 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$S^3$: Synonymous Semantic Space for Improving Zero-Shot Generalization of Vision-Language Models
Paper and Code
Dec 06, 2024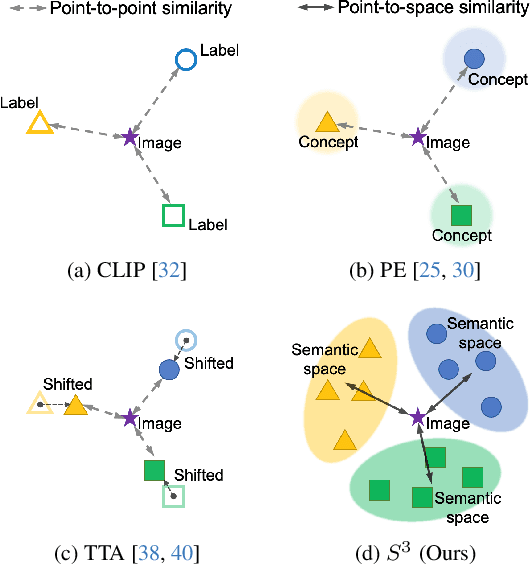
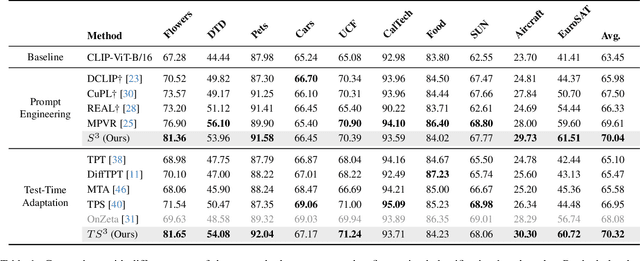
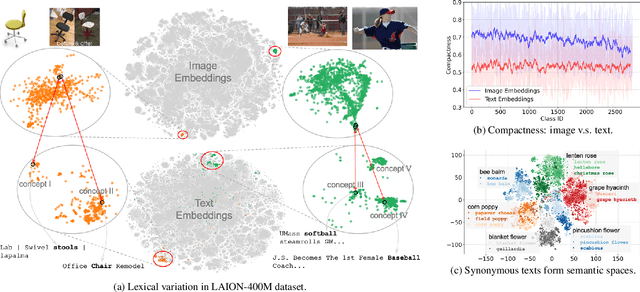
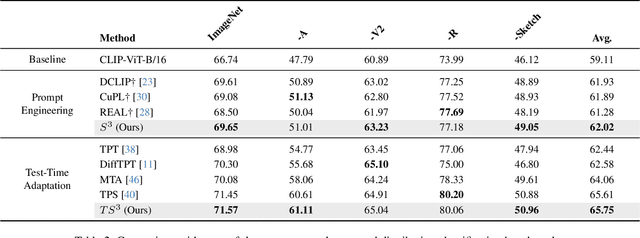
Recently, many studies have been conducted to enhance the zero-shot generalization ability of vision-language models (e.g., CLIP) by addressing the semantic misalignment between image and text embeddings in downstream tasks. Although many efforts have been made, existing methods barely consider the fact that a class of images can be described by notably different textual concepts due to well-known lexical variation in natural language processing, which heavily affects the zero-shot generalization of CLIP. Therefore, this paper proposes a \textbf{S}ynonymous \textbf{S}emantic \textbf{S}pace ($S^3$) for each image class, rather than relying on a single textual concept, achieving more stable semantic alignment and improving the zero-shot generalization of CLIP. Specifically, our $S^3$ method first generates several synonymous concepts based on the label of each class by using large language models, and constructs a continuous yet compact synonymous semantic space based on the Vietoris-Rips complex of the generated synonymous concepts. Furthermore, we explore the effect of several point-to-space metrics on our $S^3$, while presenting a point-to-local-center metric to compute similarity between image embeddings and the synonymous semantic space of each class, accomplishing effective zero-shot predictions. Extensive experiments are conducted across 17 benchmarks, including fine-grained zero-shot classification, natural distribution zero-shot classification, and open-vocabulary segmentation, and the results show that our $S^3$ outperforms state-of-the-art methods.