 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-shot Robust Federated Learning of Independent Component Analysis
May 26, 2025This paper investigates a general robust one-shot aggregation framework for distributed and federated Independent Component Analysis (ICA) problem. We propose a geometric median-based aggregation algorithm that leverages $k$-means clustering to resolve the permutation ambiguity in local client estimations. Our method first performs k-means to partition client-provided estimators into clusters and then aggregates estimators within each cluster using the geometric median. This approach provably remains effective even in highly heterogeneous scenarios where at most half of the clients can observe only a minimal number of samples. The key theoretical contribution lies in the combined analysis of the geometric median's error bound-aided by sample quantiles-and the maximum misclustering rates of the aforementioned solution of $k$-means. The effectiveness of the proposed approach is further supported by simulation studies conducted under various heterogeneous settings.
Learning large softmax mixtures with warm start EM
Sep 16, 2024


Mixed multinomial logits are discrete mixtures introduced several decades ago to model the probability of choosing an attribute from $p$ possible candidates, in heterogeneous populations. The model has recently attracted attention in the AI literature, under the name softmax mixtures, where it is routinely used in the final layer of a neural network to map a large number $p$ of vectors in $\mathbb{R}^L$ to a probability vector. Despite its wide applicability and empirical success, statistically optimal estimators of the mixture parameters, obtained via algorithms whose running time scales polynomially in $L$, are not known. This paper provides a solution to this problem for contemporary applications, such as large language models, in which the mixture has a large number $p$ of support points, and the size $N$ of the sample observed from the mixture is also large. Our proposed estimator combines two classical estimators, obtained respectively via a method of moments (MoM) and the expectation-minimization (EM) algorithm. Although both estimator types have been studied, from a theoretical perspective, for Gaussian mixtures, no similar results exist for softmax mixtures for either procedure. We develop a new MoM parameter estimator based on latent moment estimation that is tailored to our model, and provide the first theoretical analysis for a MoM-based procedure in softmax mixtures. Although consistent, MoM for softmax mixtures can exhibit poor numerical performance, as observed other mixture models. Nevertheless, as MoM is provably in a neighborhood of the target, it can be used as warm start for any iterative algorithm. We study in detail the EM algorithm, and provide its first theoretical analysis for softmax mixtures. Our final proposal for parameter estimation is the EM algorithm with a MoM warm start.
