 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT4CTR: An Efficient Framework to Combine Pre-trained Language Model with Non-textual Features for CTR Prediction
Aug 17, 2023

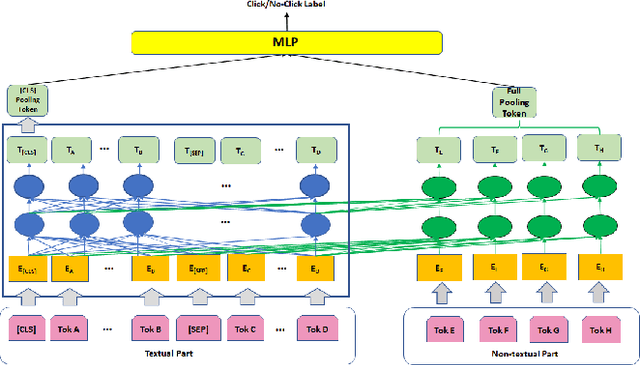
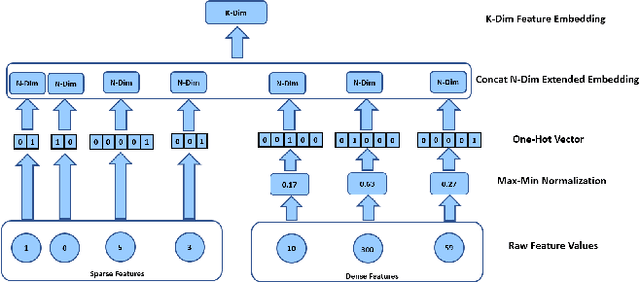
Although deep pre-trained language models have shown promising benefit in a large set of industrial scenarios, including Click-Through-Rate (CTR) prediction, how to integrate pre-trained language models that handle only textual signals into a prediction pipeline with non-textual features is challenging. Up to now two directions have been explored to integrate multi-modal inputs in fine-tuning of pre-trained language models. One consists of fusing the outcome of language models and non-textual features through an aggregation layer, resulting into ensemble framework, where the cross-information between textual and non-textual inputs are only learned in the aggregation layer. The second one consists of splitting non-textual features into fine-grained fragments and transforming the fragments to new tokens combined with textual ones, so that they can be fed directly to transformer layers in language models. However, this approach increases the complexity of the learning and inference because of the numerous additional tokens. To address these limitations, we propose in this work a novel framework BERT4CTR, with the Uni-Attention mechanism that can benefit from the interactions between non-textual and textual features while maintaining low time-costs in training and inference through a dimensionality reduction. Comprehensive experiments on both public and commercial data demonstrate that BERT4CTR can outperform significantly the state-of-the-art frameworks to handle multi-modal inputs and be applicable to CTR prediction.
Constraint-aware and Ranking-distilled Token Pruning for Efficient Transformer Inference
Jun 26, 2023Deploying pre-trained transformer models like BERT on downstream tasks in resource-constrained scenarios is challenging due to their high inference cost, which grows rapidly with input sequence length. In this work, we propose a constraint-aware and ranking-distilled token pruning method ToP, which selectively removes unnecessary tokens as input sequence passes through layers, allowing the model to improve online inference speed while preserving accuracy. ToP overcomes the limitation of inaccurate token importance ranking in the conventional self-attention mechanism through a ranking-distilled token distillation technique, which distills effective token rankings from the final layer of unpruned models to early layers of pruned models. Then, ToP introduces a coarse-to-fine pruning approach that automatically selects the optimal subset of transformer layers and optimizes token pruning decisions within these layers through improved $L_0$ regularization. Extensive experiments on GLUE benchmark and SQuAD tasks demonstrate that ToP outperforms state-of-the-art token pruning and model compression methods with improved accuracy and speedups. ToP reduces the average FLOPs of BERT by 8.1x while achieving competitive accuracy on GLUE, and provides a real latency speedup of up to 7.4x on an Intel CPU.