 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning dissection trajectories from expert surgical videos via imitation learning with equivariant diffusion
Jun 05, 2025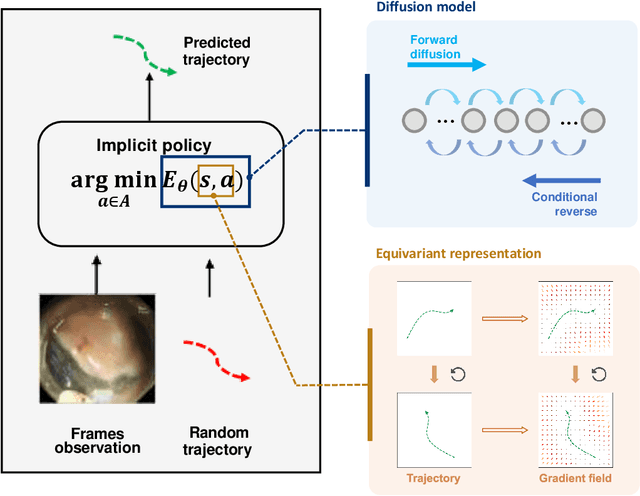
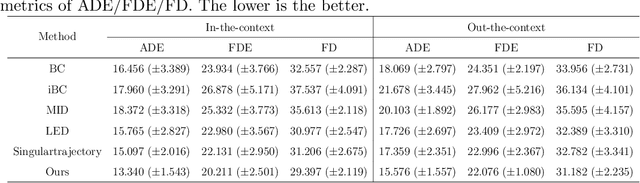
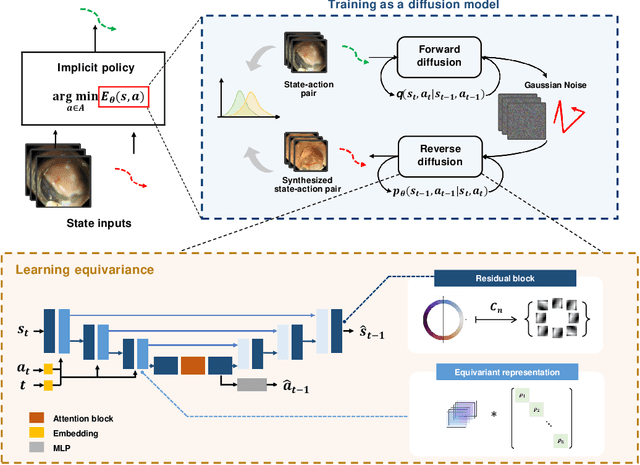
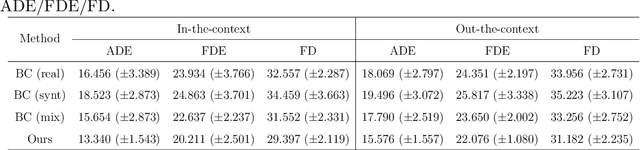
Endoscopic Submucosal Dissection (ESD) is a well-established technique for removing epithelial lesions. Predicting dissection trajectories in ESD videos offers significant potential for enhancing surgical skill training and simplifying the learning process, yet this area remains underexplored. While imitation learning has shown promise in acquiring skills from expert demonstrations, challenges persist in handling uncertain future movements, learning geometric symmetries, and generalizing to diverse surgical scenarios. To address these, we introduce a novel approach: Implicit Diffusion Policy with Equivariant Representations for Imitation Learning (iDPOE). Our method models expert behavior through a joint state action distribution, capturing the stochastic nature of dissection trajectories and enabling robust visual representation learning across various endoscopic views. By incorporating a diffusion model into policy learning, iDPOE ensures efficient training and sampling, leading to more accurate predictions and better generalization. Additionally, we enhance the model's ability to generalize to geometric symmetries by embedding equivariance into the learning process. To address state mismatches, we develop a forward-process guided action inference strategy for conditional sampling. Using an ESD video dataset of nearly 2000 clips, experimental results show that our approach surpasses state-of-the-art methods, both explicit and implicit, in trajectory prediction. To the best of our knowledge, this is the first application of imitation learning to surgical skill development for dissection trajectory prediction.
Discriminative Speaker Representation via Contrastive Learning with Class-Aware Attention in Angular Space
Nov 17, 2022



The challenges in applying contrastive learning to speaker verification (SV) are that the softmax-based contrastive loss lacks discriminative power and that the hard negative pairs can easily influence learning. To overcome these challenges, we propose a contrastive learning SV framework incorporating an additive angular margin into the supervised contrastive loss. The margin improves the speaker representation's discrimination ability. We introduce a class-aware attention mechanism through which hard negative samples contribute less significantly to the supervised contrastive loss. We also employed a gradient-based multi-objective optimization approach to balance the classification and contrastive loss. Experimental results on CN-Celeb and Voxceleb1 show that this new learning objective can cause the encoder to find an embedding space that exhibits great speaker discrimination across languages.