 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Is a Good Caption? A Comprehensive Visual Caption Benchmark for Evaluating Both Correctness and Coverage of MLLMs
Paper and Code
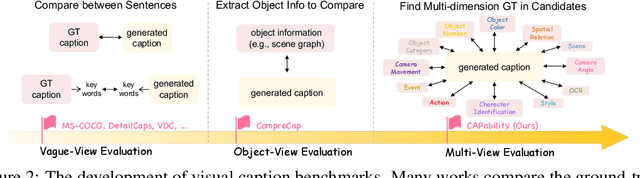
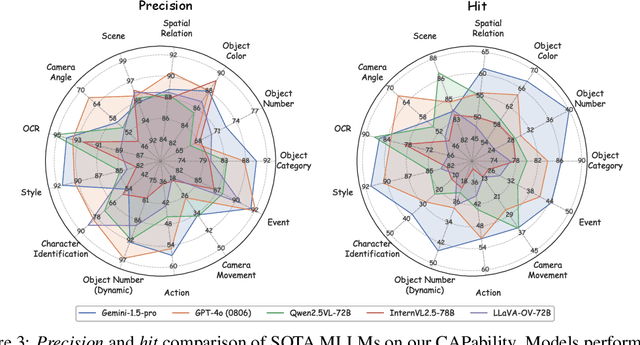


Recent advancements in Multimodal Large Language Models (MLLMs) have rendered traditional visual captioning benchmarks obsolete, as they primarily evaluate short descriptions with outdated metrics. While recent benchmarks address these limitations by decomposing captions into visual elements and adopting model-based evaluation, they remain incomplete-overlooking critical aspects, while providing vague, non-explanatory scores. To bridge this gap, we propose CV-CapBench, a Comprehensive Visual Caption Benchmark that systematically evaluates caption quality across 6 views and 13 dimensions. CV-CapBench introduces precision, recall, and hit rate metrics for each dimension, uniquely assessing both correctness and coverage. Experiments on leading MLLMs reveal significant capability gaps, particularly in dynamic and knowledge-intensive dimensions. These findings provide actionable insights for future research. The code and data will be released.