 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrated Planning and Control of Robotic Surgical Instruments for Tasks Autonomy
May 13, 2023Agile maneuvers are essential for robot-enabled complex tasks such as surgical procedures. Prior explorations on surgery autonomy are limited to feasibility study of completing a single task without systematically addressing generic manipulation safety across different tasks. We present an integrated planning and control framework for 6-DoF robotic instruments for pipeline automation of surgical tasks.We leverage the geometry of a robotic instrument and propose the nodal state space (NSS) to represent the robot state in SE(3) space. Each elementary robot motion could be encoded by regulation of the state parameters via a dynamical system. This theoretically ensures that every in-process trajectory is globally feasible and stably reached to an admissible target, and the controller is of closed-form without computing 6-DoF inverse kinematics. Then, to plan the motion steps reliably, we propose an interactive (instant) goal state of the robot that transforms manipulation planning through desired path constraints into a goal-varying manipulation (GVM) problem. We detail how GVM could adaptively and smoothly plan the procedure (could proceed or rewind the process as needed) based on on-the-fly situations under dynamic or disturbed environment. Finally, we extend the above policy to characterize complete pipelines of various surgical tasks. Simulations show that our framework could smoothly solve twisted maneuvers while avoiding collisions. Physical experiments using the da Vinci Research Kit (dVRK) validates the capability of automating individual tasks including tissue debridement, dissection, and wound suturing. The results confirm good task-level consistency and reliability compared to state-of-the-art automation algorithms.
Modal-Graph 3D Shape Servoing of Deformable Objects with Raw Point Clouds
Apr 18, 2023Deformable object manipulation (DOM) with point clouds has great potential as non-rigid 3D shapes can be measured without detecting and tracking image features. However, robotic shape control of deformable objects with point clouds is challenging due to: the unknown point-wise correspondences and the noisy partial observability of raw point clouds; the modeling difficulties of the relationship between point clouds and robot motions. To tackle these challenges, this paper introduces a novel modal-graph framework for the model-free shape servoing of deformable objects with raw point clouds. Unlike the existing works studying the object's geometry structure, our method builds a low-frequency deformation structure for the DOM system, which is robust to the measurement irregularities. The built modal representation and graph structure enable us to directly extract low-dimensional deformation features from raw point clouds. Such extraction requires no extra point processing of registrations, refinements, and occlusion removal. Moreover, to shape the object using the extracted features, we design an adaptive robust controller which is proved to be input-to-state stable (ISS) without offline learning or identifying both the physical and geometric object models. Extensive simulations and experiments are conducted to validate the effectiveness of our method for linear, planar, tubular, and solid objects under different settings.
Distilled Visual and Robot Kinematics Embeddings for Metric Depth Estimation in Monocular Scene Reconstruction
