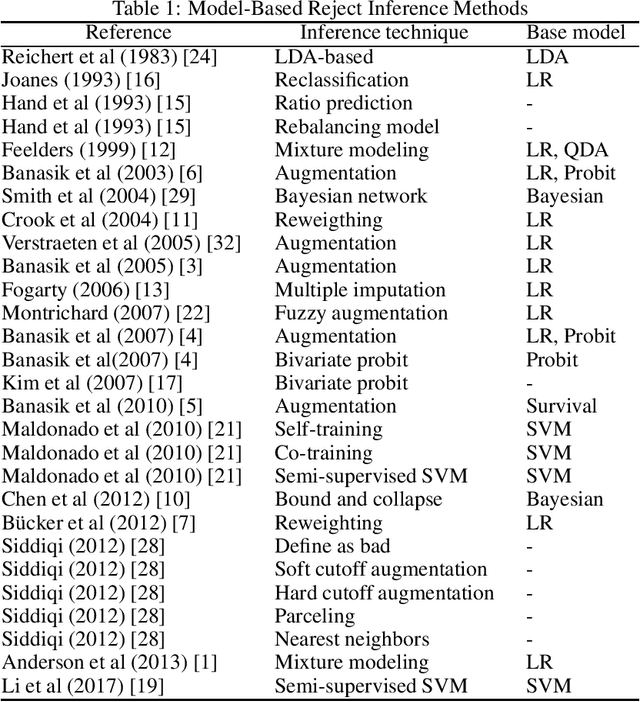



Credit scoring models support loan approval decisions in the financial services industry. Lenders train these models on data from previously granted credit applications, where the borrowers' repayment behavior has been observed. This approach creates sample bias. The scoring model (i.e., classifier) is trained on accepted cases only. Applying the resulting model to screen credit applications from the population of all borrowers degrades model performance. Reject inference comprises techniques to overcome sampling bias through assigning labels to rejected cases. The paper makes two contributions. First, we propose a self-learning framework for reject inference. The framework is geared toward real-world credit scoring requirements through considering distinct training regimes for iterative labeling and model training. Second, we introduce a new measure to assess the effectiveness of reject inference strategies. Our measure leverages domain knowledge to avoid artificial labeling of rejected cases during strategy evaluation. We demonstrate this approach to offer a robust and operational assessment of reject inference strategies. Experiments on a real-world credit scoring data set confirm the superiority of the adjusted self-learning framework over regular self-learning and previous reject inference strategies. We also find strong evidence in favor of the proposed evaluation measure assessing reject inference strategies more reliably, raising the performance of the eventual credit scoring model.
MetaBags: Bagged Meta-Decision Trees for Regression
Apr 17, 2018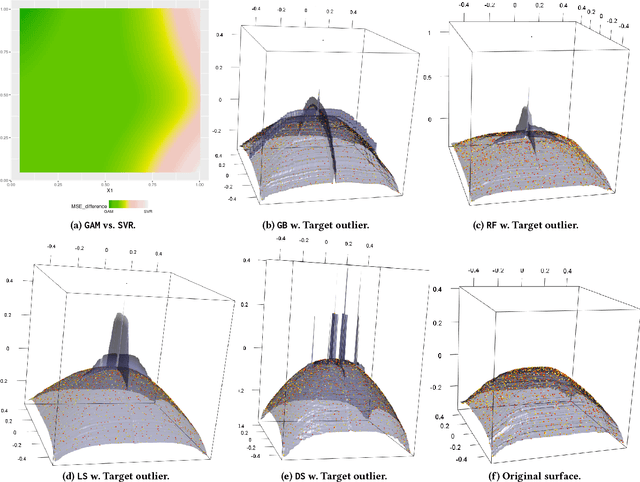
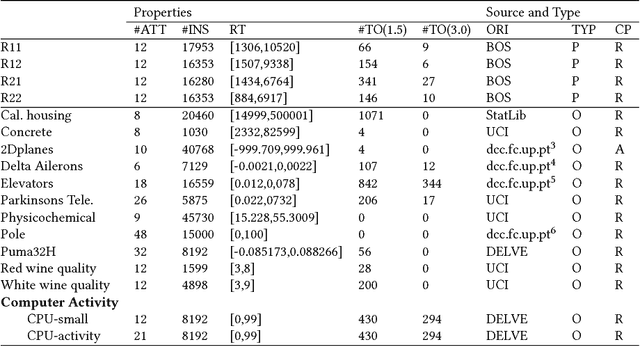
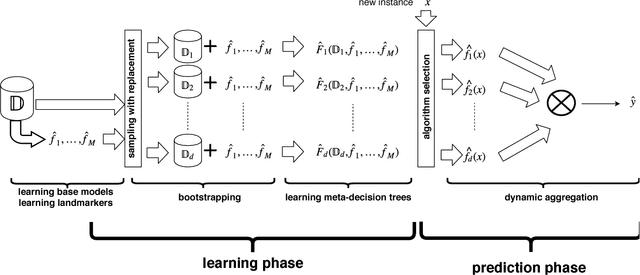

