 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-scale Varying-view RGB-D Action Dataset for Arbitrary-view Human Action Recognition
Apr 24, 2019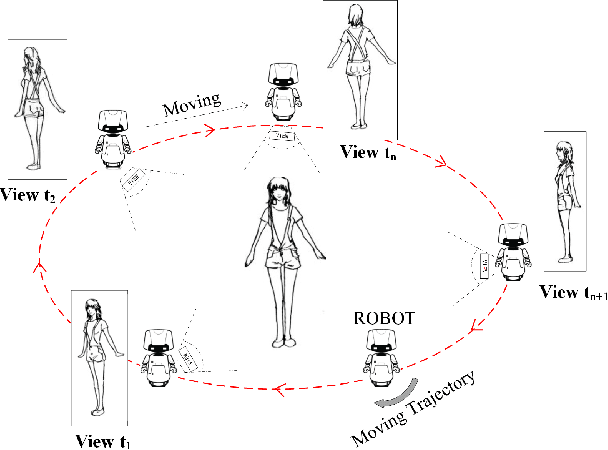
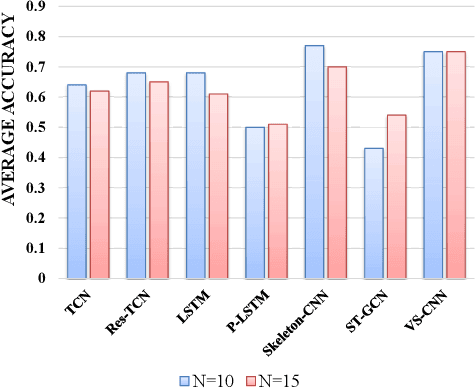


Current researches of action recognition mainly focus on single-view and multi-view recognition, which can hardly satisfies the requirements of human-robot interaction (HRI) applications to recognize actions from arbitrary views. The lack of datasets also sets up barriers. To provide data for arbitrary-view action recognition, we newly collect a large-scale RGB-D action dataset for arbitrary-view action analysis, including RGB videos, depth and skeleton sequences. The dataset includes action samples captured in 8 fixed viewpoints and varying-view sequences which covers the entire 360 degree view angles. In total, 118 persons are invited to act 40 action categories, and 25,600 video samples are collected. Our dataset involves more participants, more viewpoints and a large number of samples. More importantly, it is the first dataset containing the entire 360 degree varying-view sequences. The dataset provides sufficient data for multi-view, cross-view and arbitrary-view action analysis. Besides, we propose a View-guided Skeleton CNN (VS-CNN) to tackle the problem of arbitrary-view action recognition. Experiment results show that the VS-CNN achieves superior performance.