 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic gradient descent with gradient estimator for categorical features
Paper and Code
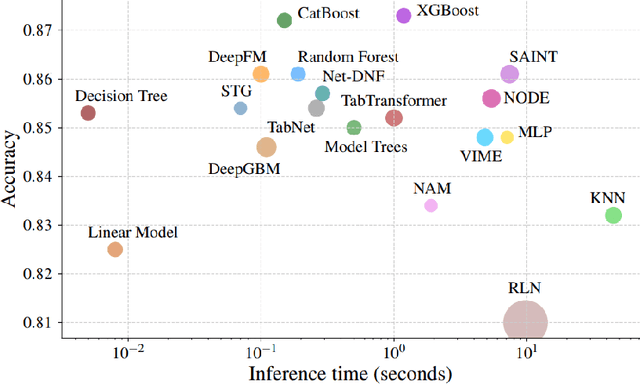
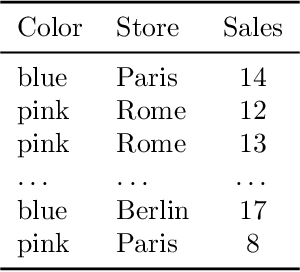
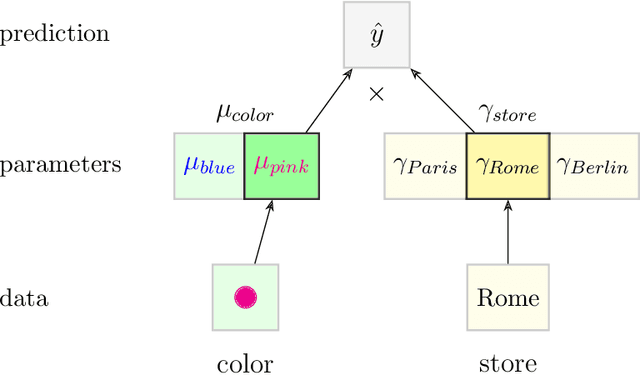

Categorical data are present in key areas such as health or supply chain, and this data require specific treatment. In order to apply recent machine learning models on such data, encoding is needed. In order to build interpretable models, one-hot encoding is still a very good solution, but such encoding creates sparse data. Gradient estimators are not suited for sparse data: the gradient is mainly considered as zero while it simply does not always exists, thus a novel gradient estimator is introduced. We show what this estimator minimizes in theory and show its efficiency on different datasets with multiple model architectures. This new estimator performs better than common estimators under similar settings. A real world retail dataset is also released after anonymization. Overall, the aim of this paper is to thoroughly consider categorical data and adapt models and optimizers to these key features.