Ensembles are popular methods for solving practical supervised learning problems. They reduce the risk of having underperforming models in production-grade software. Although critical, methods for learning heterogeneous regression ensembles have not been proposed at large scale, whereas in classical ML literature, stacking, cascading and voting are mostly restricted to classification problems. Regression poses distinct learning challenges that may result in poor performance, even when using well established homogeneous ensemble schemas such as bagging or boosting. In this paper, we introduce MetaBags, a novel, practically useful stacking framework for regression. MetaBags is a meta-learning algorithm that learns a set of meta-decision trees designed to select one base model (i.e. expert) for each query, and focuses on inductive bias reduction. A set of meta-decision trees are learned using different types of meta-features, specially created for this purpose - to then be bagged at meta-level. This procedure is designed to learn a model with a fair bias-variance trade-off, and its improvement over base model performance is correlated with the prediction diversity of different experts on specific input space subregions. The proposed method and meta-features are designed in such a way that they enable good predictive performance even in subregions of space which are not adequately represented in the available training data. An exhaustive empirical testing of the method was performed, evaluating both generalization error and scalability of the approach on synthetic, open and real-world application datasets. The obtained results show that our method significantly outperforms existing state-of-the-art approaches.
Robust Continuous Co-Clustering
Feb 14, 2018

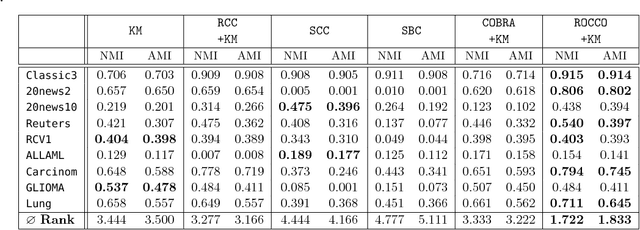

Clustering consists of grouping together samples giving their similar properties. The problem of modeling simultaneously groups of samples and features is known as Co-Clustering. This paper introduces ROCCO - a Robust Continuous Co-Clustering algorithm. ROCCO is a scalable, hyperparameter-free, easy and ready to use algorithm to address Co-Clustering problems in practice over massive cross-domain datasets. It operates by learning a graph-based two-sided representation of the input matrix. The underlying proposed optimization problem is non-convex, which assures a flexible pool of solutions. Moreover, we prove that it can be solved with a near linear time complexity on the input size. An exhaustive large-scale experimental testbed conducted with both synthetic and real-world datasets demonstrates ROCCO's properties in practice: (i) State-of-the-art performance in cross-domain real-world problems including Biomedicine and Text Mining; (ii) very low sensitivity to hyperparameter settings; (iii) robustness to noise and (iv) a linear empirical scalability in practice. These results highlight ROCCO as a powerful general-purpose co-clustering algorithm for cross-domain practitioners, regardless of their technical background.