 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Differential Privacy for Bayesian Optimization
Paper and Code
Oct 13, 2020
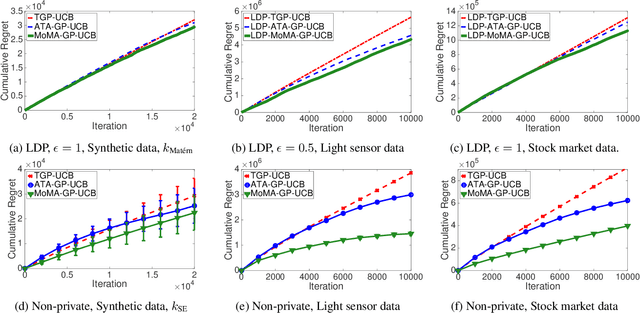
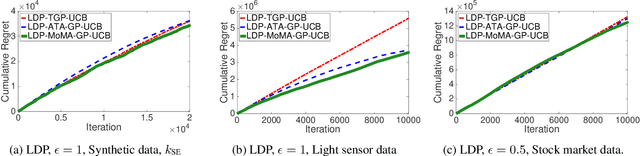
Motivated by the increasing concern about privacy in nowadays data-intensive online learning systems, we consider a black-box optimization in the nonparametric Gaussian process setting with local differential privacy (LDP) guarantee. Specifically, the rewards from each user are further corrupted to protect privacy and the learner only has access to the corrupted rewards to minimize the regret. We first derive the regret lower bounds for any LDP mechanism and any learning algorithm. Then, we present three almost optimal algorithms based on the GP-UCB framework and Laplace DP mechanism. In this process, we also propose a new Bayesian optimization (BO) method (called MoMA-GP-UCB) based on median-of-means techniques and kernel approximations, which complements previous BO algorithms for heavy-tailed payoffs with a reduced complexity. Further, empirical comparisons of different algorithms on both synthetic and real-world datasets highlight the superior performance of MoMA-GP-UCB in both private and non-private scenarios.