 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Single: A Data Selection Principle for LLM Alignment via Fine-Grained Preference Signals
Aug 11, 2025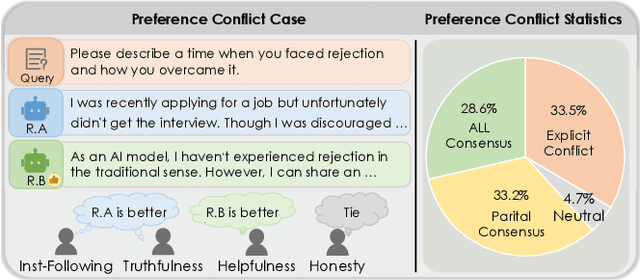
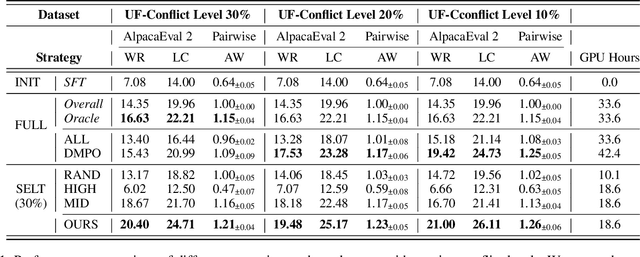
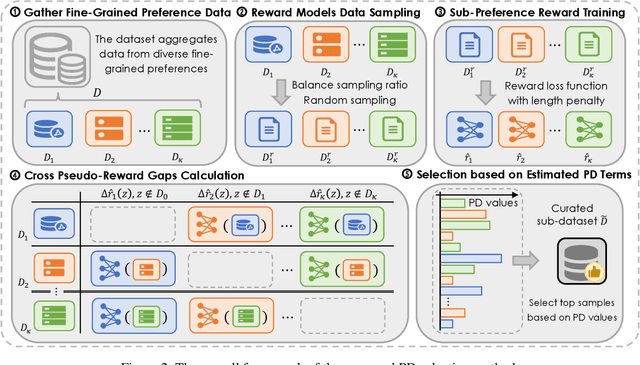
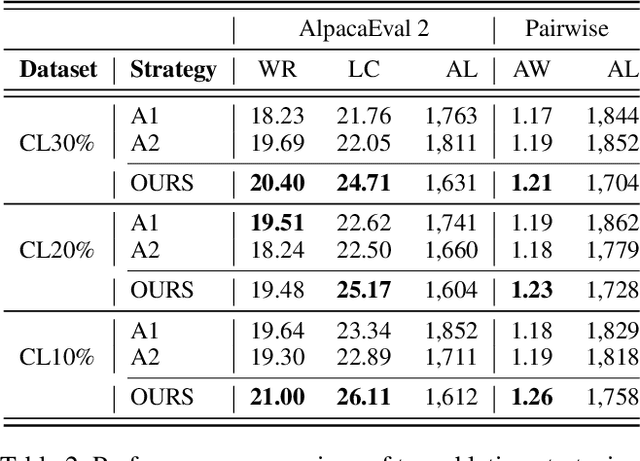
Aligning Large Language Models (LLMs) with diverse human values requires moving beyond a single holistic "better-than" preference criterion. While collecting fine-grained, aspect-specific preference data is more reliable and scalable, existing methods like Direct Preference Optimization (DPO) struggle with the severe noise and conflicts inherent in such aggregated datasets. In this paper, we tackle this challenge from a data-centric perspective. We first derive the Direct Multi-Preference Optimization (DMPO) objective, and uncover a key Preference Divergence (PD) term that quantifies inter-aspect preference conflicts. Instead of using this term for direct optimization, we leverage it to formulate a novel, theoretically-grounded data selection principle. Our principle advocates for selecting a subset of high-consensus data-identified by the most negative PD values-for efficient DPO training. We prove the optimality of this strategy by analyzing the loss bounds of the DMPO objective in the selection problem. To operationalize our approach, we introduce practical methods of PD term estimation and length bias mitigation, thereby proposing our PD selection method. Evaluation on the UltraFeedback dataset with three varying conflict levels shows that our simple yet effective strategy achieves over 10% relative improvement against both the standard holistic preference and a stronger oracle using aggregated preference signals, all while boosting training efficiency and obviating the need for intractable holistic preference annotating, unlocking the potential of robust LLM alignment via fine-grained preference signals.
