 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
Automotive Radar Multi-Frame Track-Before-Detect Algorithm Considering Self-Positioning Errors
Apr 24, 2025This paper presents a method for the joint detection and tracking of weak targets in automotive radars using the multi-frame track-before-detect (MF-TBD) procedure. Generally, target tracking in automotive radars is challenging due to radar field of view (FOV) misalignment, nonlinear coordinate conversion, and self-positioning errors of the ego-vehicle, which are caused by platform motion. These issues significantly hinder the implementation of MF-TBD in automotive radars. To address these challenges, a new MF-TBD detection architecture is first proposed. It can adaptively adjust the detection threshold value based on the existence of moving targets within the radar FOV. Since the implementation of MF-TBD necessitates the inclusion of position, velocity, and yaw angle information of the ego-vehicle, each with varying degrees of measurement error, we further propose a multi-frame energy integration strategy for moving-platform radar and accurately derive the target energy integration path functions. The self-positioning errors of the ego-vehicle, which are usually not considered in some previous target tracking approaches, are well addressed. Numerical simulations and experimental results with real radar data demonstrate large detection and tracking gains over standard automotive radar processing in weak target environments.
Learning with Noisy Labels Using Collaborative Sample Selection and Contrastive Semi-Supervised Learning
Oct 24, 2023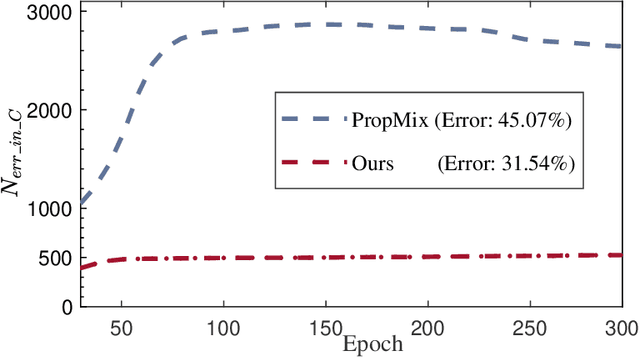
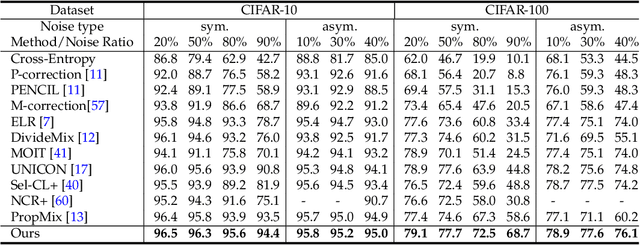
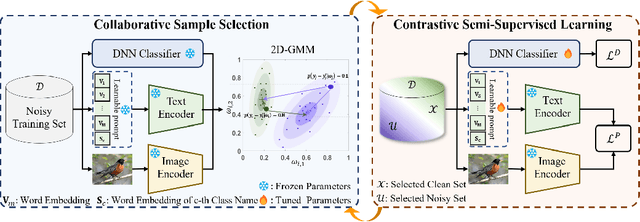
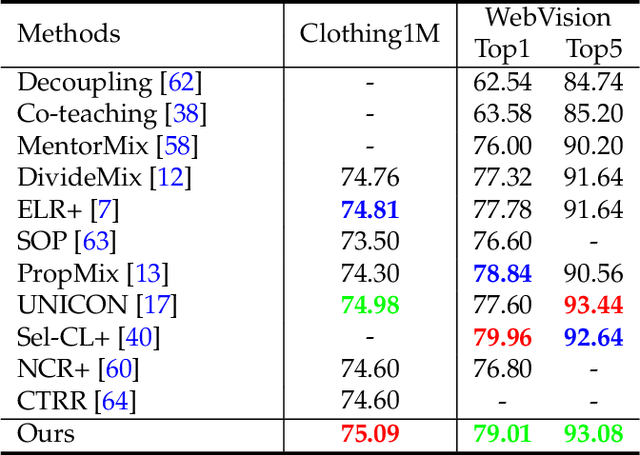
Learning with noisy labels (LNL) has been extensively studied, with existing approaches typically following a framework that alternates between clean sample selection and semi-supervised learning (SSL). However, this approach has a limitation: the clean set selected by the Deep Neural Network (DNN) classifier, trained through self-training, inevitably contains noisy samples. This mixture of clean and noisy samples leads to misguidance in DNN training during SSL, resulting in impaired generalization performance due to confirmation bias caused by error accumulation in sample selection. To address this issue, we propose a method called Collaborative Sample Selection (CSS), which leverages the large-scale pre-trained model CLIP. CSS aims to remove the mixed noisy samples from the identified clean set. We achieve this by training a 2-Dimensional Gaussian Mixture Model (2D-GMM) that combines the probabilities from CLIP with the predictions from the DNN classifier. To further enhance the adaptation of CLIP to LNL, we introduce a co-training mechanism with a contrastive loss in semi-supervised learning. This allows us to jointly train the prompt of CLIP and the DNN classifier, resulting in improved feature representation, boosted classification performance of DNNs, and reciprocal benefits to our Collaborative Sample Selection. By incorporating auxiliary information from CLIP and utilizing prompt fine-tuning, we effectively eliminate noisy samples from the clean set and mitigate confirmation bias during training. Experimental results on multiple benchmark datasets demonstrate the effectiveness of our proposed method in comparison with the state-of-the-art approaches.