 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShallow Self-Learning for Reject Inference in Credit Scoring
Paper and Code
Sep 13, 2019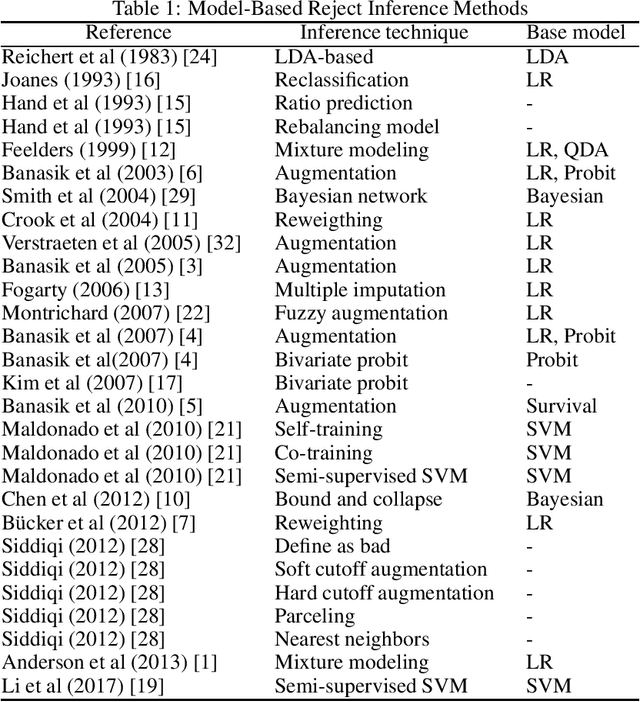



Credit scoring models support loan approval decisions in the financial services industry. Lenders train these models on data from previously granted credit applications, where the borrowers' repayment behavior has been observed. This approach creates sample bias. The scoring model (i.e., classifier) is trained on accepted cases only. Applying the resulting model to screen credit applications from the population of all borrowers degrades model performance. Reject inference comprises techniques to overcome sampling bias through assigning labels to rejected cases. The paper makes two contributions. First, we propose a self-learning framework for reject inference. The framework is geared toward real-world credit scoring requirements through considering distinct training regimes for iterative labeling and model training. Second, we introduce a new measure to assess the effectiveness of reject inference strategies. Our measure leverages domain knowledge to avoid artificial labeling of rejected cases during strategy evaluation. We demonstrate this approach to offer a robust and operational assessment of reject inference strategies. Experiments on a real-world credit scoring data set confirm the superiority of the adjusted self-learning framework over regular self-learning and previous reject inference strategies. We also find strong evidence in favor of the proposed evaluation measure assessing reject inference strategies more reliably, raising the performance of the eventual credit scoring model.