 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayout-to-Image Generation with Localized Descriptions using ControlNet with Cross-Attention Control
Paper and Code
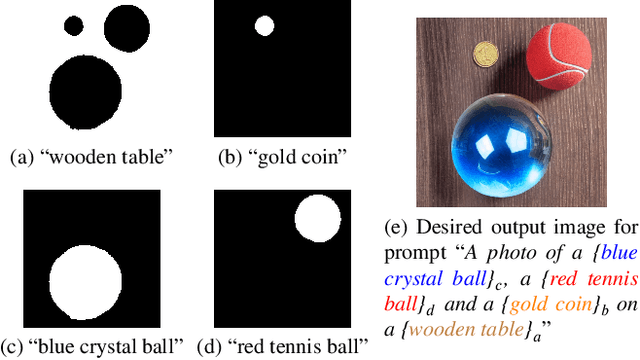
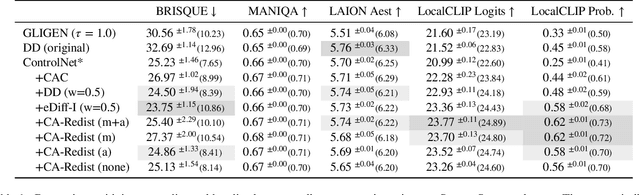
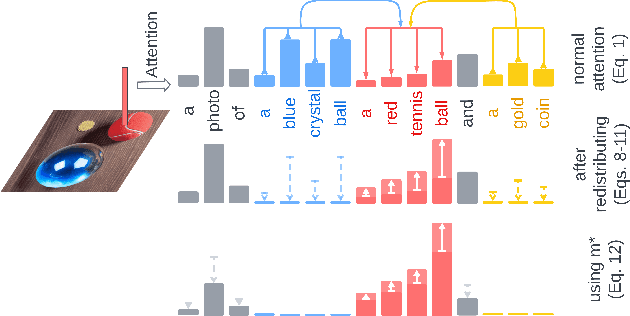
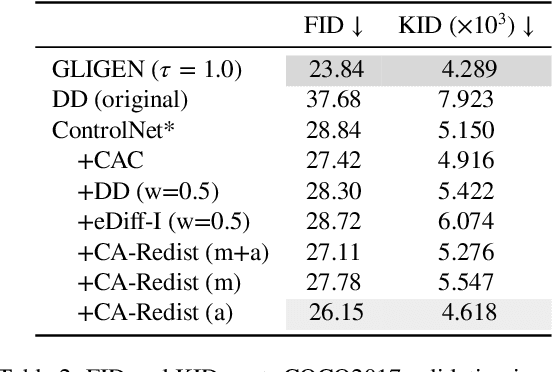
While text-to-image diffusion models can generate highquality images from textual descriptions, they generally lack fine-grained control over the visual composition of the generated images. Some recent works tackle this problem by training the model to condition the generation process on additional input describing the desired image layout. Arguably the most popular among such methods, ControlNet, enables a high degree of control over the generated image using various types of conditioning inputs (e.g. segmentation maps). However, it still lacks the ability to take into account localized textual descriptions that indicate which image region is described by which phrase in the prompt. In this work, we show the limitations of ControlNet for the layout-to-image task and enable it to use localized descriptions using a training-free approach that modifies the crossattention scores during generation. We adapt and investigate several existing cross-attention control methods in the context of ControlNet and identify shortcomings that cause failure (concept bleeding) or image degradation under specific conditions. To address these shortcomings, we develop a novel cross-attention manipulation method in order to maintain image quality while improving control. Qualitative and quantitative experimental studies focusing on challenging cases are presented, demonstrating the effectiveness of the investigated general approach, and showing the improvements obtained by the proposed cross-attention control method.