 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Label Assignments Learning by Dynamic Sample Dropout Combined with Layer-wise Optimization in Speech Separation
Paper and Code
Nov 20, 2023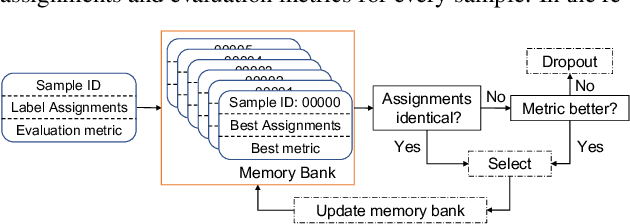
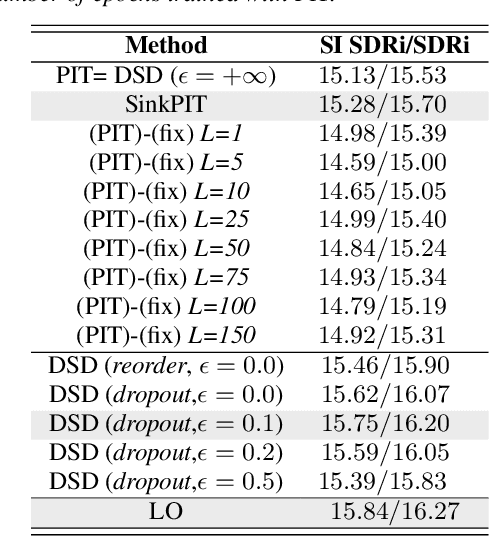
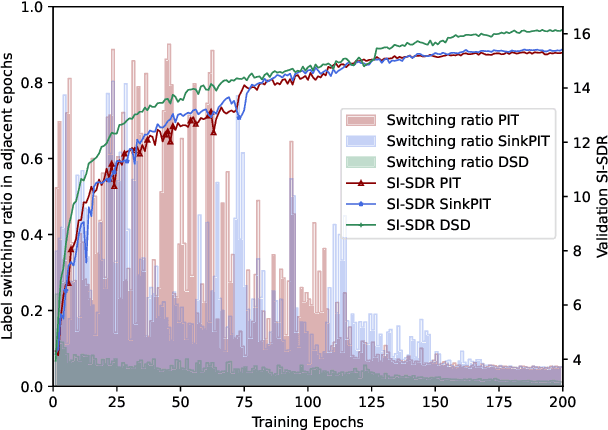
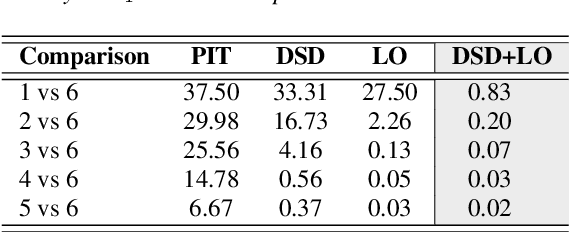
In supervised speech separation, permutation invariant training (PIT) is widely used to handle label ambiguity by selecting the best permutation to update the model. Despite its success, previous studies showed that PIT is plagued by excessive label assignment switching in adjacent epochs, impeding the model to learn better label assignments. To address this issue, we propose a novel training strategy, dynamic sample dropout (DSD), which considers previous best label assignments and evaluation metrics to exclude the samples that may negatively impact the learned label assignments during training. Additionally, we include layer-wise optimization (LO) to improve the performance by solving layer-decoupling. Our experiments showed that combining DSD and LO outperforms the baseline and solves excessive label assignment switching and layer-decoupling issues. The proposed DSD and LO approach is easy to implement, requires no extra training sets or steps, and shows generality to various speech separation tasks.