Optimal vintage factor analysis with deflation varimax
Oct 16, 2023
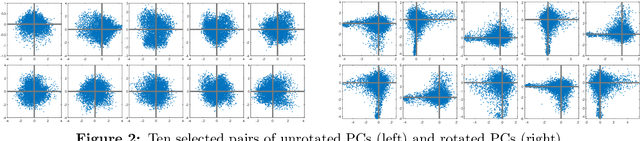
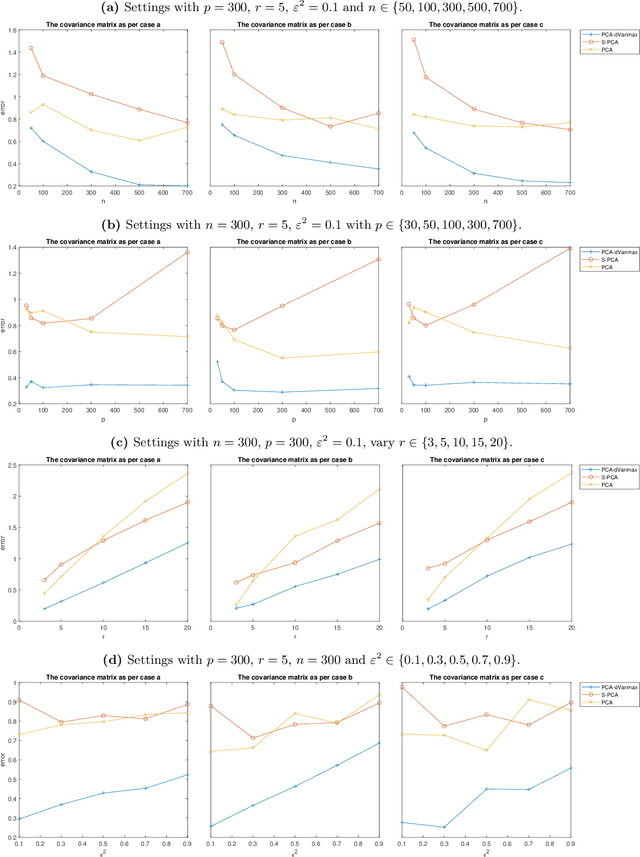
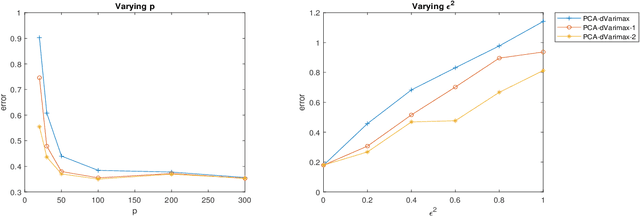
Vintage factor analysis is one important type of factor analysis that aims to first find a low-dimensional representation of the original data, and then to seek a rotation such that the rotated low-dimensional representation is scientifically meaningful. Perhaps the most widely used vintage factor analysis is the Principal Component Analysis (PCA) followed by the varimax rotation. Despite its popularity, little theoretical guarantee can be provided mainly because varimax rotation requires to solve a non-convex optimization over the set of orthogonal matrices. In this paper, we propose a deflation varimax procedure that solves each row of an orthogonal matrix sequentially. In addition to its net computational gain and flexibility, we are able to fully establish theoretical guarantees for the proposed procedure in a broad context. Adopting this new varimax approach as the second step after PCA, we further analyze this two step procedure under a general class of factor models. Our results show that it estimates the factor loading matrix in the optimal rate when the signal-to-noise-ratio (SNR) is moderate or large. In the low SNR regime, we offer possible improvement over using PCA and the deflation procedure when the additive noise under the factor model is structured. The modified procedure is shown to be optimal in all SNR regimes. Our theory is valid for finite sample and allows the number of the latent factors to grow with the sample size as well as the ambient dimension to grow with, or even exceed, the sample size. Extensive simulation and real data analysis further corroborate our theoretical findings.
Interpolating Discriminant Functions in High-Dimensional Gaussian Latent Mixtures
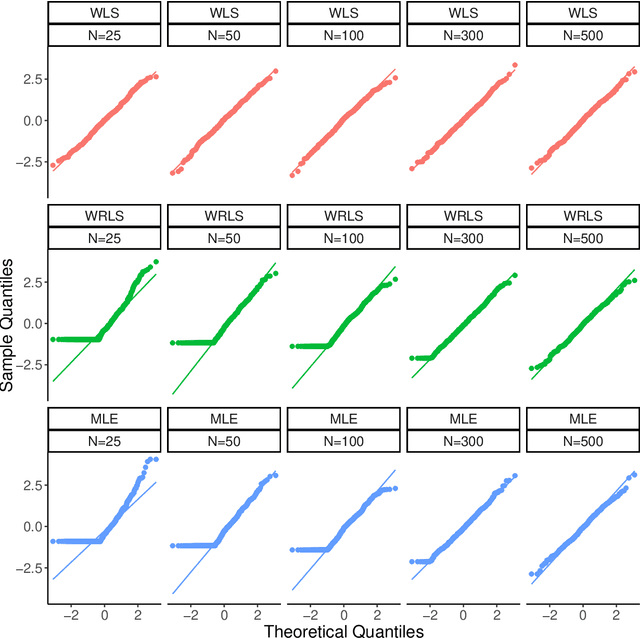
Oct 25, 2022This paper considers binary classification of high-dimensional features under a postulated model with a low-dimensional latent Gaussian mixture structure and non-vanishing noise. A generalized least squares estimator is used to estimate the direction of the optimal separating hyperplane. The estimated hyperplane is shown to interpolate on the training data. While the direction vector can be consistently estimated as could be expected from recent results in linear regression, a naive plug-in estimate fails to consistently estimate the intercept. A simple correction, that requires an independent hold-out sample, renders the procedure minimax optimal in many scenarios. The interpolation property of the latter procedure can be retained, but surprisingly depends on the way the labels are encoded.