Nov 27, 2022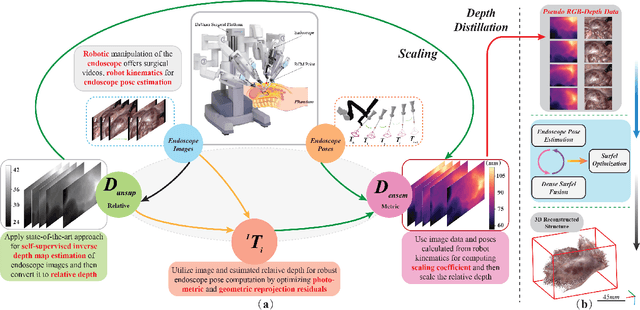
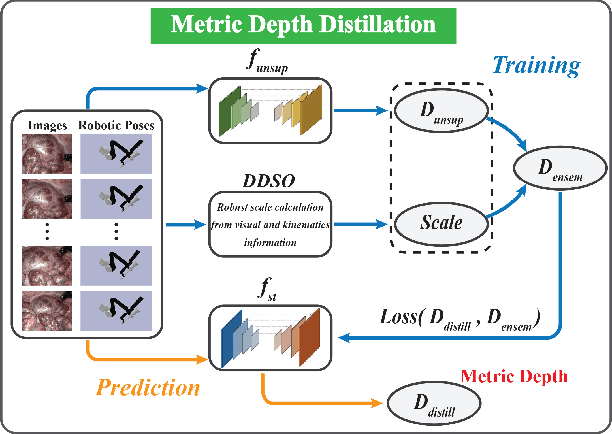
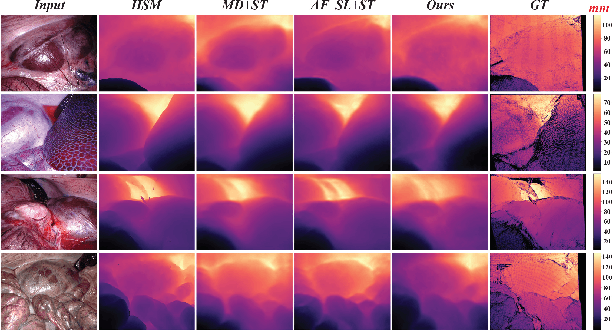

Estimating precise metric depth and scene reconstruction from monocular endoscopy is a fundamental task for surgical navigation in robotic surgery. However, traditional stereo matching adopts binocular images to perceive the depth information, which is difficult to transfer to the soft robotics-based surgical systems due to the use of monocular endoscopy. In this paper, we present a novel framework that combines robot kinematics and monocular endoscope images with deep unsupervised learning into a single network for metric depth estimation and then achieve 3D reconstruction of complex anatomy. Specifically, we first obtain the relative depth maps of surgical scenes by leveraging a brightness-aware monocular depth estimation method. Then, the corresponding endoscope poses are computed based on non-linear optimization of geometric and photometric reprojection residuals. Afterwards, we develop a Depth-driven Sliding Optimization (DDSO) algorithm to extract the scaling coefficient from kinematics and calculated poses offline. By coupling the metric scale and relative depth data, we form a robust ensemble that represents the metric and consistent depth. Next, we treat the ensemble as supervisory labels to train a metric depth estimation network for surgeries (i.e., MetricDepthS-Net) that distills the embeddings from the robot kinematics, endoscopic videos, and poses. With accurate metric depth estimation, we utilize a dense visual reconstruction method to recover the 3D structure of the whole surgical site. We have extensively evaluated the proposed framework on public SCARED and achieved comparable performance with stereo-based depth estimation methods. Our results demonstrate the feasibility of the proposed approach to recover the metric depth and 3D structure with monocular inputs.
AutoLaparo: A New Dataset of Integrated Multi-tasks for Image-guided Surgical Automation in Laparoscopic Hysterectomy
Aug 03, 2022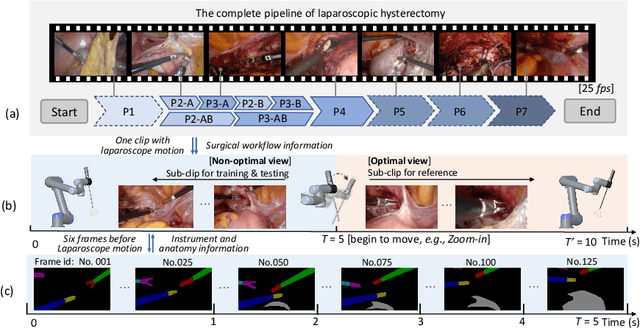

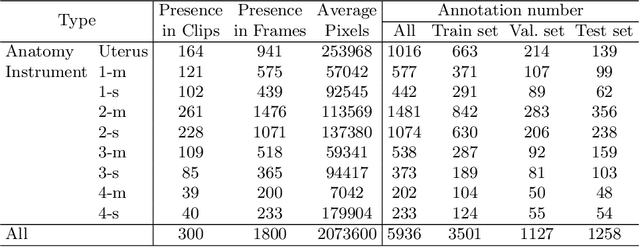

Computer-assisted minimally invasive surgery has great potential in benefiting modern operating theatres. The video data streamed from the endoscope provides rich information to support context-awareness for next-generation intelligent surgical systems. To achieve accurate perception and automatic manipulation during the procedure, learning based technique is a promising way, which enables advanced image analysis and scene understanding in recent years. However, learning such models highly relies on large-scale, high-quality, and multi-task labelled data. This is currently a bottleneck for the topic, as available public dataset is still extremely limited in the field of CAI. In this paper, we present and release the first integrated dataset (named AutoLaparo) with multiple image-based perception tasks to facilitate learning-based automation in hysterectomy surgery. Our AutoLaparo dataset is developed based on full-length videos of entire hysterectomy procedures. Specifically, three different yet highly correlated tasks are formulated in the dataset, including surgical workflow recognition, laparoscope motion prediction, and instrument and key anatomy segmentation. In addition, we provide experimental results with state-of-the-art models as reference benchmarks for further model developments and evaluations on this dataset. The dataset is available at https://autolaparo.github.io.
