 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA syllable based model for handwriting recognition
Paper and Code
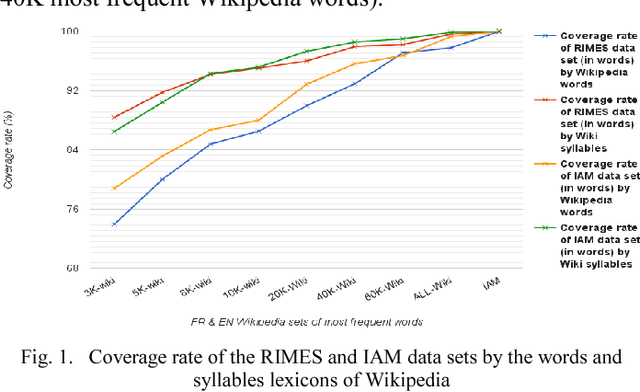
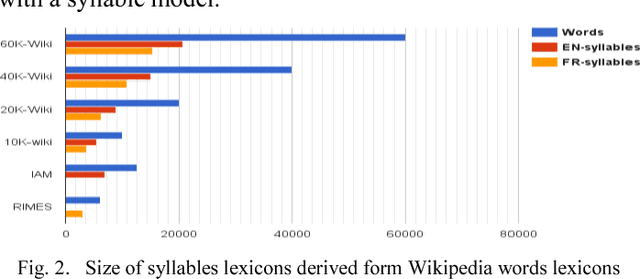
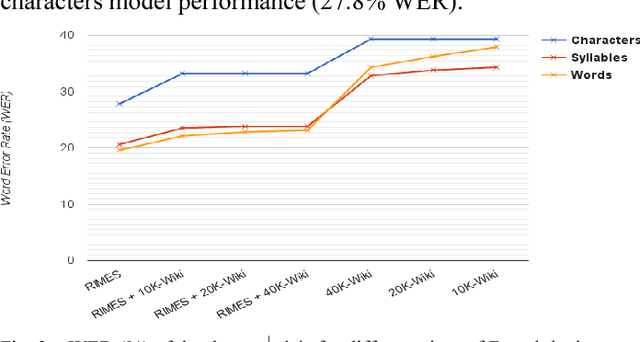
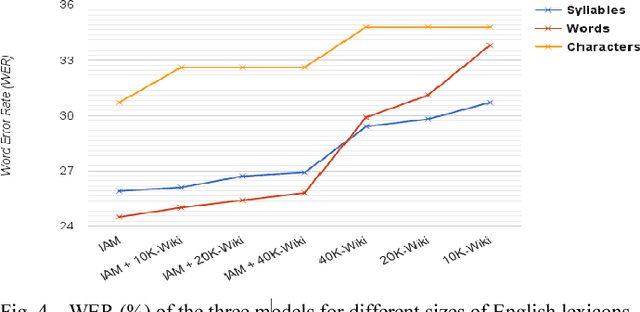
In this paper, we introduce a new modeling approach of texts for handwriting recognition based on syllables. We propose a supervised syllabification approach for the French and English languages for building a vocabulary of syllables. Statistical n-gram language models of syllables are trained on French and English Wikipedia corpora. The handwriting recognition system, based on optical HMM context independent character models, performs a two pass decoding, integrating the proposed syllabic models. Evaluation is carried out on the French RIMES dataset and English IAM dataset by analyzing the performance for various coverage of the syllable models. We also compare the syllable models with lexicon and character n-gram models. The proposed approach reaches interesting performances thanks to its capacity to cover a large amount of out of vocabulary words working with a limited amount of syllables combined with statistical n-gram of reasonable order.