 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe State of Generative AI in Software Development: Insights from Literature and a Developer Survey
Mar 17, 2026Generative Artificial Intelligence (GenAI) rapidly transforms software engineering, yet existing research remains fragmented across individual tasks in the Software Development Lifecycle. This study integrates a systematic literature review with a survey of 65 software developers. The results show that GenAI exerts its highest impact in design, implementation, testing, and documentation, where over 70 % of developers report at least halving the time for boilerplate and documentation tasks. 79 % of survey respondents use GenAI daily, preferring browser-based Large Language Models over alternatives integrated directly in their development environment. Governance is maturing, with two-thirds of organizations maintaining formal or informal guidelines. In contrast, early SDLC phases such as planning and requirements analysis show markedly lower reported benefits. In a nutshell, GenAI shifts value creation from routine coding toward specification quality, architectural reasoning, and oversight, while risks such as uncritical adoption, skill erosion, and technical debt require robust governance and human-in-the-loop mechanisms.
Variational Quantum Circuit-Based Reinforcement Learning for Dynamic Portfolio Optimization
Jan 20, 2026This paper presents a Quantum Reinforcement Learning (QRL) solution to the dynamic portfolio optimization problem based on Variational Quantum Circuits. The implemented QRL approaches are quantum analogues of the classical neural-network-based Deep Deterministic Policy Gradient and Deep Q-Network algorithms. Through an empirical evaluation on real-world financial data, we show that our quantum agents achieve risk-adjusted performance comparable to, and in some cases exceeding, that of classical Deep RL models with several orders of magnitude more parameters. In addition to improved parameter efficiency, quantum agents exhibit reduced variability across market regimes, indicating robust behaviour under changing conditions. However, while quantum circuit execution is inherently fast at the hardware level, practical deployment on cloud-based quantum systems introduces substantial latency, making end-to-end runtime currently dominated by infrastructural overhead and limiting practical applicability. Taken together, our results suggest that QRL is theoretically competitive with state-of-the-art classical reinforcement learning and may become practically advantageous as deployment overheads diminish. This positions QRL as a promising paradigm for dynamic decision-making in complex, high-dimensional, and non-stationary environments such as financial markets. The complete codebase is released as open source at: https://github.com/VincentGurgul/qrl-dpo-public
Leveraging Zero-Shot Prompting for Efficient Language Model Distillation
Mar 23, 2024This paper introduces a novel approach for efficiently distilling LLMs into smaller, application-specific models, significantly reducing operational costs and manual labor. Addressing the challenge of deploying computationally intensive LLMs in specific applications or edge devices, this technique utilizes LLMs' reasoning capabilities to generate labels and natural language rationales for unlabeled data. Our approach enhances both finetuning and distillation by employing a multi-task training framework where student models mimic these rationales alongside teacher predictions. Key contributions include the employment of zero-shot prompting to elicit teacher model rationales, reducing the necessity for handcrafted few-shot examples and lowering the overall token count required, which directly translates to cost savings given the pay-per-token billing model of major tech companies' LLM APIs. Additionally, the paper investigates the impact of explanation properties on distillation efficiency, demonstrating that minimal performance loss occurs even when rationale augmentation is not applied across the entire dataset, facilitating further reductions of tokens. This research marks a step toward the efficient training of task-specific models with minimal human intervention, offering substantial cost-savings while maintaining, or even enhancing, performance.
Forecasting Cryptocurrency Prices Using Deep Learning: Integrating Financial, Blockchain, and Text Data
Nov 23, 2023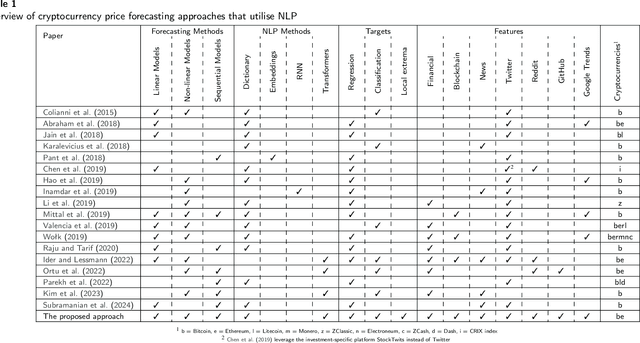
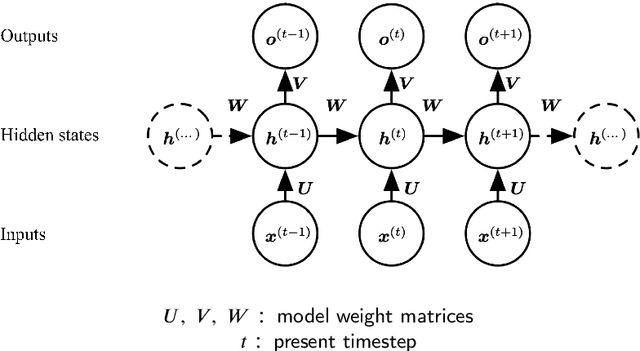
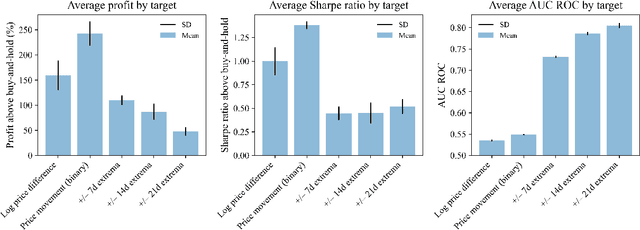
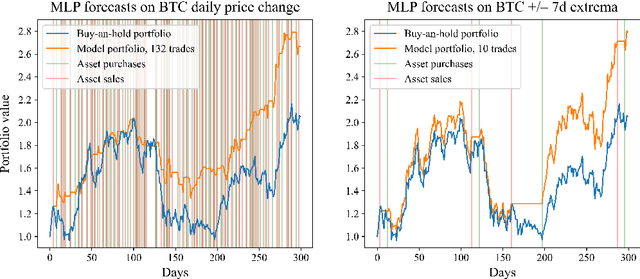
This paper explores the application of Machine Learning (ML) and Natural Language Processing (NLP) techniques in cryptocurrency price forecasting, specifically Bitcoin (BTC) and Ethereum (ETH). Focusing on news and social media data, primarily from Twitter and Reddit, we analyse the influence of public sentiment on cryptocurrency valuations using advanced deep learning NLP methods. Alongside conventional price regression, we treat cryptocurrency price forecasting as a classification problem. This includes both the prediction of price movements (up or down) and the identification of local extrema. We compare the performance of various ML models, both with and without NLP data integration. Our findings reveal that incorporating NLP data significantly enhances the forecasting performance of our models. We discover that pre-trained models, such as Twitter-RoBERTa and BART MNLI, are highly effective in capturing market sentiment, and that fine-tuning Large Language Models (LLMs) also yields substantial forecasting improvements. Notably, the BART MNLI zero-shot classification model shows considerable proficiency in extracting bullish and bearish signals from textual data. All of our models consistently generate profit across different validation scenarios, with no observed decline in profits or reduction in the impact of NLP data over time. The study highlights the potential of text analysis in improving financial forecasts and demonstrates the effectiveness of various NLP techniques in capturing nuanced market sentiment.