 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Noisy Labels Using Collaborative Sample Selection and Contrastive Semi-Supervised Learning
Oct 24, 2023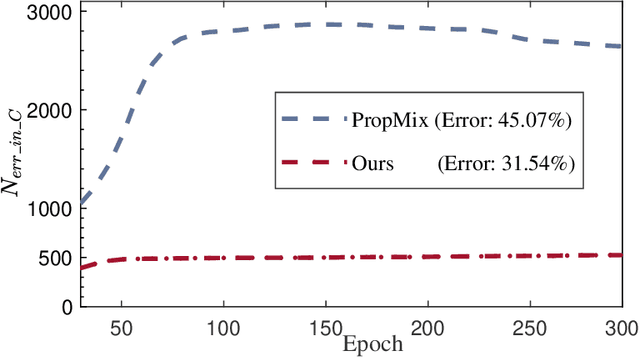
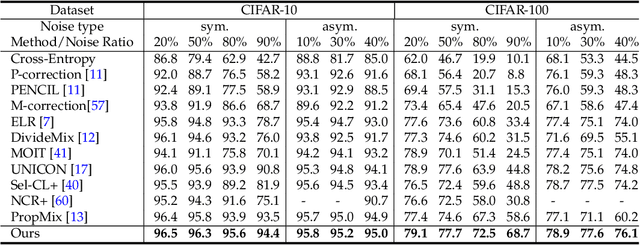
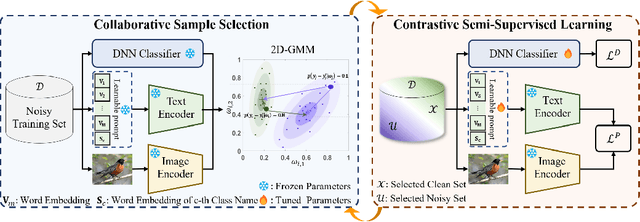
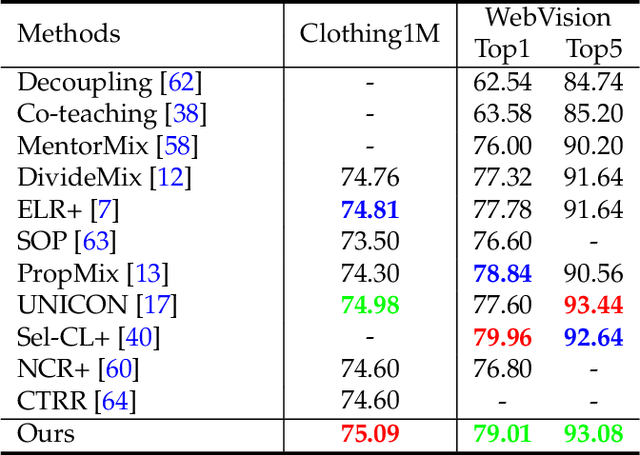
Learning with noisy labels (LNL) has been extensively studied, with existing approaches typically following a framework that alternates between clean sample selection and semi-supervised learning (SSL). However, this approach has a limitation: the clean set selected by the Deep Neural Network (DNN) classifier, trained through self-training, inevitably contains noisy samples. This mixture of clean and noisy samples leads to misguidance in DNN training during SSL, resulting in impaired generalization performance due to confirmation bias caused by error accumulation in sample selection. To address this issue, we propose a method called Collaborative Sample Selection (CSS), which leverages the large-scale pre-trained model CLIP. CSS aims to remove the mixed noisy samples from the identified clean set. We achieve this by training a 2-Dimensional Gaussian Mixture Model (2D-GMM) that combines the probabilities from CLIP with the predictions from the DNN classifier. To further enhance the adaptation of CLIP to LNL, we introduce a co-training mechanism with a contrastive loss in semi-supervised learning. This allows us to jointly train the prompt of CLIP and the DNN classifier, resulting in improved feature representation, boosted classification performance of DNNs, and reciprocal benefits to our Collaborative Sample Selection. By incorporating auxiliary information from CLIP and utilizing prompt fine-tuning, we effectively eliminate noisy samples from the clean set and mitigate confirmation bias during training. Experimental results on multiple benchmark datasets demonstrate the effectiveness of our proposed method in comparison with the state-of-the-art approaches.
