 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Flow in Self-Supervised Learning
Oct 15, 2023



In this paper, we provide a comprehensive toolbox for understanding and enhancing self-supervised learning (SSL) methods through the lens of matrix information theory. Specifically, by leveraging the principles of matrix mutual information and joint entropy, we offer a unified analysis for both contrastive and feature decorrelation based methods. Furthermore, we propose the matrix variational masked auto-encoder (M-MAE) method, grounded in matrix information theory, as an enhancement to masked image modeling. The empirical evaluations underscore the effectiveness of M-MAE compared with the state-of-the-art methods, including a 3.9% improvement in linear probing ViT-Base, and a 1% improvement in fine-tuning ViT-Large, both on ImageNet.
Cumulative Reasoning with Large Language Models
Aug 25, 2023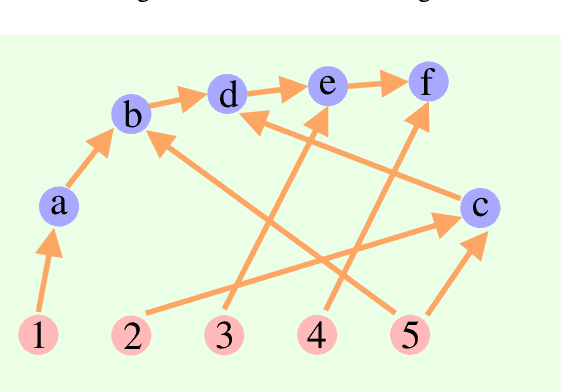
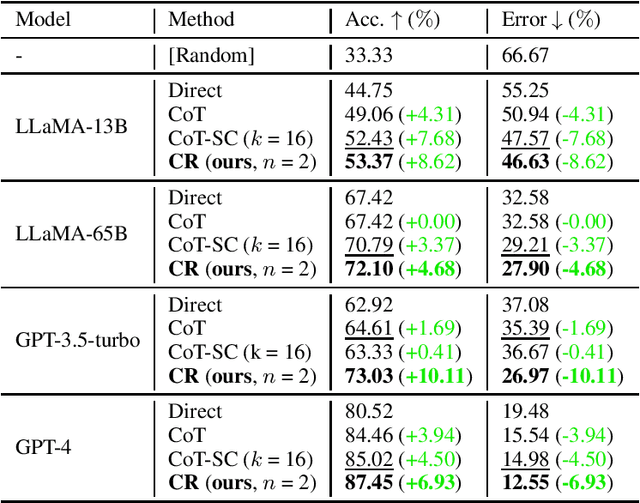
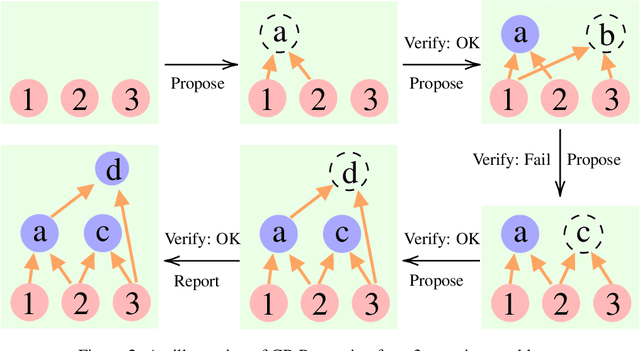
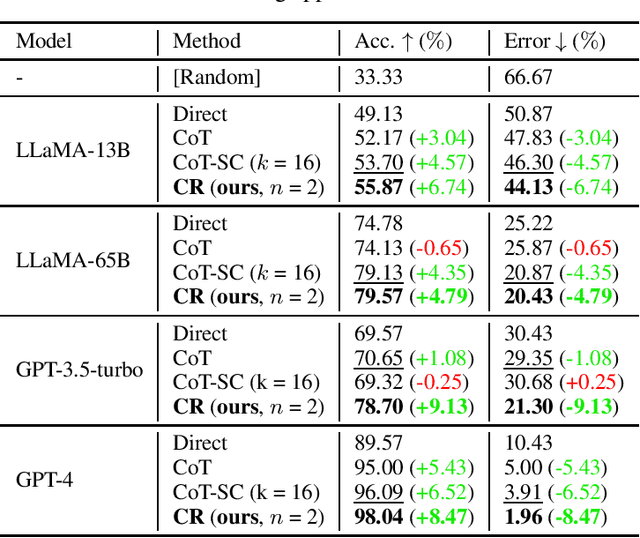
While language models are powerful and versatile, they often fail to address highly complex problems. This is because solving complex problems requires deliberate thinking, which has been only minimally guided during training. In this paper, we propose a new method called Cumulative Reasoning (CR), which employs language models in a cumulative and iterative manner to emulate human thought processes. By decomposing tasks into smaller components, CR streamlines the problem-solving process, rendering it both more manageable and effective. For logical inference tasks, CR consistently outperforms existing methods with an improvement up to 9.3%, and achieves the astonishing accuracy of 98.04% on the curated FOLIO wiki dataset. In the context of the Game of 24, CR achieves an accuracy of 98%, which signifies a substantial enhancement of 24% over the previous state-of-the-art method. Finally, on the MATH dataset, we establish new state-of-the-art results with 58.0% overall accuracy, surpassing the previous best approach by a margin of 4.2%, and achieving 43% relative improvement on the hardest level 5 problems (22.4% to 32.1%). Code is available at https://github.com/iiis-ai/cumulative-reasoning.