Model-Free 3D Shape Control of Deformable Objects Using Novel Features Based on Modal Analysis
Jul 04, 2022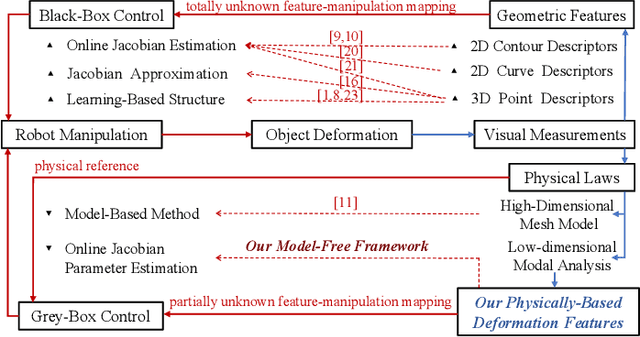
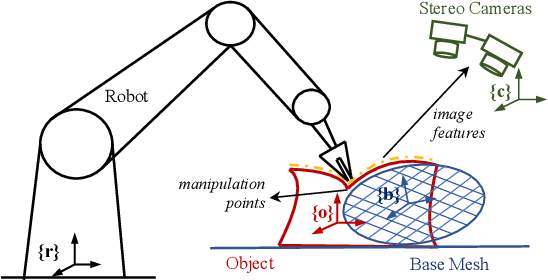
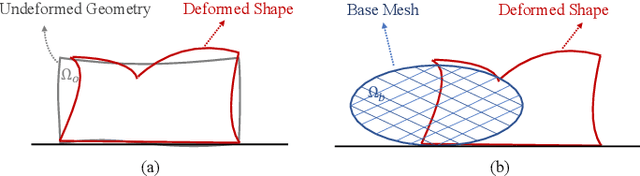

Shape control of deformable objects is a challenging and important robotic problem. This paper proposes a model-free controller using novel 3D global deformation features based on modal analysis. Unlike most existing controllers using geometric features, our controller employs a physically-based deformation feature by decoupling 3D global deformation into low-frequency mode shapes. Although modal analysis is widely adopted in computer vision and simulation, it has not been used in robotic deformation control. We develop a new model-free framework for modal-based deformation control under robot manipulation. Physical interpretation of mode shapes enables us to formulate an analytical deformation Jacobian matrix mapping the robot manipulation onto changes of the modal features. In the Jacobian matrix, unknown geometry and physical properties of the object are treated as low-dimensional modal parameters which can be used to linearly parameterize the closed-loop system. Thus, an adaptive controller with proven stability can be designed to deform the object while online estimating the modal parameters. Simulations and experiments are conducted using linear, planar, and solid objects under different settings. The results not only confirm the superior performance of our controller but also demonstrate its advantages over the baseline method.
A Visual Navigation Perspective for Category-Level Object Pose Estimation
Mar 25, 2022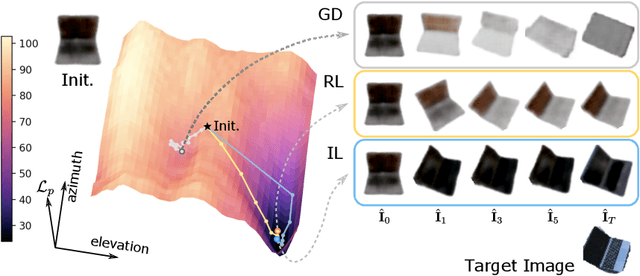

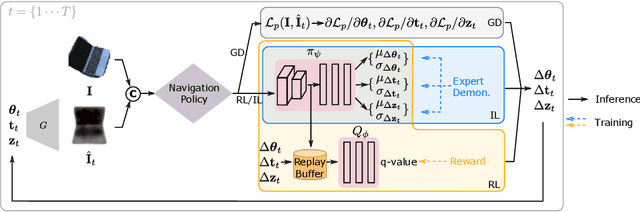

This paper studies category-level object pose estimation based on a single monocular image. Recent advances in pose-aware generative models have paved the way for addressing this challenging task using analysis-by-synthesis. The idea is to sequentially update a set of latent variables, e.g., pose, shape, and appearance, of the generative model until the generated image best agrees with the observation. However, convergence and efficiency are two challenges of this inference procedure. In this paper, we take a deeper look at the inference of analysis-by-synthesis from the perspective of visual navigation, and investigate what is a good navigation policy for this specific task. We evaluate three different strategies, including gradient descent, reinforcement learning and imitation learning, via thorough comparisons in terms of convergence, robustness and efficiency. Moreover, we show that a simple hybrid approach leads to an effective and efficient solution. We further compare these strategies to state-of-the-art methods, and demonstrate superior performance on synthetic and real-world datasets leveraging off-the-shelf pose-aware generative models.
