 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Vehicle Energy Efficiency Prediction using an Ensemble of Neural Networks
May 02, 2023The transportation sector accounts for about 25% of global greenhouse gas emissions. Therefore, an improvement of energy efficiency in the traffic sector is crucial to reducing the carbon footprint. Efficiency is typically measured in terms of energy use per traveled distance, e.g. liters of fuel per kilometer. Leading factors that impact the energy efficiency are the type of vehicle, environment, driver behavior, and weather conditions. These varying factors introduce uncertainty in estimating the vehicles' energy efficiency. We propose in this paper an ensemble learning approach based on deep neural networks (ENN) that is designed to reduce the predictive uncertainty and to output measures of such uncertainty. We evaluated it using the publicly available Vehicle Energy Dataset (VED) and compared it with several baselines per vehicle and energy type. The results showed a high predictive performance and they allowed to output a measure of predictive uncertainty.
Uncertainty-Aware Prediction of Battery Energy Consumption for Hybrid Electric Vehicles
Apr 27, 2022
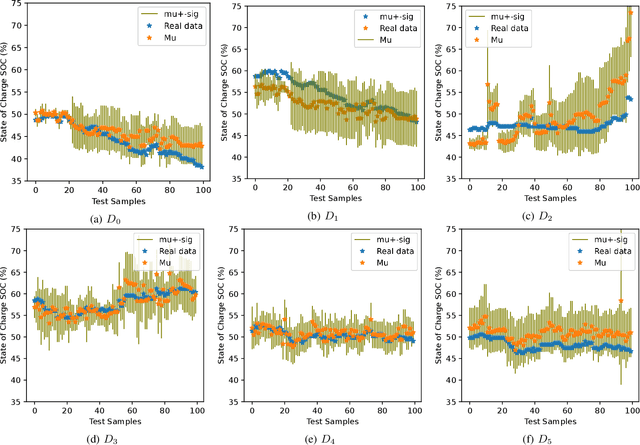
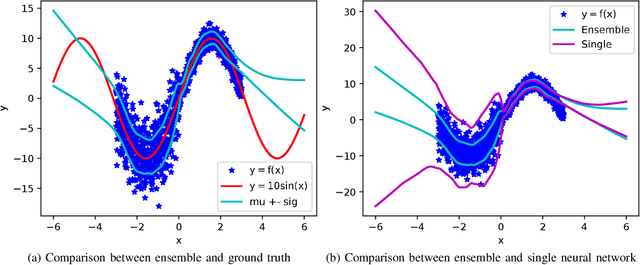
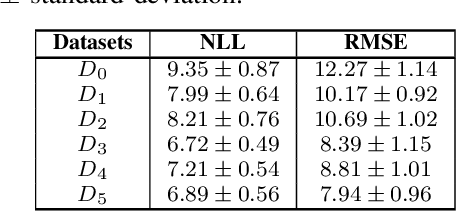
The usability of vehicles is highly dependent on their energy consumption. In particular, one of the main factors hindering the mass adoption of electric (EV), hybrid (HEV), and plug-in hybrid (PHEV) vehicles is range anxiety, which occurs when a driver is uncertain about the availability of energy for a given trip. To tackle this problem, we propose a machine learning approach for modeling the battery energy consumption. By reducing predictive uncertainty, this method can help increase trust in the vehicle's performance and thus boost its usability. Most related work focuses on physical and/or chemical models of the battery that affect the energy consumption. We propose a data-driven approach which relies on real-world datasets including battery related attributes. Our approach showed an improvement in terms of predictive uncertainty as well as in accuracy compared to traditional methods.
