 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimits of spectral learning under noise
Jun 11, 2026Learning functional relationships from noisy data is a central problem in scientific inference. Spectral methods approximate unknown functions by expanding them in a basis and estimating the corresponding coefficients from data, but the stability of these coefficients under noise remains poorly understood. Here we study supervised regression with additive label noise using sparse spectral representations across multiple bases and dimensions. We show that noise induces a predictable drift in the learned coefficient vector whose magnitude depends on the effective number of active spectral modes. After whitening the empirical feature geometry, we derive a closed-form expression for the overlap between noisy and noiseless coefficient vectors, revealing a universal degradation curve governed by a single intrinsic noise scale. Numerical experiments across Fourier, Legendre, Bessel, and Haar bases confirm the theoretical prediction. The results demonstrate that spectral learning exhibits a fundamental noise threshold beyond which coefficient estimates become unstable, placing intrinsic limits on recovering functional structure from noisy data.
Advancing the Scientific Method with Large Language Models: From Hypothesis to Discovery
May 22, 2025With recent Nobel Prizes recognising AI contributions to science, Large Language Models (LLMs) are transforming scientific research by enhancing productivity and reshaping the scientific method. LLMs are now involved in experimental design, data analysis, and workflows, particularly in chemistry and biology. However, challenges such as hallucinations and reliability persist. In this contribution, we review how Large Language Models (LLMs) are redefining the scientific method and explore their potential applications across different stages of the scientific cycle, from hypothesis testing to discovery. We conclude that, for LLMs to serve as relevant and effective creative engines and productivity enhancers, their deep integration into all steps of the scientific process should be pursued in collaboration and alignment with human scientific goals, with clear evaluation metrics. The transition to AI-driven science raises ethical questions about creativity, oversight, and responsibility. With careful guidance, LLMs could evolve into creative engines, driving transformative breakthroughs across scientific disciplines responsibly and effectively. However, the scientific community must also decide how much it leaves to LLMs to drive science, even when associations with 'reasoning', mostly currently undeserved, are made in exchange for the potential to explore hypothesis and solution regions that might otherwise remain unexplored by human exploration alone.
* 45 pages
The Future of Fundamental Science Led by Generative Closed-Loop Artificial Intelligence
Jul 09, 2023



Recent advances in machine learning and AI, including Generative AI and LLMs, are disrupting technological innovation, product development, and society as a whole. AI's contribution to technology can come from multiple approaches that require access to large training data sets and clear performance evaluation criteria, ranging from pattern recognition and classification to generative models. Yet, AI has contributed less to fundamental science in part because large data sets of high-quality data for scientific practice and model discovery are more difficult to access. Generative AI, in general, and Large Language Models in particular, may represent an opportunity to augment and accelerate the scientific discovery of fundamental deep science with quantitative models. Here we explore and investigate aspects of an AI-driven, automated, closed-loop approach to scientific discovery, including self-driven hypothesis generation and open-ended autonomous exploration of the hypothesis space. Integrating AI-driven automation into the practice of science would mitigate current problems, including the replication of findings, systematic production of data, and ultimately democratisation of the scientific process. Realising these possibilities requires a vision for augmented AI coupled with a diversity of AI approaches able to deal with fundamental aspects of causality analysis and model discovery while enabling unbiased search across the space of putative explanations. These advances hold the promise to unleash AI's potential for searching and discovering the fundamental structure of our world beyond what human scientists have been able to achieve. Such a vision would push the boundaries of new fundamental science rather than automatize current workflows and instead open doors for technological innovation to tackle some of the greatest challenges facing humanity today.
MetaBags: Bagged Meta-Decision Trees for Regression
Apr 17, 2018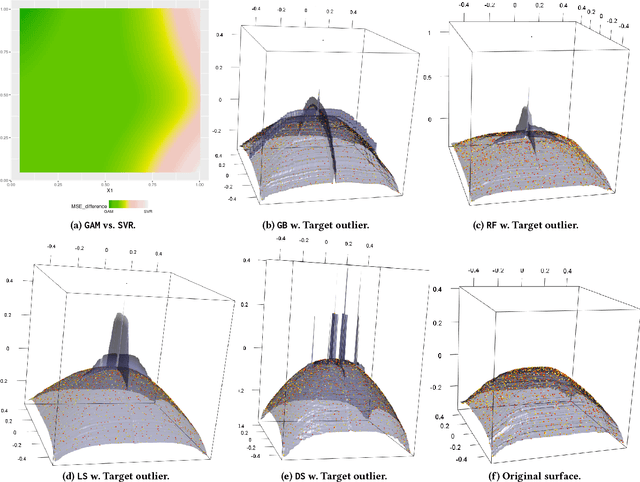
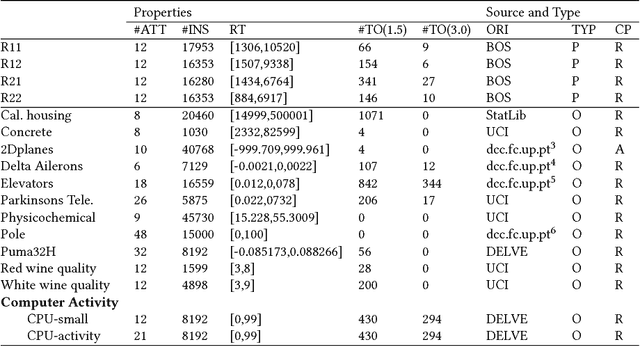
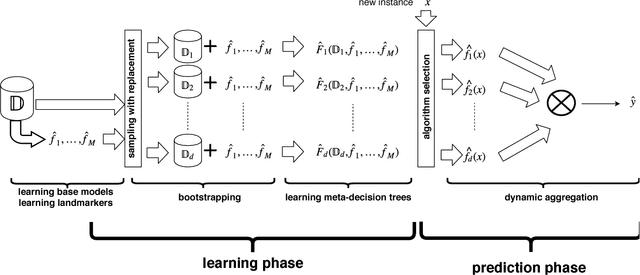

Ensembles are popular methods for solving practical supervised learning problems. They reduce the risk of having underperforming models in production-grade software. Although critical, methods for learning heterogeneous regression ensembles have not been proposed at large scale, whereas in classical ML literature, stacking, cascading and voting are mostly restricted to classification problems. Regression poses distinct learning challenges that may result in poor performance, even when using well established homogeneous ensemble schemas such as bagging or boosting. In this paper, we introduce MetaBags, a novel, practically useful stacking framework for regression. MetaBags is a meta-learning algorithm that learns a set of meta-decision trees designed to select one base model (i.e. expert) for each query, and focuses on inductive bias reduction. A set of meta-decision trees are learned using different types of meta-features, specially created for this purpose - to then be bagged at meta-level. This procedure is designed to learn a model with a fair bias-variance trade-off, and its improvement over base model performance is correlated with the prediction diversity of different experts on specific input space subregions. The proposed method and meta-features are designed in such a way that they enable good predictive performance even in subregions of space which are not adequately represented in the available training data. An exhaustive empirical testing of the method was performed, evaluating both generalization error and scalability of the approach on synthetic, open and real-world application datasets. The obtained results show that our method significantly outperforms existing state-of-the-art approaches.