 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to Forget? Complexity Trade-offs in Machine Unlearning
Feb 24, 2025Machine Unlearning (MU) aims at removing the influence of specific data points from a trained model, striving to achieve this at a fraction of the cost of full model retraining. In this paper, we analyze the efficiency of unlearning methods and establish the first upper and lower bounds on minimax computation times for this problem, characterizing the performance of the most efficient algorithm against the most difficult objective function. Specifically, for strongly convex objective functions and under the assumption that the forget data is inaccessible to the unlearning method, we provide a phase diagram for the unlearning complexity ratio -- a novel metric that compares the computational cost of the best unlearning method to full model retraining. The phase diagram reveals three distinct regimes: one where unlearning at a reduced cost is infeasible, another where unlearning is trivial because adding noise suffices, and a third where unlearning achieves significant computational advantages over retraining. These findings highlight the critical role of factors such as data dimensionality, the number of samples to forget, and privacy constraints in determining the practical feasibility of unlearning.
A primal-dual data-driven method for computational optical imaging with a photonic lantern
Jun 20, 2023



Optical fibres aim to image in-vivo biological processes. In this context, high spatial resolution and stability to fibre movements are key to enable decision-making processes (e.g., for microendoscopy). Recently, a single-pixel imaging technique based on a multicore fibre photonic lantern has been designed, named computational optical imaging using a lantern (COIL). A proximal algorithm based on a sparsity prior, dubbed SARA-COIL, has been further proposed to enable image reconstructions for high resolution COIL microendoscopy. In this work, we develop a data-driven approach for COIL. We replace the sparsity prior in the proximal algorithm by a learned denoiser, leading to a plug-and-play (PnP) algorithm. We use recent results in learning theory to train a network with desirable Lipschitz properties. We show that the resulting primal-dual PnP algorithm converges to a solution to a monotone inclusion problem. Our simulations highlight that the proposed data-driven approach improves the reconstruction quality over variational SARA-COIL method on both simulated and real data.
On the pitfalls of entropy-based uncertainty for multi-class semi-supervised segmentation
Mar 07, 2022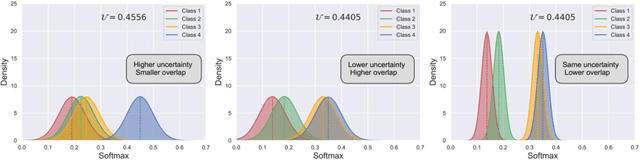

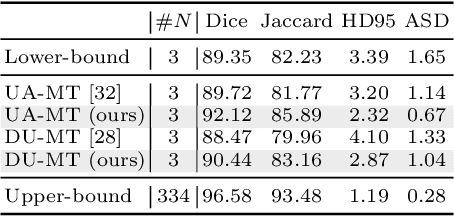
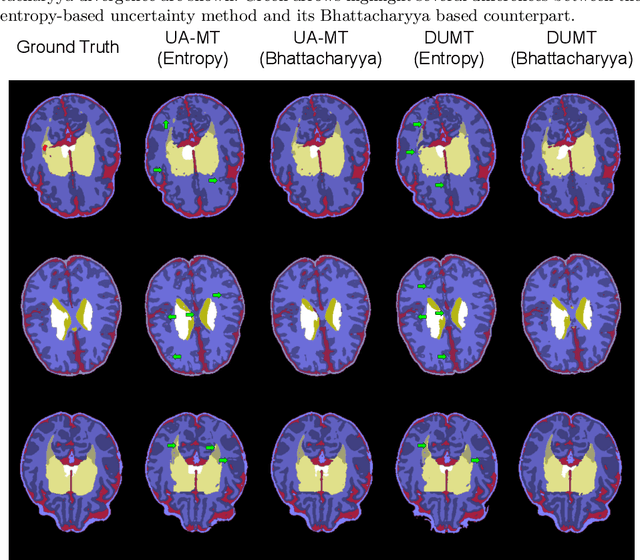
Semi-supervised learning has emerged as an appealing strategy to train deep models with limited supervision. Most prior literature under this learning paradigm resorts to dual-based architectures, typically composed of a teacher-student duple. To drive the learning of the student, many of these models leverage the aleatoric uncertainty derived from the entropy of the predictions. While this has shown to work well in a binary scenario, we demonstrate in this work that this strategy leads to suboptimal results in a multi-class context, a more realistic and challenging setting. We argue, indeed, that these approaches underperform due to the erroneous uncertainty approximations in the presence of inter-class overlap. Furthermore, we propose an alternative solution to compute the uncertainty in a multi-class setting, based on divergence distances and which account for inter-class overlap. We evaluate the proposed solution on a challenging multi-class segmentation dataset and in two well-known uncertainty-based segmentation methods. The reported results demonstrate that by simply replacing the mechanism used to compute the uncertainty, our proposed solution brings substantial improvement on tested setups.