 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Prompt Enhancement for Improving Zero-Shot Generalization of Vision-Language Models
Aug 24, 2025Vision-language models (VLMs) pre-trained on web-scale data exhibit promising zero-shot generalization but often suffer from semantic misalignment due to domain gaps between pre-training and downstream tasks. Existing approaches primarily focus on text prompting with class-specific descriptions and visual-text adaptation via aligning cropped image regions with textual descriptions. However, they still face the issues of incomplete textual prompts and noisy visual prompts. In this paper, we propose a novel constrained prompt enhancement (CPE) method to improve visual-textual alignment by constructing comprehensive textual prompts and compact visual prompts from the semantic perspective. Specifically, our approach consists of two key components: Topology-Guided Synonymous Semantic Generation (TGSSG) and Category-Agnostic Discriminative Region Selection (CADRS). Textually, to address the issue of incomplete semantic expression in textual prompts, our TGSSG first generates synonymous semantic set for each category via large language models, and constructs comprehensive textual prompts based on semantic ambiguity entropy and persistent homology analysis. Visually, to mitigate the irrelevant visual noise introduced by random cropping, our CADRS identifies discriminative regions with activation maps outputted by a pre-trained vision model, effectively filtering out noisy regions and generating compact visual prompts. Given the comprehensive set of textual prompts and compact set of visual prompts, we introduce two set-to-set matching strategies based on test-time adaptation (TTA) and optimal transport (OT) to achieve effective visual-textual alignment, and so improve zero-shot generalization of VLMs.
$S^3$: Synonymous Semantic Space for Improving Zero-Shot Generalization of Vision-Language Models
Dec 06, 2024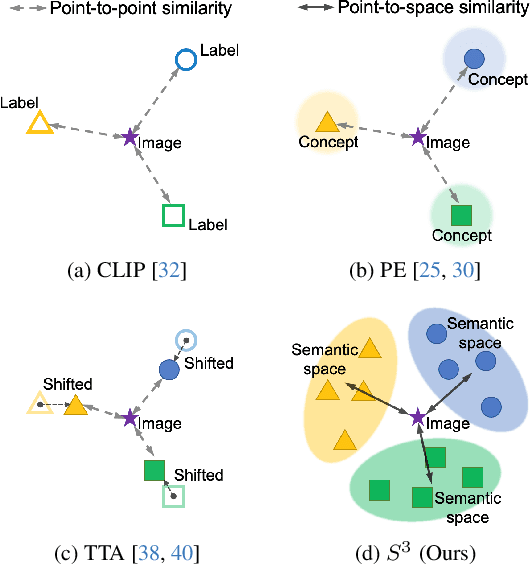
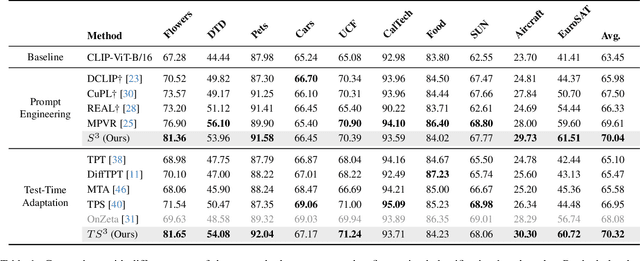
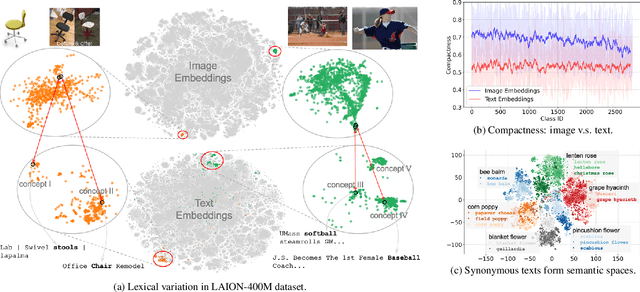
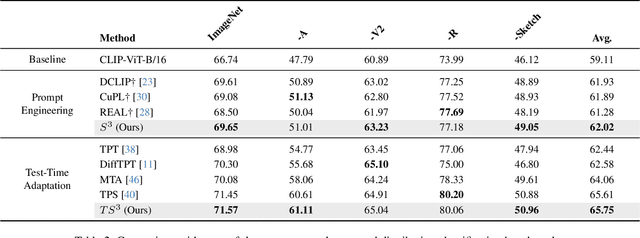
Recently, many studies have been conducted to enhance the zero-shot generalization ability of vision-language models (e.g., CLIP) by addressing the semantic misalignment between image and text embeddings in downstream tasks. Although many efforts have been made, existing methods barely consider the fact that a class of images can be described by notably different textual concepts due to well-known lexical variation in natural language processing, which heavily affects the zero-shot generalization of CLIP. Therefore, this paper proposes a \textbf{S}ynonymous \textbf{S}emantic \textbf{S}pace ($S^3$) for each image class, rather than relying on a single textual concept, achieving more stable semantic alignment and improving the zero-shot generalization of CLIP. Specifically, our $S^3$ method first generates several synonymous concepts based on the label of each class by using large language models, and constructs a continuous yet compact synonymous semantic space based on the Vietoris-Rips complex of the generated synonymous concepts. Furthermore, we explore the effect of several point-to-space metrics on our $S^3$, while presenting a point-to-local-center metric to compute similarity between image embeddings and the synonymous semantic space of each class, accomplishing effective zero-shot predictions. Extensive experiments are conducted across 17 benchmarks, including fine-grained zero-shot classification, natural distribution zero-shot classification, and open-vocabulary segmentation, and the results show that our $S^3$ outperforms state-of-the-art methods.