 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Information Aggregation with Centrality Attention
Paper and Code
Nov 16, 2020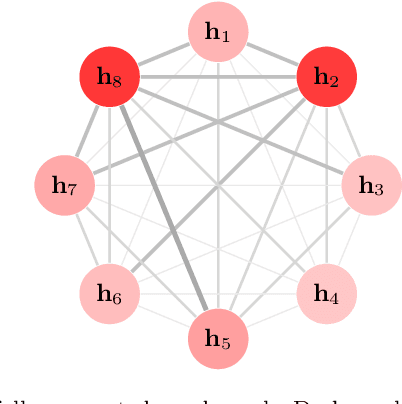
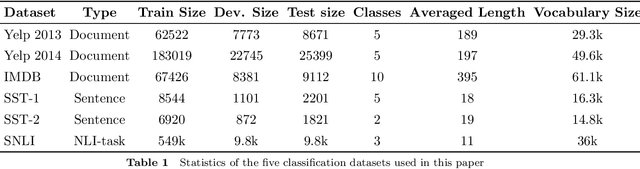
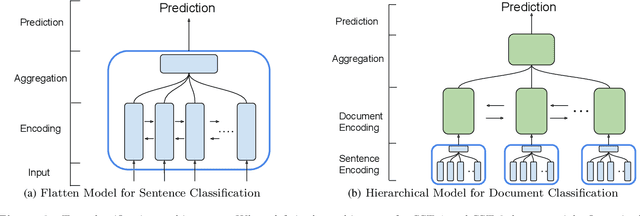
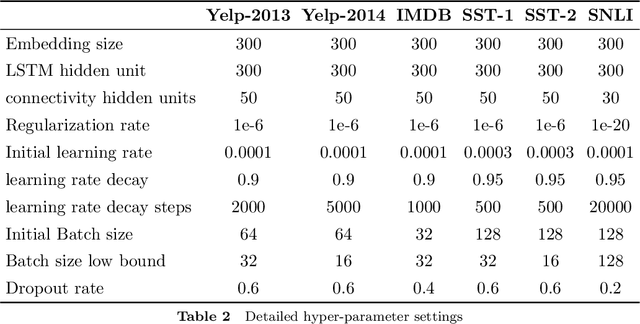
A lot of natural language processing problems need to encode the text sequence as a fix-length vector, which usually involves aggregation process of combining the representations of all the words, such as pooling or self-attention. However, these widely used aggregation approaches did not take higher-order relationship among the words into consideration. Hence we propose a new way of obtaining aggregation weights, called eigen-centrality self-attention. More specifically, we build a fully-connected graph for all the words in a sentence, then compute the eigen-centrality as the attention score of each word. The explicit modeling of relationships as a graph is able to capture some higher-order dependency among words, which helps us achieve better results in 5 text classification tasks and one SNLI task than baseline models such as pooling, self-attention and dynamic routing. Besides, in order to compute the dominant eigenvector of the graph, we adopt power method algorithm to get the eigen-centrality measure. Moreover, we also derive an iterative approach to get the gradient for the power method process to reduce both memory consumption and computation requirement.}