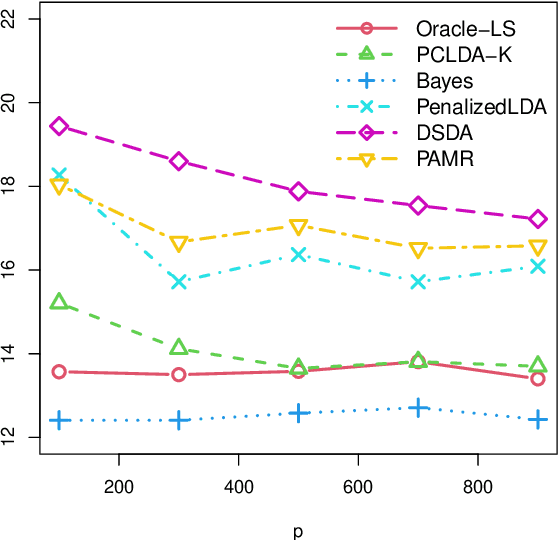
Optimal Discriminant Analysis in High-Dimensional Latent Factor Models
Oct 23, 2022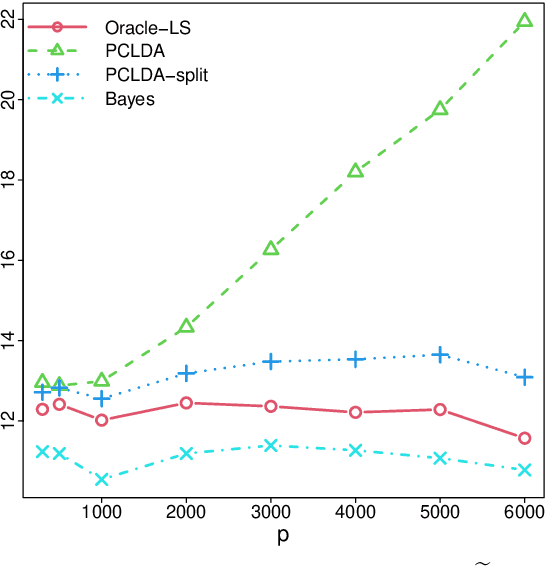

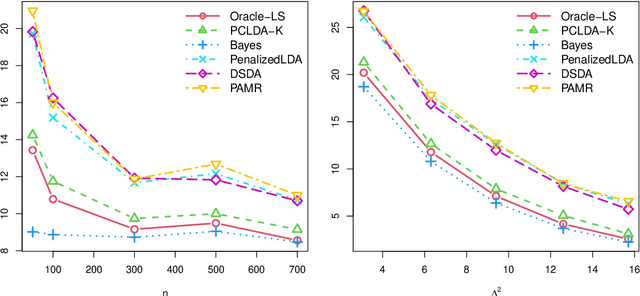
In high-dimensional classification problems, a commonly used approach is to first project the high-dimensional features into a lower dimensional space, and base the classification on the resulting lower dimensional projections. In this paper, we formulate a latent-variable model with a hidden low-dimensional structure to justify this two-step procedure and to guide which projection to choose. We propose a computationally efficient classifier that takes certain principal components (PCs) of the observed features as projections, with the number of retained PCs selected in a data-driven way. A general theory is established for analyzing such two-step classifiers based on any projections. We derive explicit rates of convergence of the excess risk of the proposed PC-based classifier. The obtained rates are further shown to be optimal up to logarithmic factors in the minimax sense. Our theory allows the lower-dimension to grow with the sample size and is also valid even when the feature dimension (greatly) exceeds the sample size. Extensive simulations corroborate our theoretical findings. The proposed method also performs favorably relative to other existing discriminant methods on three real data examples.