Tele-Operated Oropharyngeal Swab (TOOS) RobotEnabled by TSS Soft Hand for Safe and EffectiveCOVID-19 OP Sampling
Sep 20, 2021



The COVID-19 pandemic has imposed serious challenges in multiple perspectives of human life. To diagnose COVID-19, oropharyngeal swab (OP SWAB) sampling is generally applied for viral nucleic acid (VNA) specimen collection. However, manual sampling exposes medical staff to a high risk of infection. Robotic sampling is promising to mitigate this risk to the minimum level, but traditional robot suffers from safety, cost, and control complexity issues for wide-scale deployment. In this work, we present soft robotic technology is promising to achieve robotic OP swab sampling with excellent swab manipulability in a confined oral space and works as dexterous as existing manual approach. This is enabled by a novel Tstone soft (TSS) hand, consisting of a soft wrist and a soft gripper, designed from human sampling observation and bio-inspiration. TSS hand is in a compact size, exerts larger workspace, and achieves comparable dexterity compared to human hand. The soft wrist is capable of agile omnidirectional bending with adjustable stiffness. The terminal soft gripper is effective for disposable swab pinch and replacement. The OP sampling force is easy to be maintained in a safe and comfortable range (throat sampling comfortable region) under a hybrid motion and stiffness virtual fixture-based controller. A dedicated 3 DOFs RCM platform is used for TSS hand global positioning. Design, modeling, and control of the TSS hand are discussed in detail with dedicated experimental validations. A sampling test based on human tele-operation is processed on the oral cavity model with excellent success rate. The proposed TOOS robot demonstrates a highly promising solution for tele-operated, safe, cost-effective, and quick deployable COVID-19 OP swab sampling.
Adaptive Control for Robotic Manipulation of Deformable Linear Objects with Offline and Online Learning of Unknown Models
Jul 01, 2021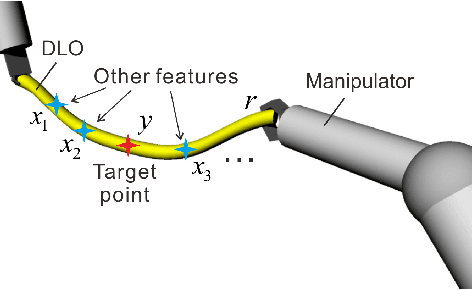
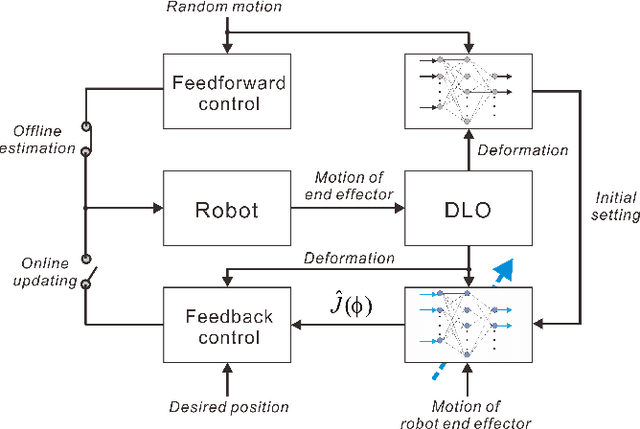
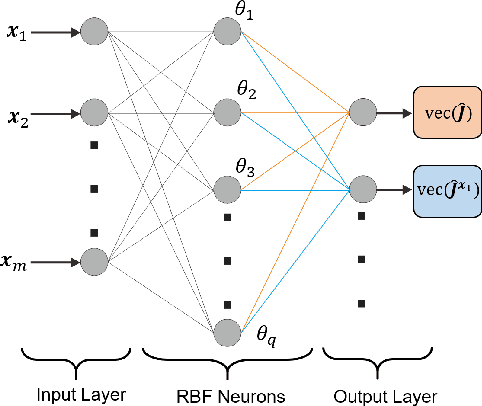
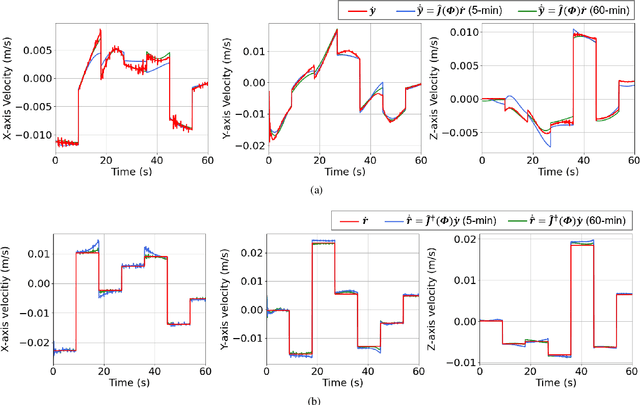
The deformable linear objects (DLOs) are common in both industrial and domestic applications, such as wires, cables, ropes. Because of its highly deformable nature, it is difficult for the robot to reproduce human's dexterous skills on DLOs. In this paper, the unknown deformation model is estimated in both the offline and online manners. The offline learning aims to provide a good approximation prior to the manipulation task, while the online learning aims to compensate the errors due to insufficient training (e.g. limited datasets) in the offline phase. The offline module works by constructing a series of supervised neural networks (NNs), then the online module receives the learning results directly and further updates them with the technique of adaptive NNs. A new adaptive controller is also proposed to allow the robot to perform manipulation tasks concurrently in the online phase. The stability of the closed-loop system and the convergence of task errors are rigorously proved with Lyapunov method. Simulation studies are presented to illustrate the performance of the proposed method.