Kernel-SSL: Kernel KL Divergence for Self-Supervised Learning
May 30, 2023Contrastive learning usually compares one positive anchor sample with lots of negative samples to perform Self-Supervised Learning (SSL). Alternatively, non-contrastive learning, as exemplified by methods like BYOL, SimSiam, and Barlow Twins, accomplishes SSL without the explicit use of negative samples. Inspired by the existing analysis for contrastive learning, we provide a reproducing kernel Hilbert space (RKHS) understanding of many existing non-contrastive learning methods. Subsequently, we propose a novel loss function, Kernel-SSL, which directly optimizes the mean embedding and the covariance operator within the RKHS. In experiments, our method Kernel-SSL outperforms state-of-the-art methods by a large margin on ImageNet datasets under the linear evaluation settings. Specifically, when performing 100 epochs pre-training, our method outperforms SimCLR by 4.6%.
RelationMatch: Matching In-batch Relationships for Semi-supervised Learning
May 17, 2023Semi-supervised learning has achieved notable success by leveraging very few labeled data and exploiting the wealth of information derived from unlabeled data. However, existing algorithms usually focus on aligning predictions on paired data points augmented from an identical source, and overlook the inter-point relationships within each batch. This paper introduces a novel method, RelationMatch, which exploits in-batch relationships with a matrix cross-entropy (MCE) loss function. Through the application of MCE, our proposed method consistently surpasses the performance of established state-of-the-art methods, such as FixMatch and FlexMatch, across a variety of vision datasets. Notably, we observed a substantial enhancement of 15.21% in accuracy over FlexMatch on the STL-10 dataset using only 40 labels. Moreover, we apply MCE to supervised learning scenarios, and observe consistent improvements as well.
Contrastive Learning Is Spectral Clustering On Similarity Graph
Mar 27, 2023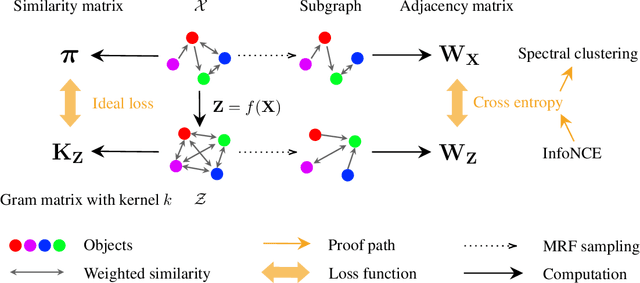
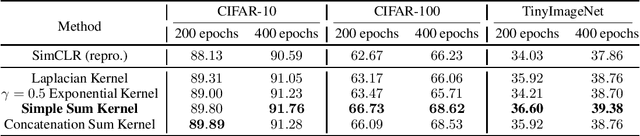


Contrastive learning is a powerful self-supervised learning method, but we have a limited theoretical understanding of how it works and why it works. In this paper, we prove that contrastive learning with the standard InfoNCE loss is equivalent to spectral clustering on the similarity graph. Using this equivalence as the building block, we extend our analysis to the CLIP model and rigorously characterize how similar multi-modal objects are embedded together. Motivated by our theoretical insights, we introduce the kernel mixture loss, incorporating novel kernel functions that outperform the standard Gaussian kernel on several vision datasets.