The Sketched Wasserstein Distance for mixture distributions
Jun 26, 2022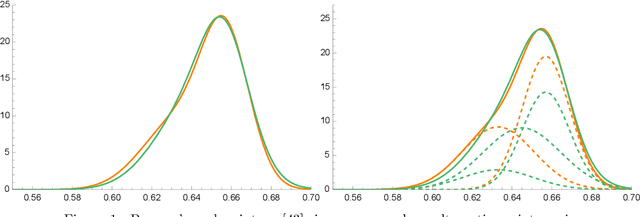

The Sketched Wasserstein Distance ($W^S$) is a new probability distance specifically tailored to finite mixture distributions. Given any metric $d$ defined on a set $\mathcal{A}$ of probability distributions, $W^S$ is defined to be the most discriminative convex extension of this metric to the space $\mathcal{S} = \textrm{conv}(\mathcal{A})$ of mixtures of elements of $\mathcal{A}$. Our representation theorem shows that the space $(\mathcal{S}, W^S)$ constructed in this way is isomorphic to a Wasserstein space over $\mathcal{X} = (\mathcal{A}, d)$. This result establishes a universality property for the Wasserstein distances, revealing them to be uniquely characterized by their discriminative power for finite mixtures. We exploit this representation theorem to propose an estimation methodology based on Kantorovich--Rubenstein duality, and prove a general theorem that shows that its estimation error can be bounded by the sum of the errors of estimating the mixture weights and the mixture components, for any estimators of these quantities. We derive sharp statistical properties for the estimated $W^S$ in the case of $p$-dimensional discrete $K$-mixtures, which we show can be estimated at a rate proportional to $\sqrt{K/N}$, up to logarithmic factors. We complement these bounds with a minimax lower bound on the risk of estimating the Wasserstein distance between distributions on a $K$-point metric space, which matches our upper bound up to logarithmic factors. This result is the first nearly tight minimax lower bound for estimating the Wasserstein distance between discrete distributions. Furthermore, we construct $\sqrt{N}$ asymptotically normal estimators of the mixture weights, and derive a $\sqrt{N}$ distributional limit of our estimator of $W^S$ as a consequence. Simulation studies and a data analysis provide strong support on the applicability of the new Sketched Wasserstein Distance.
Likelihood estimation of sparse topic distributions in topic models and its applications to Wasserstein document distance calculations
Jul 12, 2021
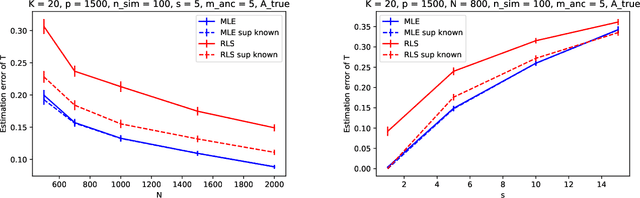
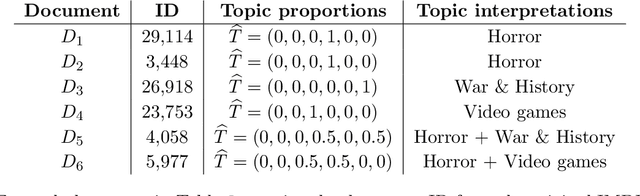
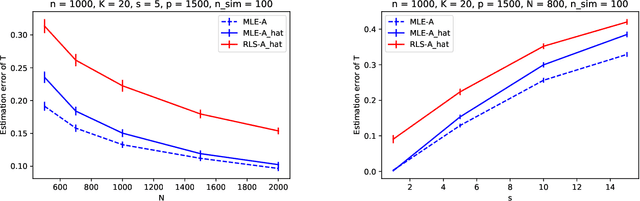
This paper studies the estimation of high-dimensional, discrete, possibly sparse, mixture models in topic models. The data consists of observed multinomial counts of $p$ words across $n$ independent documents. In topic models, the $p\times n$ expected word frequency matrix is assumed to be factorized as a $p\times K$ word-topic matrix $A$ and a $K\times n$ topic-document matrix $T$. Since columns of both matrices represent conditional probabilities belonging to probability simplices, columns of $A$ are viewed as $p$-dimensional mixture components that are common to all documents while columns of $T$ are viewed as the $K$-dimensional mixture weights that are document specific and are allowed to be sparse. The main interest is to provide sharp, finite sample, $\ell_1$-norm convergence rates for estimators of the mixture weights $T$ when $A$ is either known or unknown. For known $A$, we suggest MLE estimation of $T$. Our non-standard analysis of the MLE not only establishes its $\ell_1$ convergence rate, but reveals a remarkable property: the MLE, with no extra regularization, can be exactly sparse and contain the true zero pattern of $T$. We further show that the MLE is both minimax optimal and adaptive to the unknown sparsity in a large class of sparse topic distributions. When $A$ is unknown, we estimate $T$ by optimizing the likelihood function corresponding to a plug in, generic, estimator $\hat{A}$ of $A$. For any estimator $\hat{A}$ that satisfies carefully detailed conditions for proximity to $A$, the resulting estimator of $T$ is shown to retain the properties established for the MLE. The ambient dimensions $K$ and $p$ are allowed to grow with the sample sizes. Our application is to the estimation of 1-Wasserstein distances between document generating distributions. We propose, estimate and analyze new 1-Wasserstein distances between two probabilistic document representations.