Universal Weighting Metric Learning for Cross-Modal Matching
Oct 07, 2020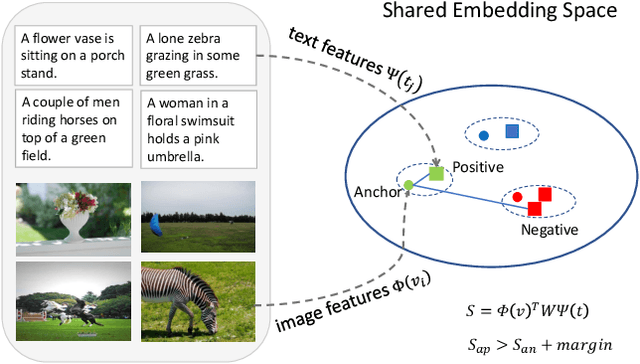
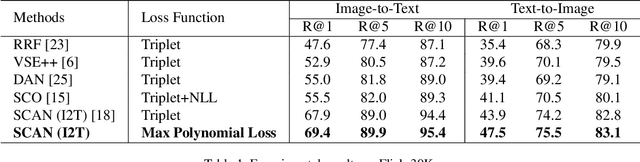
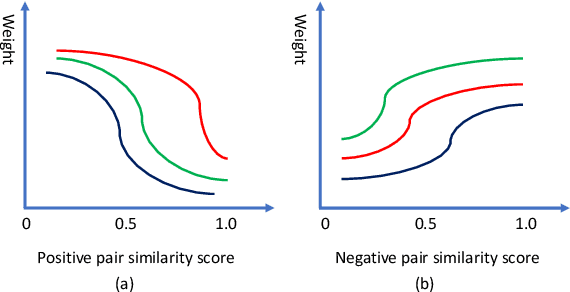
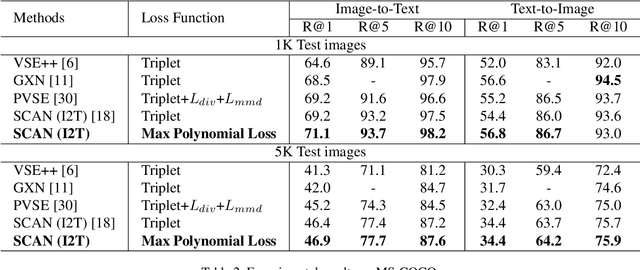
Cross-modal matching has been a highlighted research topic in both vision and language areas. Learning appropriate mining strategy to sample and weight informative pairs is crucial for the cross-modal matching performance. However, most existing metric learning methods are developed for unimodal matching, which is unsuitable for cross-modal matching on multimodal data with heterogeneous features. To address this problem, we propose a simple and interpretable universal weighting framework for cross-modal matching, which provides a tool to analyze the interpretability of various loss functions. Furthermore, we introduce a new polynomial loss under the universal weighting framework, which defines a weight function for the positive and negative informative pairs respectively. Experimental results on two image-text matching benchmarks and two video-text matching benchmarks validate the efficacy of the proposed method.
Learning to Optimize Non-Rigid Tracking
Mar 27, 2020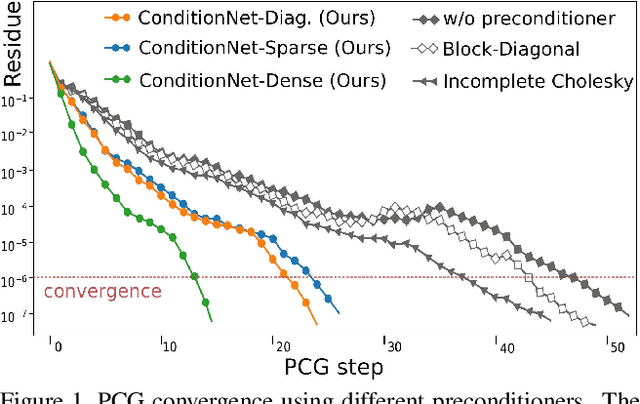
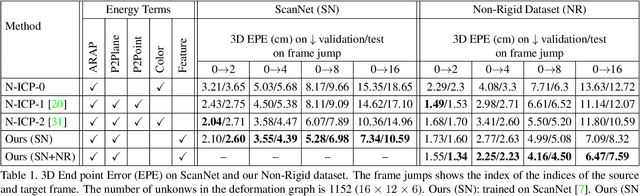
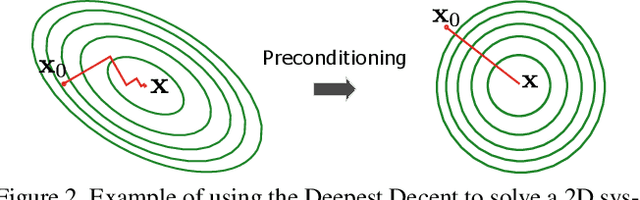
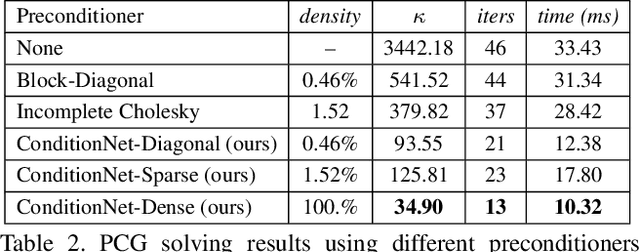
One of the widespread solutions for non-rigid tracking has a nested-loop structure: with Gauss-Newton to minimize a tracking objective in the outer loop, and Preconditioned Conjugate Gradient (PCG) to solve a sparse linear system in the inner loop. In this paper, we employ learnable optimizations to improve tracking robustness and speed up solver convergence. First, we upgrade the tracking objective by integrating an alignment data term on deep features which are learned end-to-end through CNN. The