 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe impact of heteroskedasticity on uplift modeling
Dec 08, 2023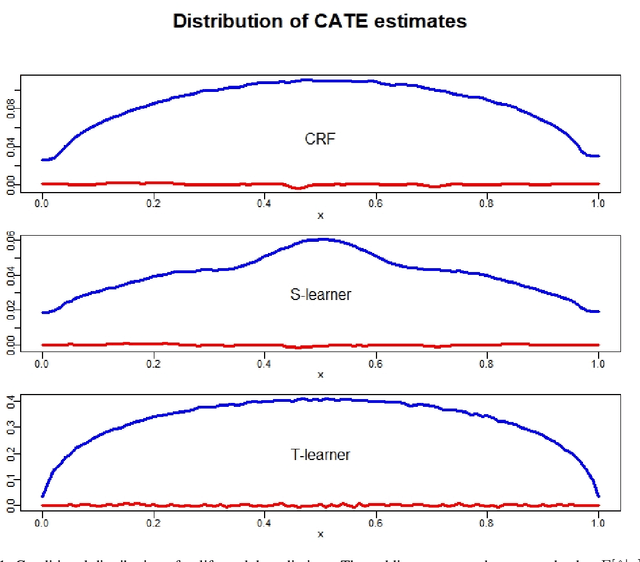
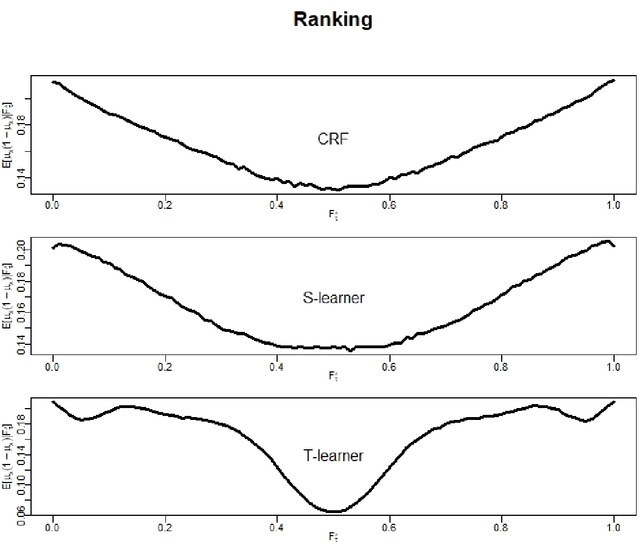
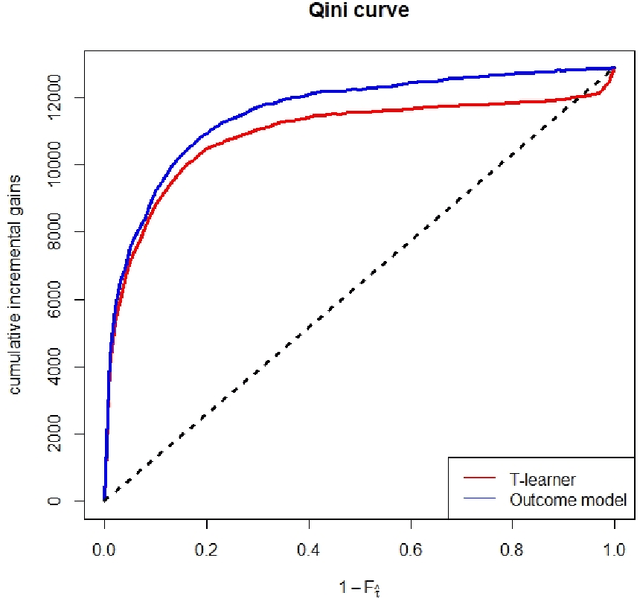
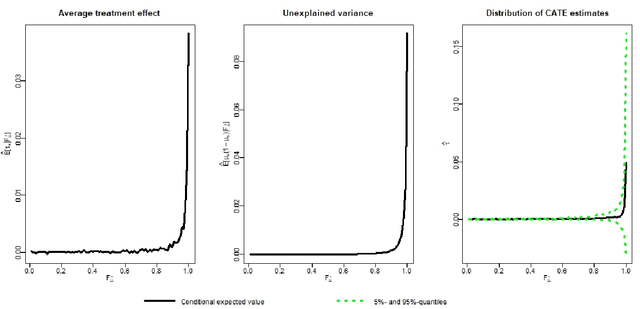
There are various applications, where companies need to decide to which individuals they should best allocate treatment. To support such decisions, uplift models are applied to predict treatment effects on an individual level. Based on the predicted treatment effects, individuals can be ranked and treatment allocation can be prioritized according to this ranking. An implicit assumption, which has not been doubted in the previous uplift modeling literature, is that this treatment prioritization approach tends to bring individuals with high treatment effects to the top and individuals with low treatment effects to the bottom of the ranking. In our research, we show that heteroskedastictity in the training data can cause a bias of the uplift model ranking: individuals with the highest treatment effects can get accumulated in large numbers at the bottom of the ranking. We explain theoretically how heteroskedasticity can bias the ranking of uplift models and show this process in a simulation and on real-world data. We argue that this problem of ranking bias due to heteroskedasticity might occur in many real-world applications and requires modification of the treatment prioritization to achieve an efficient treatment allocation.