Unique sparse decomposition of low rank matrices
Jun 14, 2021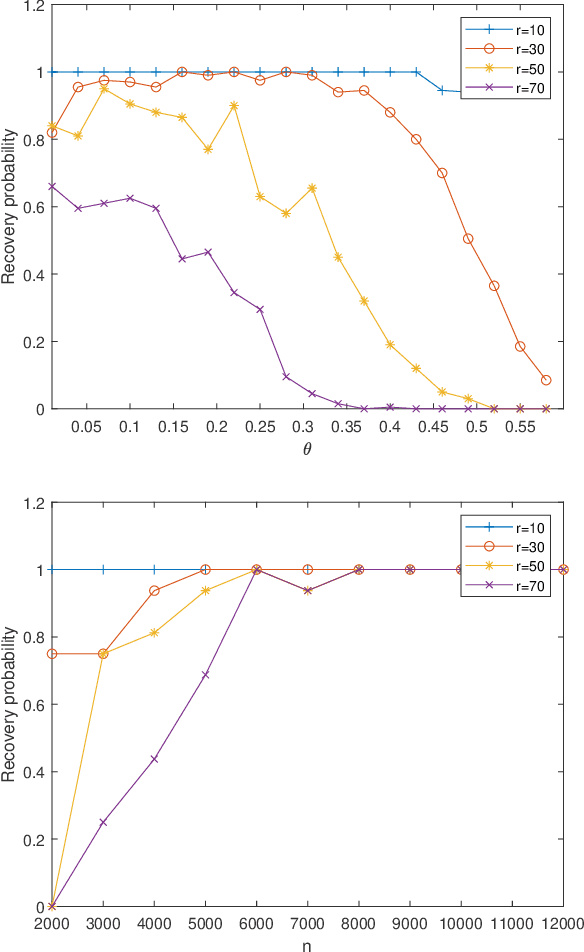
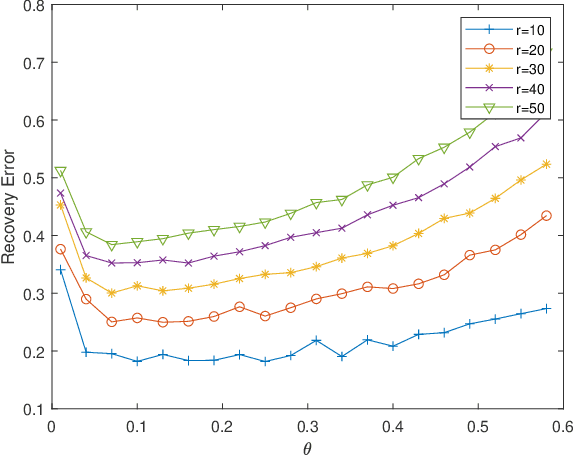
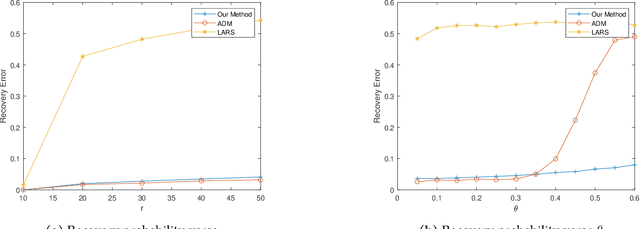
The problem of finding the unique low dimensional decomposition of a given matrix has been a fundamental and recurrent problem in many areas. In this paper, we study the problem of seeking a unique decomposition of a low rank matrix $Y\in \mathbb{R}^{p\times n}$ that admits a sparse representation. Specifically, we consider $Y = A X\in \mathbb{R}^{p\times n}$ where the matrix $A\in \mathbb{R}^{p\times r}$ has full column rank, with $r < \min\{n,p\}$, and the matrix $X\in \mathbb{R}^{r\times n}$ is element-wise sparse. We prove that this sparse decomposition of $Y$ can be uniquely identified, up to some intrinsic signed permutation. Our approach relies on solving a nonconvex optimization problem constrained over the unit sphere. Our geometric analysis for the nonconvex optimization landscape shows that any {\em strict} local solution is close to the ground truth solution, and can be recovered by a simple data-driven initialization followed with any second order descent algorithm. At last, we corroborate these theoretical results with numerical experiments.
Prediction in latent factor regression: Adaptive PCR and beyond
Jul 20, 2020
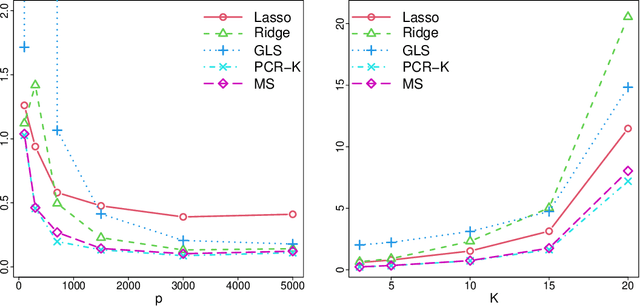
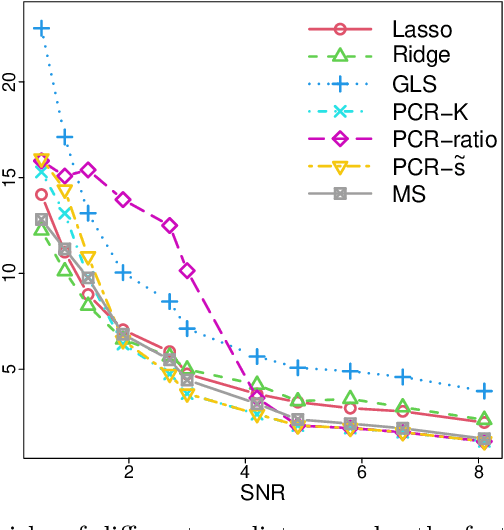
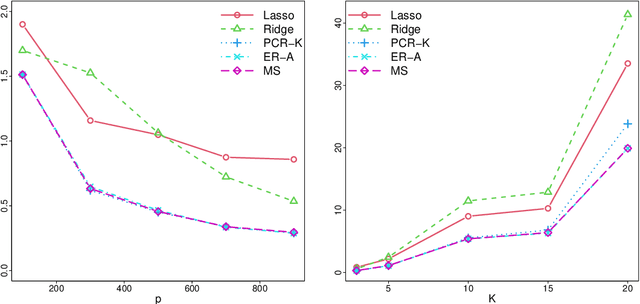