Boosting Algorithms for Delivery Time Prediction in Transportation Logistics
Sep 24, 2020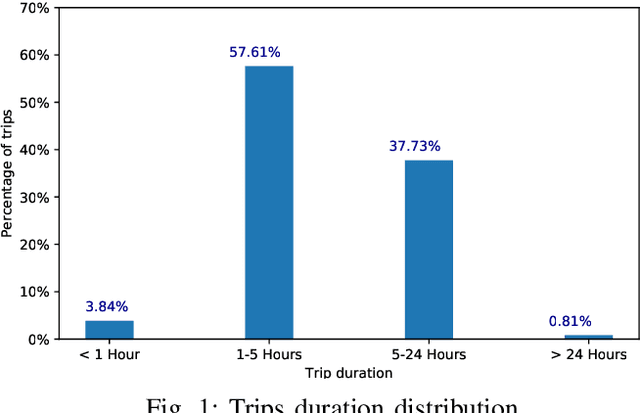
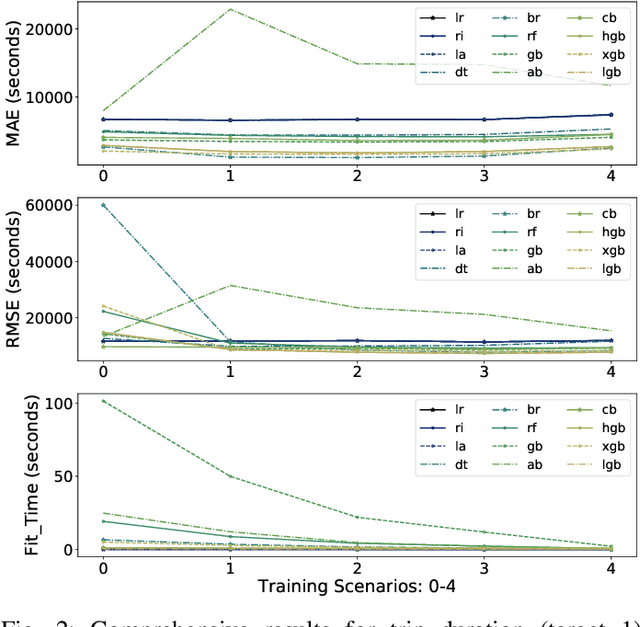
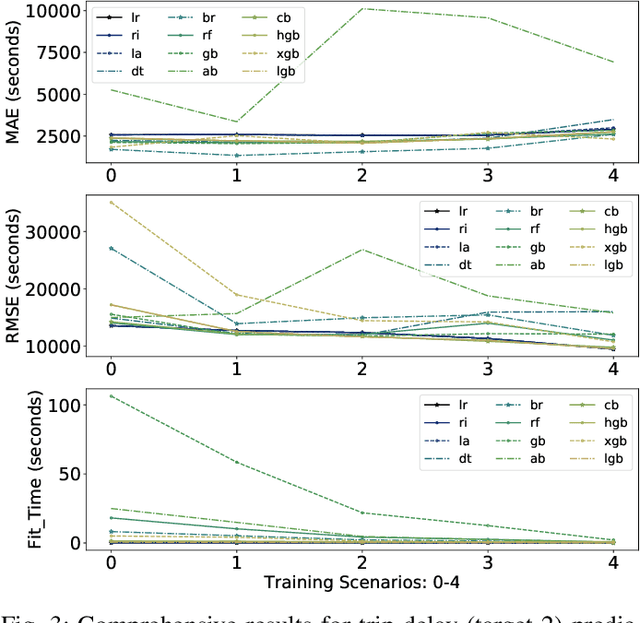
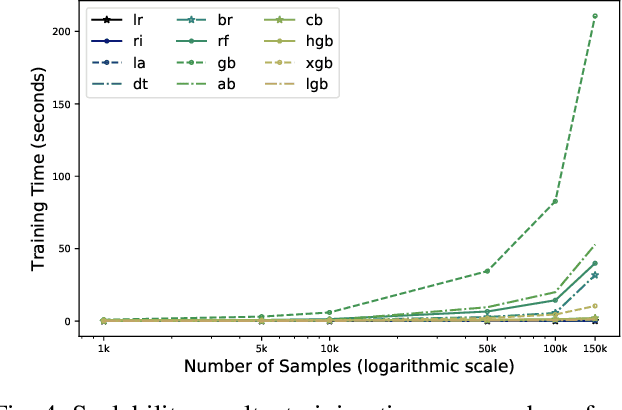
Travel time is a crucial measure in transportation. Accurate travel time prediction is also fundamental for operation and advanced information systems. A variety of solutions exist for short-term travel time predictions such as solutions that utilize real-time GPS data and optimization methods to track the path of a vehicle. However, reliable long-term predictions remain challenging. We show in this paper the applicability and usefulness of travel time i.e. delivery time prediction for postal services. We investigate several methods such as linear regression models and tree based ensembles such as random forest, bagging, and boosting, that allow to predict delivery time by conducting extensive experiments and considering many usability scenarios. Results reveal that travel time prediction can help mitigate high delays in postal services. We show that some boosting algorithms, such as light gradient boosting and catboost, have a higher performance in terms of accuracy and runtime efficiency than other baselines such as linear regression models, bagging regressor and random forest.
