 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Many Different Outputs Can a Transformer Generate?
May 21, 2026We study how we can leverage only a handful of characteristics of a transformer's architecture to closely predict the number of different sequences it can output, both qualitatively and quantitatively. We provide an upper bound depending on the length of the prompt, which we show empirically to be tight up to a factor less than 10, across architectures and model sizes. Our analysis also provides a theoretical explanation for previously observed empirical failures of transformers on simple sequence tasks, such as copying and cramming. Formally, we prove that (i) the maximal length of accessible sequences (those that the transformer can output for some prompt) grows linearly with the prompt length, (ii) beyond a critical threshold, the proportion of accessible sequences decays exponentially with sequence length, and (iii) the linear coefficient relating prompt length to accessible sequence length admits a theoretical upper bound. Notably, these results hold even with unbounded context and computation time.
Online Learning-to-Defer with Varying Experts
May 12, 2026Learning-to-Defer (L2D) methods route each query either to a predictive model or to external experts. While existing work studies this problem in batch settings, real-world deployments require handling streaming data, changing expert availability, and shifting expert distribution. We introduce the first online L2D algorithm for multiclass classification with bandit feedback and a dynamically varying pool of experts. Our method achieves regret guarantees of $O((n+n_e)T^{2/3})$ in general and $O((n+n_e)\sqrt{T})$ under a low-noise condition, where $T$ is the time horizon, $n$ is the number of labels, and $n_e$ is the number of distinct experts observed across rounds. The analysis builds on novel $\mathcal{H}$-consistency bounds for the online framework, combined with first-order methods for online convex optimization. Experiments on synthetic and real-world datasets demonstrate that our approach effectively extends standard Learning-to-Defer to settings with varying expert availability and reliability.
Distilling Human-Aligned Privacy Sensitivity Assessment from Large Language Models
Mar 31, 2026Accurate privacy evaluation of textual data remains a critical challenge in privacy-preserving natural language processing. Recent work has shown that large language models (LLMs) can serve as reliable privacy evaluators, achieving strong agreement with human judgments; however, their computational cost and impracticality for processing sensitive data at scale limit real-world deployment. We address this gap by distilling the privacy assessment capabilities of Mistral Large 3 (675B) into lightweight encoder models with as few as 150M parameters. Leveraging a large-scale dataset of privacy-annotated texts spanning 10 diverse domains, we train efficient classifiers that preserve strong agreement with human annotations while dramatically reducing computational requirements. We validate our approach on human-annotated test data and demonstrate its practical utility as an evaluation metric for de-identification systems.
Adaptive Text Anonymization: Learning Privacy-Utility Trade-offs via Prompt Optimization
Feb 24, 2026Anonymizing textual documents is a highly context-sensitive problem: the appropriate balance between privacy protection and utility preservation varies with the data domain, privacy objectives, and downstream application. However, existing anonymization methods rely on static, manually designed strategies that lack the flexibility to adjust to diverse requirements and often fail to generalize across domains. We introduce adaptive text anonymization, a new task formulation in which anonymization strategies are automatically adapted to specific privacy-utility requirements. We propose a framework for task-specific prompt optimization that automatically constructs anonymization instructions for language models, enabling adaptation to different privacy goals, domains, and downstream usage patterns. To evaluate our approach, we present a benchmark spanning five datasets with diverse domains, privacy constraints, and utility objectives. Across all evaluated settings, our framework consistently achieves a better privacy-utility trade-off than existing baselines, while remaining computationally efficient and effective on open-source language models, with performance comparable to larger closed-source models. Additionally, we show that our method can discover novel anonymization strategies that explore different points along the privacy-utility trade-off frontier.
Tau-Eval: A Unified Evaluation Framework for Useful and Private Text Anonymization
Jun 06, 2025Text anonymization is the process of removing or obfuscating information from textual data to protect the privacy of individuals. This process inherently involves a complex trade-off between privacy protection and information preservation, where stringent anonymization methods can significantly impact the text's utility for downstream applications. Evaluating the effectiveness of text anonymization proves challenging from both privacy and utility perspectives, as there is no universal benchmark that can comprehensively assess anonymization techniques across diverse, and sometimes contradictory contexts. We present Tau-Eval, an open-source framework for benchmarking text anonymization methods through the lens of privacy and utility task sensitivity. A Python library, code, documentation and tutorials are publicly available.
