 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Uncertainty-Aware Knowledge Amalgamation for Pre-Trained Language Models
Paper and Code
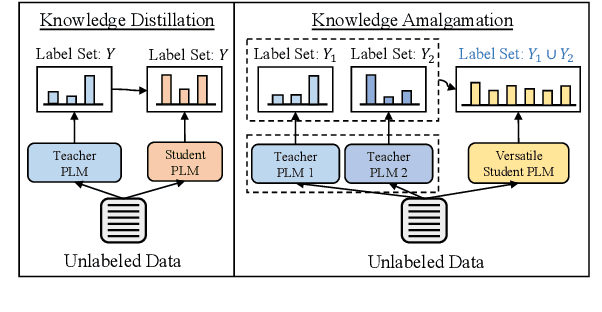
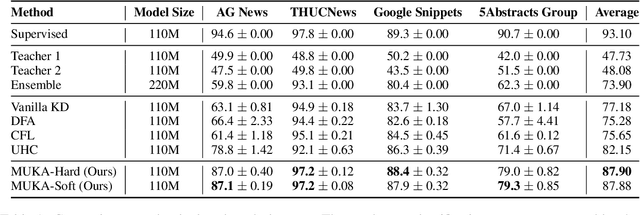
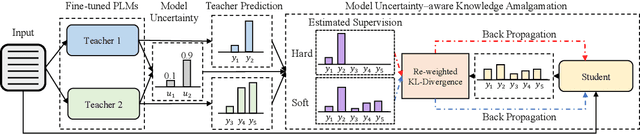
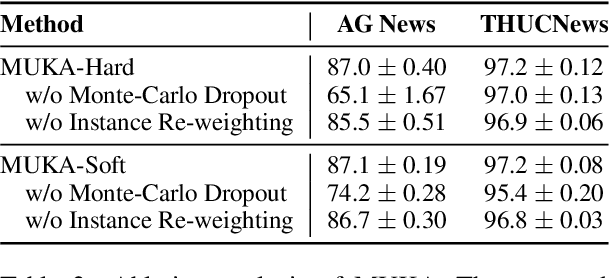
As many fine-tuned pre-trained language models~(PLMs) with promising performance are generously released, investigating better ways to reuse these models is vital as it can greatly reduce the retraining computational cost and the potential environmental side-effects. In this paper, we explore a novel model reuse paradigm, Knowledge Amalgamation~(KA) for PLMs. Without human annotations available, KA aims to merge the knowledge from different teacher-PLMs, each of which specializes in a different classification problem, into a versatile student model. The achieve this, we design a Model Uncertainty--aware Knowledge Amalgamation~(MUKA) framework, which identifies the potential adequate teacher using Monte-Carlo Dropout for approximating the golden supervision to guide the student. Experimental results demonstrate that MUKA achieves substantial improvements over baselines on benchmark datasets. Further analysis shows that MUKA can generalize well under several complicate settings with multiple teacher models, heterogeneous teachers, and even cross-dataset teachers.