 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailbreak Instruction-Tuned LLMs via end-of-sentence MLP Re-weighting
Oct 14, 2024
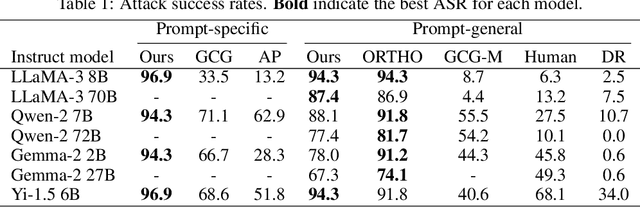
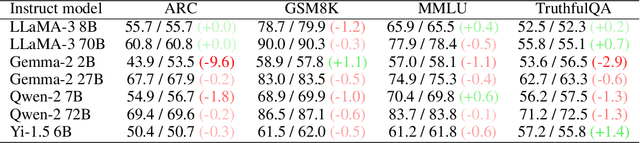
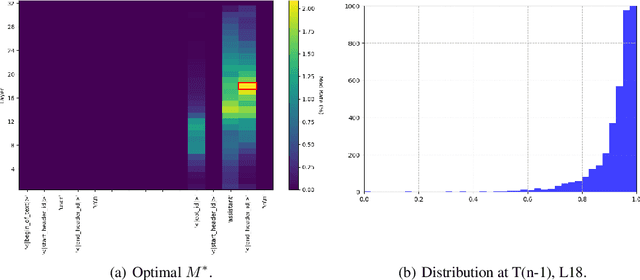
In this paper, we investigate the safety mechanisms of instruction fine-tuned large language models (LLMs). We discover that re-weighting MLP neurons can significantly compromise a model's safety, especially for MLPs in end-of-sentence inferences. We hypothesize that LLMs evaluate the harmfulness of prompts during end-of-sentence inferences, and MLP layers plays a critical role in this process. Based on this hypothesis, we develop 2 novel white-box jailbreak methods: a prompt-specific method and a prompt-general method. The prompt-specific method targets individual prompts and optimizes the attack on the fly, while the prompt-general method is pre-trained offline and can generalize to unseen harmful prompts. Our methods demonstrate robust performance across 7 popular open-source LLMs, size ranging from 2B to 72B. Furthermore, our study provides insights into vulnerabilities of instruction-tuned LLM's safety and deepens the understanding of the internal mechanisms of LLMs.