Improving uplift model evaluation on RCT data
Oct 05, 2022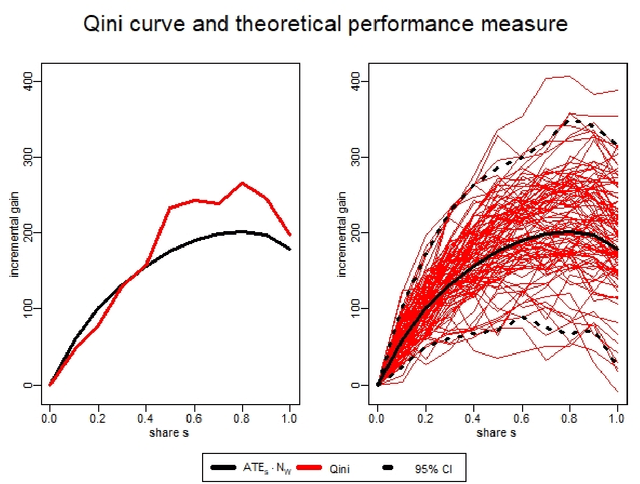
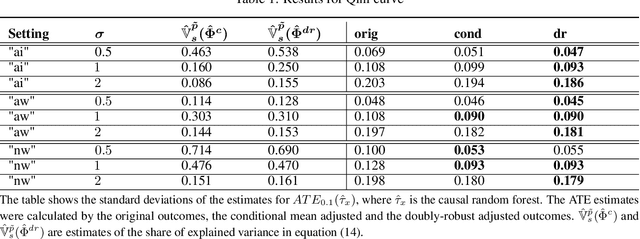
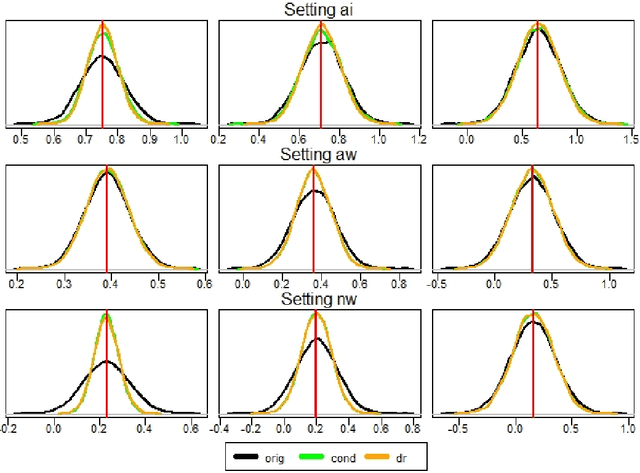
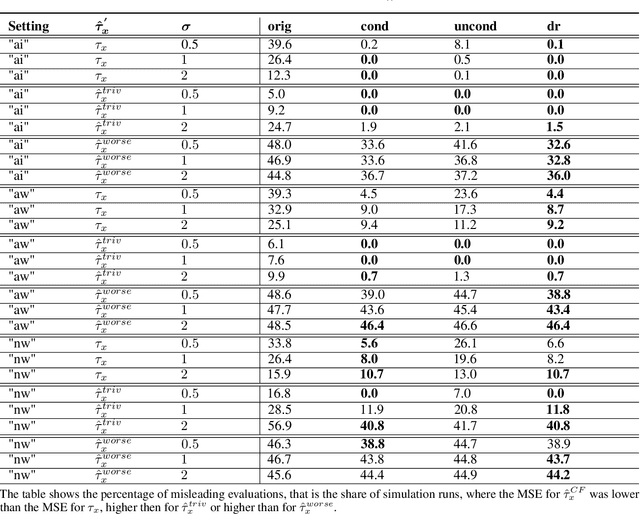
Estimating treatment effects is one of the most challenging and important tasks of data analysts. Traditional statistical methods aim to estimate average treatment effects over a population. While being highly useful, such average treatment effects do not help to decide which individuals profit most by the treatment. This is where uplift modeling becomes important. Uplift models help to select the right individuals for treatment, to maximize the overall treatment effect (uplift). A challenging problem in uplift modeling is to evaluate the models. Previous literature suggests methods like the Qini curve and the transformed outcome mean squared error. However, these metrics suffer from variance: Their evaluations are strongly affected by random noise in the data, which makes these evaluations to a certain degree arbitrary. In this paper, we analyze the variance of the uplift evaluation metrics, on randomized controlled trial data, in a sound statistical manner. We propose certain outcome adjustment methods, for which we prove theoretically and empirically, that they reduce the variance of the uplift evaluation metrics. Our statistical analysis and the proposed outcome adjustment methods are a step towards a better evaluation practice in uplift modeling.