D3: Diversity, Difficulty, and Dependability-Aware Data Selection for Sample-Efficient LLM Instruction Tuning
Mar 14, 2025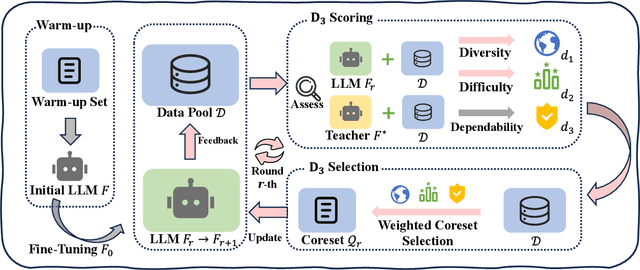
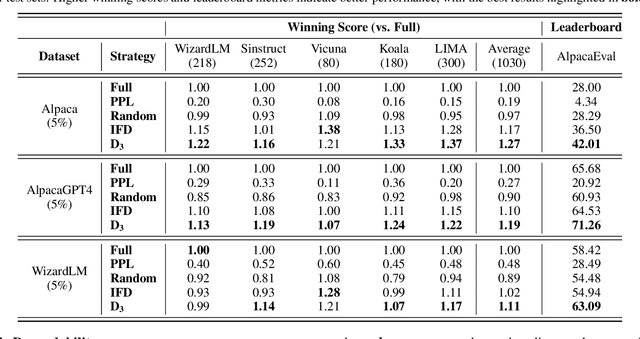
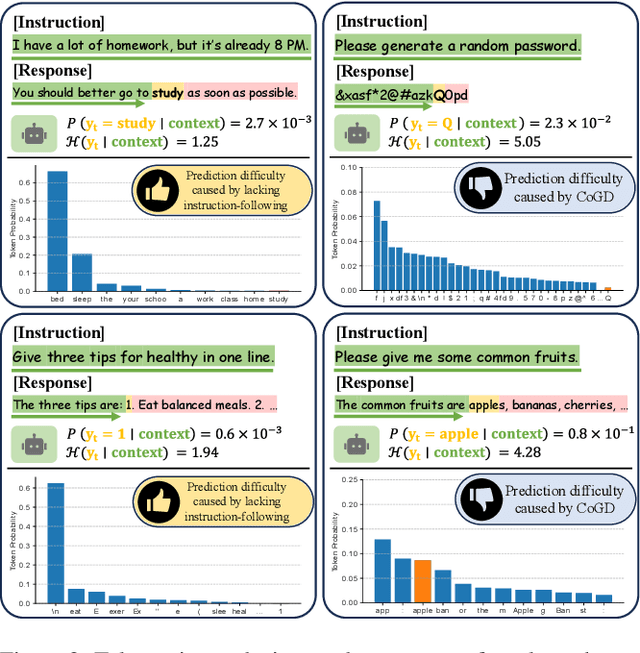
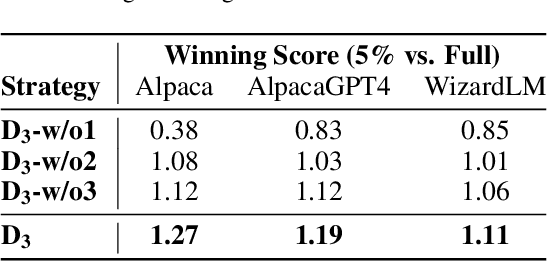
Recent advancements in instruction tuning for large language models (LLMs) suggest that a small, high-quality dataset can significantly equip LLMs with instruction-following capabilities, outperforming large datasets often burdened by quality and redundancy issues. However, the challenge lies in automatically identifying valuable subsets from large datasets to boost both the effectiveness and efficiency of instruction tuning. In this paper, we first establish data selection criteria based on three distinct aspects of data value: diversity, difficulty, and dependability, and then propose the D3 method comprising two key steps of scoring and selection. Specifically, in the scoring step, we define the diversity function to measure sample distinctiveness and introduce the uncertainty-based prediction difficulty to evaluate sample difficulty by mitigating the interference of context-oriented generation diversity. Additionally, we integrate an external LLM for dependability assessment. In the selection step, we formulate the D3 weighted coreset objective, which jointly optimizes three aspects of data value to solve for the most valuable subset. The two steps of D3 can iterate multiple rounds, incorporating feedback to refine the selection focus adaptively. Experiments on three datasets demonstrate the effectiveness of D3 in endowing LLMs with competitive or even superior instruction-following capabilities using less than 10% of the entire dataset.