Online Learning of Pure States is as Hard as Mixed States
Feb 02, 2025



Quantum state tomography, the task of learning an unknown quantum state, is a fundamental problem in quantum information. In standard settings, the complexity of this problem depends significantly on the type of quantum state that one is trying to learn, with pure states being substantially easier to learn than general mixed states. A natural question is whether this separation holds for any quantum state learning setting. In this work, we consider the online learning framework and prove the surprising result that learning pure states in this setting is as hard as learning mixed states. More specifically, we show that both classes share almost the same sequential fat-shattering dimension, leading to identical regret scaling under the $L_1$-loss. We also generalize previous results on full quantum state tomography in the online setting to learning only partially the density matrix, using smooth analysis.
TAROT: Task-Oriented Authorship Obfuscation Using Policy Optimization Methods
Jul 31, 2024



Authorship obfuscation aims to disguise the identity of an author within a text by altering the writing style, vocabulary, syntax, and other linguistic features associated with the text author. This alteration needs to balance privacy and utility. While strong obfuscation techniques can effectively hide the author's identity, they often degrade the quality and usefulness of the text for its intended purpose. Conversely, maintaining high utility tends to provide insufficient privacy, making it easier for an adversary to de-anonymize the author. Thus, achieving an optimal trade-off between these two conflicting objectives is crucial. In this paper, we propose TAROT: Task-Oriented Authorship Obfuscation Using Policy Optimization, a new unsupervised authorship obfuscation method whose goal is to optimize the privacy-utility trade-off by regenerating the entire text considering its downstream utility. Our approach leverages policy optimization as a fine-tuning paradigm over small language models in order to rewrite texts by preserving author identity and downstream task utility. We show that our approach largely reduce the accuracy of attackers while preserving utility. We make our code and models publicly available.
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
Text Data Augmentation: Towards better detection of spear-phishing emails
Jul 04, 2020
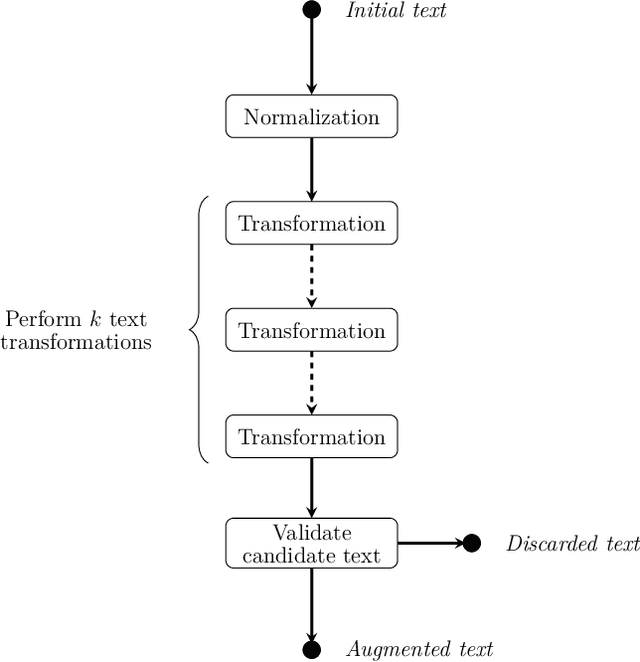
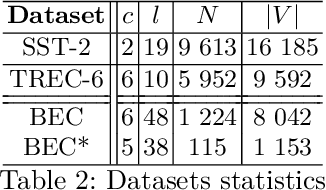
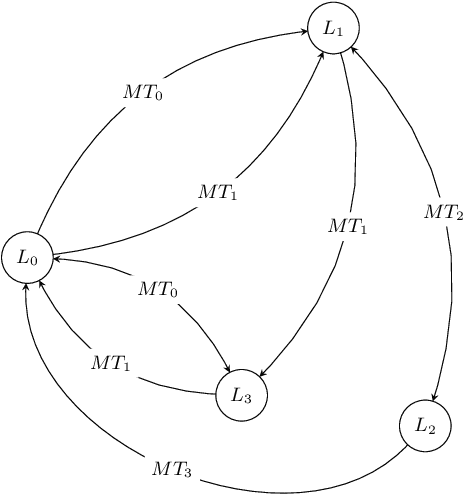
Text data augmentation, i.e. the creation of synthetic textual data from an original text, is challenging as augmentation transformations should take into account language complexity while being relevant to the target Natural Language Processing (NLP) task (e.g. Machine Translation, Question Answering, Text Classification, etc.). Motivated by a business application of Business Email Compromise (BEC) detection, we propose a corpus and task agnostic text augmentation framework combining different methods, utilizing BERT language model, multi-step back-translation and heuristics. We show that our augmentation framework improves performances on several text classification tasks using publicly available models and corpora (SST2 and TREC) as well as on a BEC detection task. We also provide a comprehensive argumentation about the limitations of our augmentation framework.