This work is devoted to the finite sample prediction risk analysis of a class of linear predictors of a response $Y\in \mathbb{R}$ from a high-dimensional random vector $X\in \mathbb{R}^p$ when $(X,Y)$ follows a latent factor regression model generated by a unobservable latent vector $Z$ of dimension less than $p$. Our primary contribution is in establishing finite sample risk bounds for prediction with the ubiquitous Principal Component Regression (PCR) method, under the factor regression model, with the number of principal components adaptively selected from the data---a form of theoretical guarantee that is surprisingly lacking from the PCR literature. To accomplish this, we prove a master theorem that establishes a risk bound for a large class of predictors, including the PCR predictor as a special case. This approach has the benefit of providing a unified framework for the analysis of a wide range of linear prediction methods, under the factor regression setting. In particular, we use our main theorem to recover known risk bounds for the minimum-norm interpolating predictor, which has received renewed attention in the past two years, and a prediction method tailored to a subclass of factor regression models with identifiable parameters. This model-tailored method can be interpreted as prediction via clusters with latent centers. To address the problem of selecting among a set of candidate predictors, we analyze a simple model selection procedure based on data-splitting, providing an oracle inequality under the factor model to prove that the performance of the selected predictor is close to the optimal candidate. We conclude with a detailed simulation study to support and complement our theoretical results.
