 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal estimation of sparse topic models
Paper and Code
Jan 22, 2020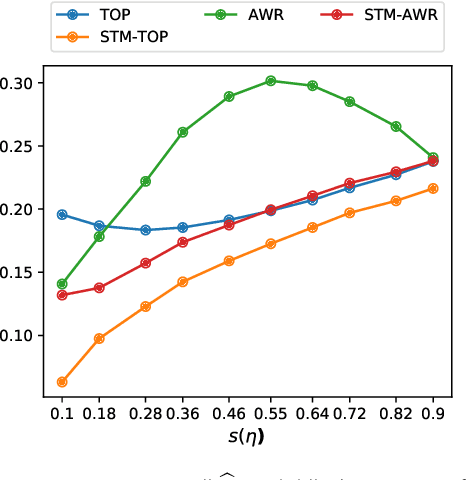
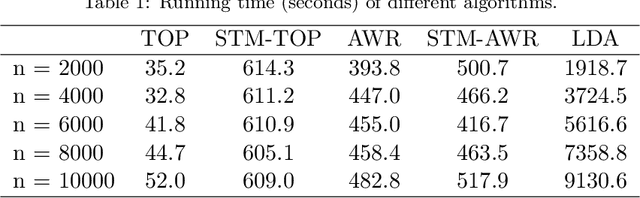
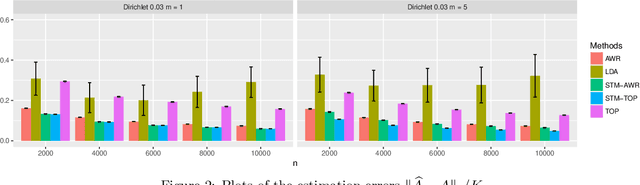
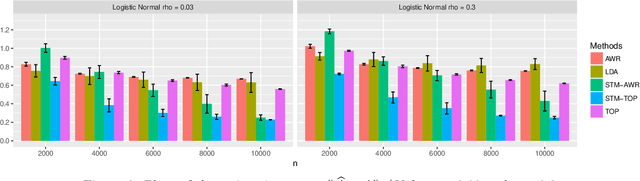
Topic models have become popular tools for dimension reduction and exploratory analysis of text data which consists in observed frequencies of a vocabulary of $p$ words in $n$ documents, stored in a $p\times n$ matrix. The main premise is that the mean of this data matrix can be factorized into a product of two non-negative matrices: a $p\times K$ word-topic matrix $A$ and a $K\times n$ topic-document matrix $W$. This paper studies the estimation of $A$ that is possibly element-wise sparse, and the number of topics $K$ is unknown. In this under-explored context, we derive a new minimax lower bound for the estimation of such $A$ and propose a new computationally efficient algorithm for its recovery. We derive a finite sample upper bound for our estimator, and show that it matches the minimax lower bound in many scenarios. Our estimate adapts to the unknown sparsity of $A$ and our analysis is valid for any finite $n$, $p$, $K$ and document lengths. Empirical results on both synthetic data and semi-synthetic data show that our proposed estimator is a strong competitor of the existing state-of-the-art algorithms for both non-sparse $A$ and sparse $A$, and has superior performance is many scenarios of interest.