Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwitched linear encoding with rectified linear autoencoders
Paper and Code
Jan 19, 2013

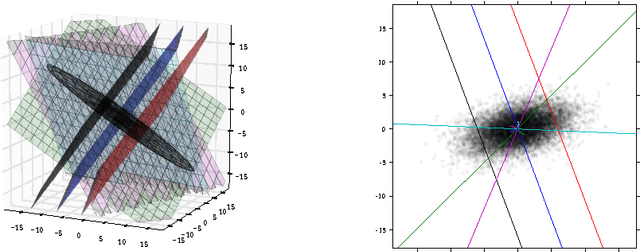
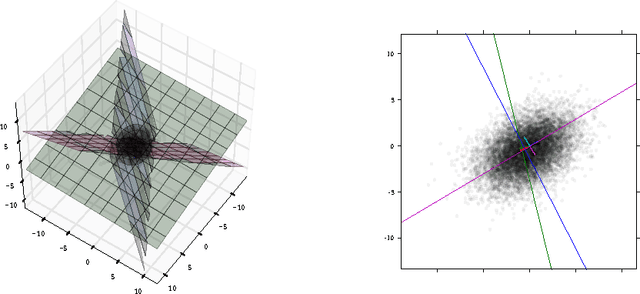
Several recent results in machine learning have established formal connections between autoencoders---artificial neural network models that attempt to reproduce their inputs---and other coding models like sparse coding and K-means. This paper explores in depth an autoencoder model that is constructed using rectified linear activations on its hidden units. Our analysis builds on recent results to further unify the world of sparse linear coding models. We provide an intuitive interpretation of the behavior of these coding models and demonstrate this intuition using small, artificial datasets with known distributions.
View paper on