Optimal estimation of sparse topic models
Jan 22, 2020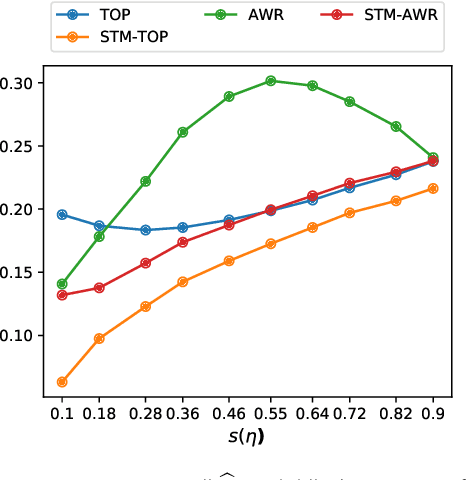
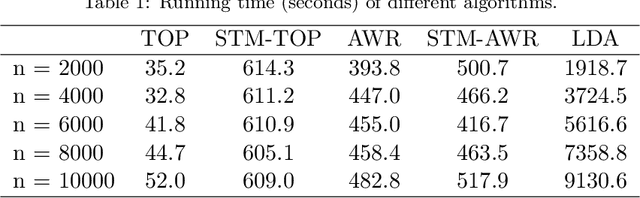
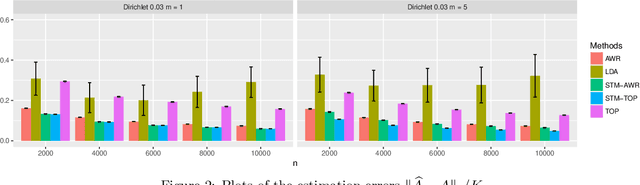
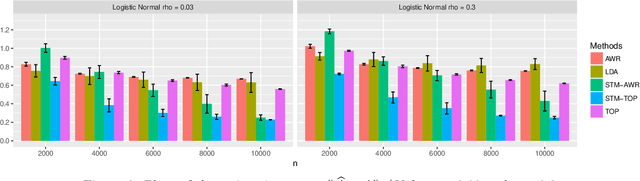
Topic models have become popular tools for dimension reduction and exploratory analysis of text data which consists in observed frequencies of a vocabulary of $p$ words in $n$ documents, stored in a $p\times n$ matrix. The main premise is that the mean of this data matrix can be factorized into a product of two non-negative matrices: a $p\times K$ word-topic matrix $A$ and a $K\times n$ topic-document matrix $W$. This paper studies the estimation of $A$ that is possibly element-wise sparse, and the number of topics $K$ is unknown. In this under-explored context, we derive a new minimax lower bound for the estimation of such $A$ and propose a new computationally efficient algorithm for its recovery. We derive a finite sample upper bound for our estimator, and show that it matches the minimax lower bound in many scenarios. Our estimate adapts to the unknown sparsity of $A$ and our analysis is valid for any finite $n$, $p$, $K$ and document lengths. Empirical results on both synthetic data and semi-synthetic data show that our proposed estimator is a strong competitor of the existing state-of-the-art algorithms for both non-sparse $A$ and sparse $A$, and has superior performance is many scenarios of interest.