 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModal-Graph 3D Shape Servoing of Deformable Objects with Raw Point Clouds
Apr 18, 2023Deformable object manipulation (DOM) with point clouds has great potential as non-rigid 3D shapes can be measured without detecting and tracking image features. However, robotic shape control of deformable objects with point clouds is challenging due to: the unknown point-wise correspondences and the noisy partial observability of raw point clouds; the modeling difficulties of the relationship between point clouds and robot motions. To tackle these challenges, this paper introduces a novel modal-graph framework for the model-free shape servoing of deformable objects with raw point clouds. Unlike the existing works studying the object's geometry structure, our method builds a low-frequency deformation structure for the DOM system, which is robust to the measurement irregularities. The built modal representation and graph structure enable us to directly extract low-dimensional deformation features from raw point clouds. Such extraction requires no extra point processing of registrations, refinements, and occlusion removal. Moreover, to shape the object using the extracted features, we design an adaptive robust controller which is proved to be input-to-state stable (ISS) without offline learning or identifying both the physical and geometric object models. Extensive simulations and experiments are conducted to validate the effectiveness of our method for linear, planar, tubular, and solid objects under different settings.
StereoPose: Category-Level 6D Transparent Object Pose Estimation from Stereo Images via Back-View NOCS
Nov 03, 2022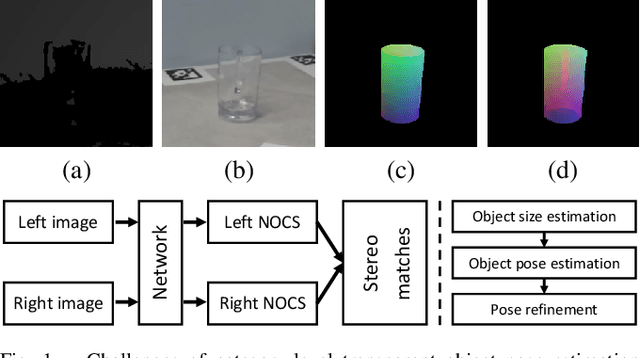
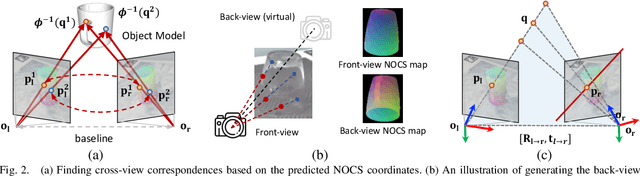
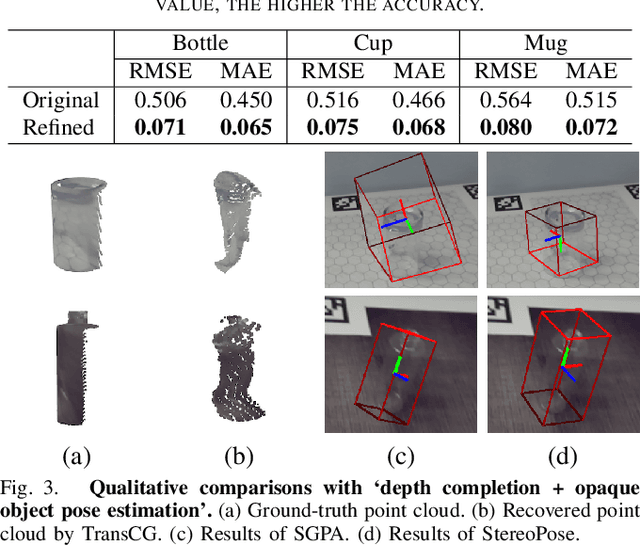
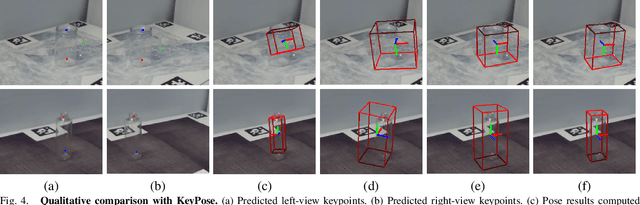
Most existing methods for category-level pose estimation rely on object point clouds. However, when considering transparent objects, depth cameras are usually not able to capture meaningful data, resulting in point clouds with severe artifacts. Without a high-quality point cloud, existing methods are not applicable to challenging transparent objects. To tackle this problem, we present StereoPose, a novel stereo image framework for category-level object pose estimation, ideally suited for transparent objects. For a robust estimation from pure stereo images, we develop a pipeline that decouples category-level pose estimation into object size estimation, initial pose estimation, and pose refinement. StereoPose then estimates object pose based on representation in the normalized object coordinate space~(NOCS). To address the issue of image content aliasing, we further define a back-view NOCS map for the transparent object. The back-view NOCS aims to reduce the network learning ambiguity caused by content aliasing, and leverage informative cues on the back of the transparent object for more accurate pose estimation. To further improve the performance of the stereo framework, StereoPose is equipped with a parallax attention module for stereo feature fusion and an epipolar loss for improving the stereo-view consistency of network predictions. Extensive experiments on the public TOD dataset demonstrate the superiority of the proposed StereoPose framework for category-level 6D transparent object pose estimation.