 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Multilingual Handwriting Recognition System using multigrams sub-lexical units
Paper and Code
Aug 28, 2018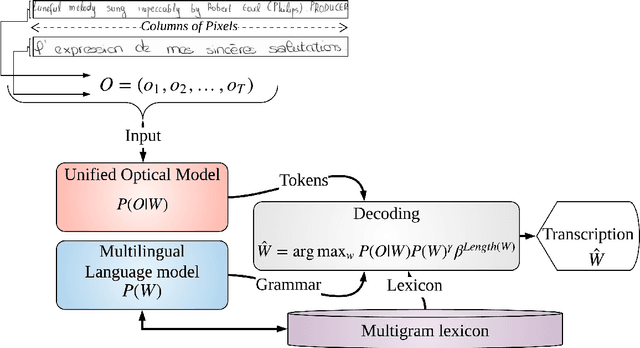

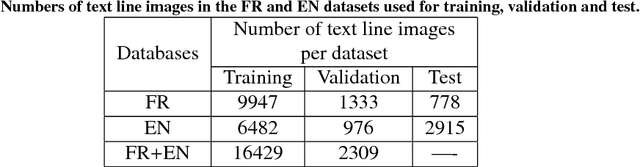
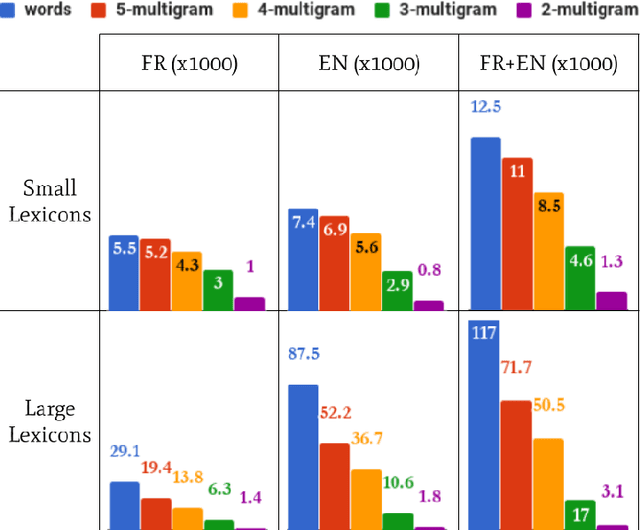
We address the design of a unified multilingual system for handwriting recognition. Most of multi- lingual systems rests on specialized models that are trained on a single language and one of them is selected at test time. While some recognition systems are based on a unified optical model, dealing with a unified language model remains a major issue, as traditional language models are generally trained on corpora composed of large word lexicons per language. Here, we bring a solution by con- sidering language models based on sub-lexical units, called multigrams. Dealing with multigrams strongly reduces the lexicon size and thus decreases the language model complexity. This makes pos- sible the design of an end-to-end unified multilingual recognition system where both a single optical model and a single language model are trained on all the languages. We discuss the impact of the language unification on each model and show that our system reaches state-of-the-art methods perfor- mance with a strong reduction of the complexity.