Diversity-Aware Weighted Majority Vote Classifier for Imbalanced Data
Apr 16, 2020
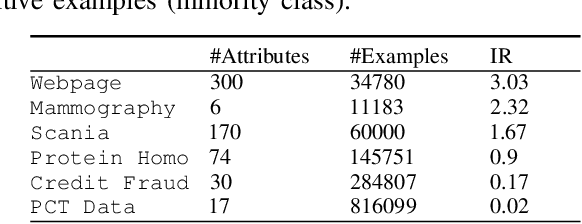
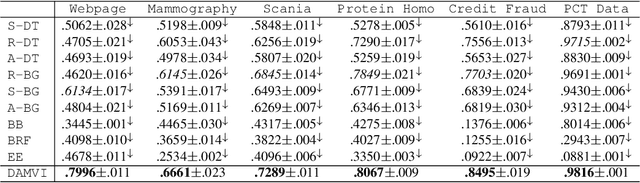

In this paper, we propose a diversity-aware ensemble learning based algorithm, referred to as DAMVI, to deal with imbalanced binary classification tasks. Specifically, after learning base classifiers, the algorithm i) increases the weights of positive examples (minority class) which are "hard" to classify with uniformly weighted base classifiers; and ii) then learns weights over base classifiers by optimizing the PAC-Bayesian C-Bound that takes into account the accuracy and diversity between the classifiers. We show efficiency of the proposed approach with respect to state-of-art models on predictive maintenance task, credit card fraud detection, webpage classification and medical applications.
MetaBags: Bagged Meta-Decision Trees for Regression
Apr 17, 2018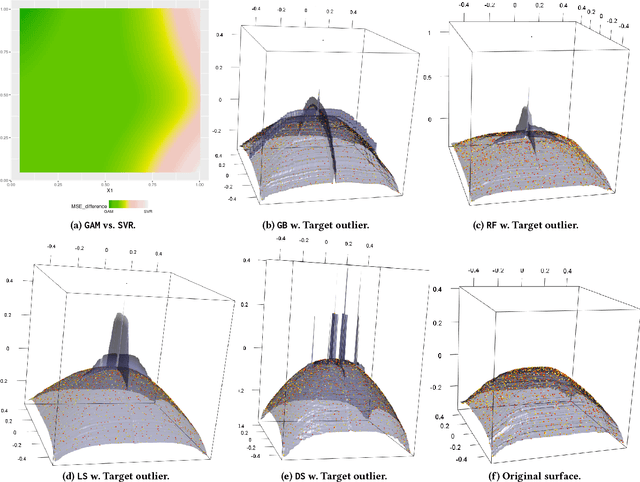
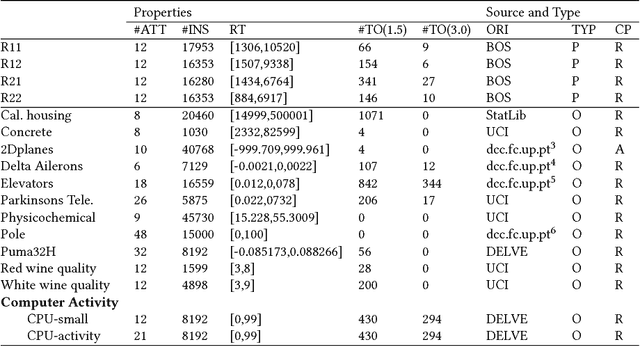
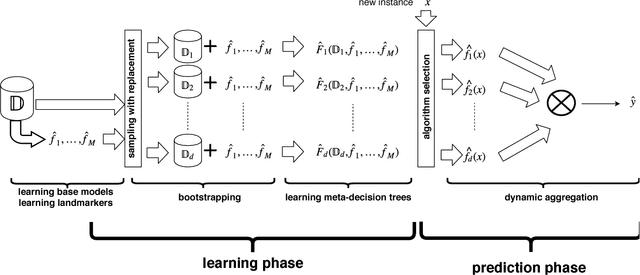

Ensembles are popular methods for solving practical supervised learning problems. They reduce the risk of having underperforming models in production-grade software. Although critical, methods for learning heterogeneous regression ensembles have not been proposed at large scale, whereas in classical ML literature, stacking, cascading and voting are mostly restricted to classification problems. Regression poses distinct learning challenges that may result in poor performance, even when using well established homogeneous ensemble schemas such as bagging or boosting. In this paper, we introduce MetaBags, a novel, practically useful stacking framework for regression. MetaBags is a meta-learning algorithm that learns a set of meta-decision trees designed to select one base model (i.e. expert) for each query, and focuses on inductive bias reduction. A set of meta-decision trees are learned using different types of meta-features, specially created for this purpose - to then be bagged at meta-level. This procedure is designed to learn a model with a fair bias-variance trade-off, and its improvement over base model performance is correlated with the prediction diversity of different experts on specific input space subregions. The proposed method and meta-features are designed in such a way that they enable good predictive performance even in subregions of space which are not adequately represented in the available training data. An exhaustive empirical testing of the method was performed, evaluating both generalization error and scalability of the approach on synthetic, open and real-world application datasets. The obtained results show that our method significantly outperforms existing state-of-the-art approaches.