new tracking objective can capture the global deformation which helps Gauss-Newton to jump over local minimum, leading to robust tracking on large non-rigid motions. Second, we bridge the gap between the preconditioning technique and learning method by introducing a ConditionNet which is trained to generate a preconditioner such that PCG can converge within a small number of steps. Experimental results indicate that the proposed learning method converges faster than the original PCG by a large margin.
A Large-scale Varying-view RGB-D Action Dataset for Arbitrary-view Human Action Recognition
Apr 24, 2019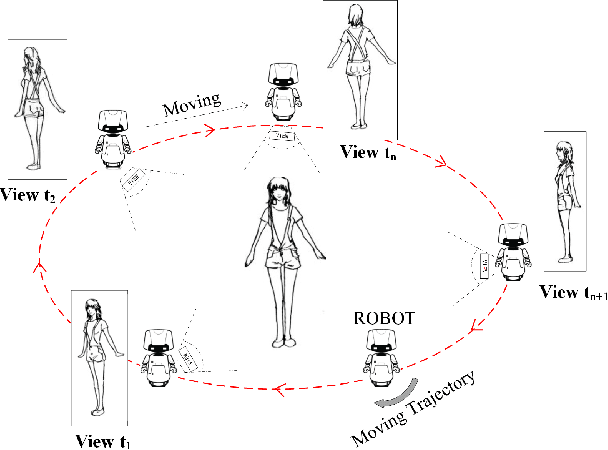
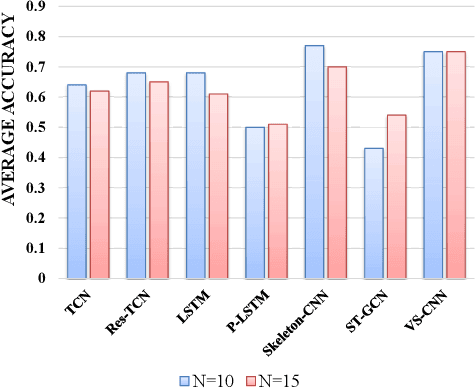


Current researches of action recognition mainly focus on single-view and multi-view recognition, which can hardly satisfies the requirements of human-robot interaction (HRI) applications to recognize actions from arbitrary views. The lack of datasets also sets up barriers. To provide data for arbitrary-view action recognition, we newly collect a large-scale RGB-D action dataset for arbitrary-view action analysis, including RGB videos, depth and skeleton sequences. The dataset includes action samples captured in 8 fixed viewpoints and varying-view sequences which covers the entire 360 degree view angles. In total, 118 persons are invited to act 40 action categories, and 25,600 video samples are collected. Our dataset involves more participants, more viewpoints and a large number of samples. More importantly, it is the first dataset containing the entire 360 degree varying-view sequences. The dataset provides sufficient data for multi-view, cross-view and arbitrary-view action analysis. Besides, we propose a View-guided Skeleton CNN (VS-CNN) to tackle the problem of arbitrary-view action recognition. Experiment results show that the VS-CNN achieves superior performance.