 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy Price Modelling: A Comparative Evaluation of four Generations of Forecasting Methods
Nov 05, 2024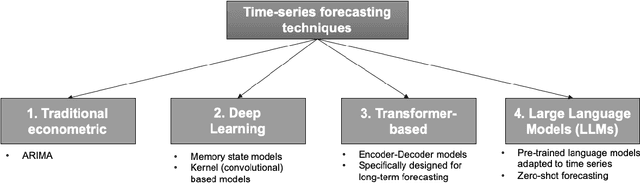


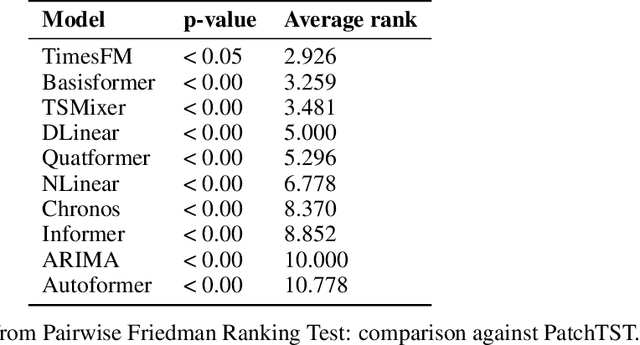
Energy is a critical driver of modern economic systems. Accurate energy price forecasting plays an important role in supporting decision-making at various levels, from operational purchasing decisions at individual business organizations to policy-making. A significant body of literature has looked into energy price forecasting, investigating a wide range of methods to improve accuracy and inform these critical decisions. Given the evolving landscape of forecasting techniques, the literature lacks a thorough empirical comparison that systematically contrasts these methods. This paper provides an in-depth review of the evolution of forecasting modeling frameworks, from well-established econometric models to machine learning methods, early sequence learners such LSTMs, and more recent advancements in deep learning with transformer networks, which represent the cutting edge in forecasting. We offer a detailed review of the related literature and categorize forecasting methodologies into four model families. We also explore emerging concepts like pre-training and transfer learning, which have transformed the analysis of unstructured data and hold significant promise for time series forecasting. We address a gap in the literature by performing a comprehensive empirical analysis on these four family models, using data from the EU energy markets, we conduct a large-scale empirical study, which contrasts the forecasting accuracy of different approaches, focusing especially on alternative propositions for time series transformers.
How much do we really know about Structure Learning from i.i.d. Data? Interpretable, multi-dimensional Performance Indicator for Causal Discovery
Sep 28, 2024Nonlinear causal discovery from observational data imposes strict identifiability assumptions on the formulation of structural equations utilized in the data generating process. The evaluation of structure learning methods under assumption violations requires a rigorous and interpretable approach, which quantifies both the structural similarity of the estimation with the ground truth and the capacity of the discovered graphs to be used for causal inference. Motivated by the lack of unified performance assessment framework, we introduce an interpretable, six-dimensional evaluation metric, i.e., distance to optimal solution (DOS), which is specifically tailored to the field of causal discovery. Furthermore, this is the first research to assess the performance of structure learning algorithms from seven different families on increasing percentage of non-identifiable, nonlinear causal patterns, inspired by real-world processes. Our large-scale simulation study, which incorporates seven experimental factors, shows that besides causal order-based methods, amortized causal discovery delivers results with comparatively high proximity to the optimal solution. In addition to the findings from our sensitivity analysis, we explore interactions effects between the experimental factors of our simulation framework in order to provide transparency about the expected performance of causal discovery techniques in different scenarios.