A data-set of piercing needle through deformable objects for Deep Learning from Demonstrations
Dec 04, 2020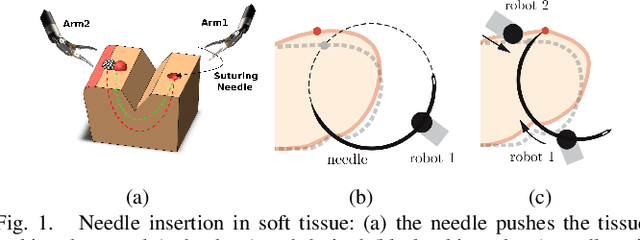
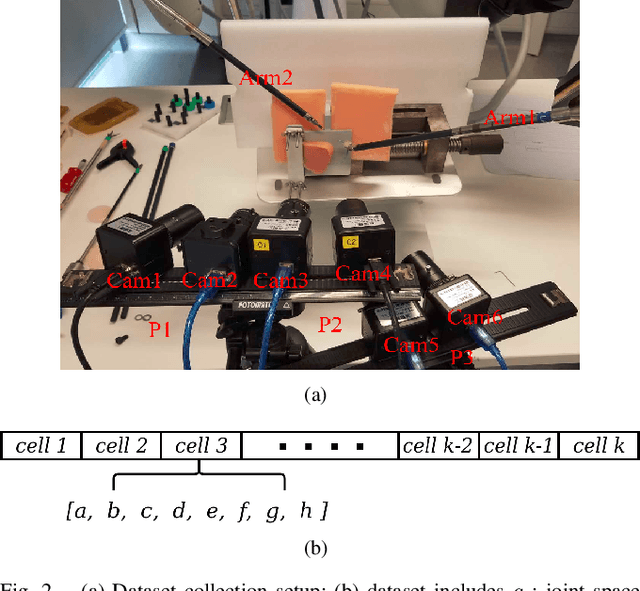

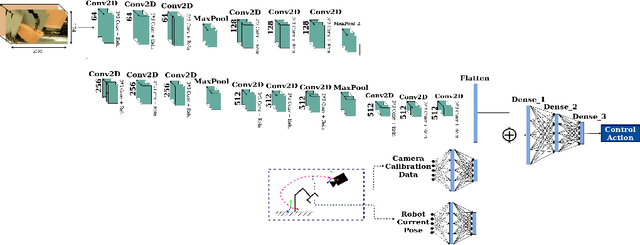
Many robotic tasks are still teleoperated since automating them is very time consuming and expensive. Robot Learning from Demonstrations (RLfD) can reduce programming time and cost. However, conventional RLfD approaches are not directly applicable to many robotic tasks, e.g. robotic suturing with minimally invasive robots, as they require a time-consuming process of designing features from visual information. Deep Neural Networks (DNN) have emerged as useful tools for creating complex models capturing the relationship between high-dimensional observation space and low-level action/state space. Nonetheless, such approaches require a dataset suitable for training appropriate DNN models. This paper presents a dataset of inserting/piercing a needle with two arms of da Vinci Research Kit in/through soft tissues. The dataset consists of (1) 60 successful needle insertion trials with randomised desired exit points recorded by 6 high-resolution calibrated cameras, (2) the corresponding robot data, calibration parameters and (3) the commanded robot control input where all the collected data are synchronised. The dataset is designed for Deep-RLfD approaches. We also implemented several deep RLfD architectures, including simple feed-forward CNNs and different Recurrent Convolutional Networks (RCNs). Our study indicates RCNs improve the prediction accuracy of the model despite that the baseline feed-forward CNNs successfully learns the relationship between the visual information and the next step control actions of the robot. The dataset, as well as our baseline implementations of RLfD, are publicly available for bench-marking at https://github.com/imanlab/d-lfd.