 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgical Visual Understanding (SurgVU) Dataset
Jan 16, 2025



Owing to recent advances in machine learning and the ability to harvest large amounts of data during robotic-assisted surgeries, surgical data science is ripe for foundational work. We present a large dataset of surgical videos and their accompanying labels for this purpose. We describe how the data was collected and some of its unique attributes. Multiple example problems are outlined. Although the dataset was curated for a particular set of scientific challenges (in an accompanying paper), it is general enough to be used for a broad range machine learning questions. Our hope is that this dataset exposes the larger machine learning community to the challenging problems within surgical data science, and becomes a touchstone for future research. The videos are available at https://storage.googleapis.com/isi-surgvu/surgvu24_videos_only.zip, the labels at https://storage.googleapis.com/isi-surgvu/surgvu24_labels_updated_v2.zip, and a validation set for tool detection problem at https://storage.googleapis.com/isi-surgvu/cat1_test_set_public.zip.
The Quiet Eye Phenomenon in Minimally Invasive Surgery
Sep 06, 2023In this paper, we report our discovery of a gaze behavior called Quiet Eye (QE) in minimally invasive surgery. The QE behavior has been extensively studied in sports training and has been associated with higher level of expertise in multiple sports. We investigated the QE behavior in two independently collected data sets of surgeons performing tasks in a sinus surgery setting and a robotic surgery setting, respectively. Our results show that the QE behavior is more likely to occur in successful task executions and in performances of surgeons of high level of expertise. These results open the door to use the QE behavior in both training and skill assessment in minimally invasive surgery.
Surgical tool classification and localization: results and methods from the MICCAI 2022 SurgToolLoc challenge
May 11, 2023



The ability to automatically detect and track surgical instruments in endoscopic videos can enable transformational interventions. Assessing surgical performance and efficiency, identifying skilled tool use and choreography, and planning operational and logistical aspects of OR resources are just a few of the applications that could benefit. Unfortunately, obtaining the annotations needed to train machine learning models to identify and localize surgical tools is a difficult task. Annotating bounding boxes frame-by-frame is tedious and time-consuming, yet large amounts of data with a wide variety of surgical tools and surgeries must be captured for robust training. Moreover, ongoing annotator training is needed to stay up to date with surgical instrument innovation. In robotic-assisted surgery, however, potentially informative data like timestamps of instrument installation and removal can be programmatically harvested. The ability to rely on tool installation data alone would significantly reduce the workload to train robust tool-tracking models. With this motivation in mind we invited the surgical data science community to participate in the challenge, SurgToolLoc 2022. The goal was to leverage tool presence data as weak labels for machine learning models trained to detect tools and localize them in video frames with bounding boxes. We present the results of this challenge along with many of the team's efforts. We conclude by discussing these results in the broader context of machine learning and surgical data science. The training data used for this challenge consisting of 24,695 video clips with tool presence labels is also being released publicly and can be accessed at https://console.cloud.google.com/storage/browser/isi-surgtoolloc-2022.
Automatic Detection of Out-of-body Frames in Surgical Videos for Privacy Protection Using Self-supervised Learning and Minimal Labels
Mar 31, 2023



Endoscopic video recordings are widely used in minimally invasive robot-assisted surgery, but when the endoscope is outside the patient's body, it can capture irrelevant segments that may contain sensitive information. To address this, we propose a framework that accurately detects out-of-body frames in surgical videos by leveraging self-supervision with minimal data labels. We use a massive amount of unlabeled endoscopic images to learn meaningful representations in a self-supervised manner. Our approach, which involves pre-training on an auxiliary task and fine-tuning with limited supervision, outperforms previous methods for detecting out-of-body frames in surgical videos captured from da Vinci X and Xi surgical systems. The average F1 scores range from 96.00 to 98.02. Remarkably, using only 5% of the training labels, our approach still maintains an average F1 score performance above 97, outperforming fully-supervised methods with 95% fewer labels. These results demonstrate the potential of our framework to facilitate the safe handling of surgical video recordings and enhance data privacy protection in minimally invasive surgery.
Objective Surgical Skills Assessment and Tool Localization: Results from the MICCAI 2021 SimSurgSkill Challenge
Dec 08, 2022Timely and effective feedback within surgical training plays a critical role in developing the skills required to perform safe and efficient surgery. Feedback from expert surgeons, while especially valuable in this regard, is challenging to acquire due to their typically busy schedules, and may be subject to biases. Formal assessment procedures like OSATS and GEARS attempt to provide objective measures of skill, but remain time-consuming. With advances in machine learning there is an opportunity for fast and objective automated feedback on technical skills. The SimSurgSkill 2021 challenge (hosted as a sub-challenge of EndoVis at MICCAI 2021) aimed to promote and foster work in this endeavor. Using virtual reality (VR) surgical tasks, competitors were tasked with localizing instruments and predicting surgical skill. Here we summarize the winning approaches and how they performed. Using this publicly available dataset and results as a springboard, future work may enable more efficient training of surgeons with advances in surgical data science. The dataset can be accessed from https://console.cloud.google.com/storage/browser/isi-simsurgskill-2021.
Surgical Visual Domain Adaptation: Results from the MICCAI 2020 SurgVisDom Challenge
Feb 26, 2021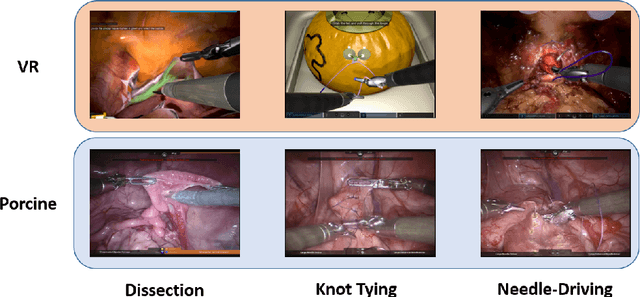
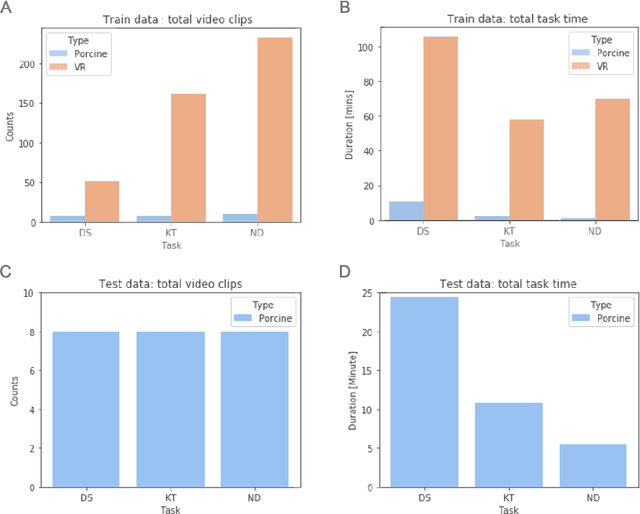
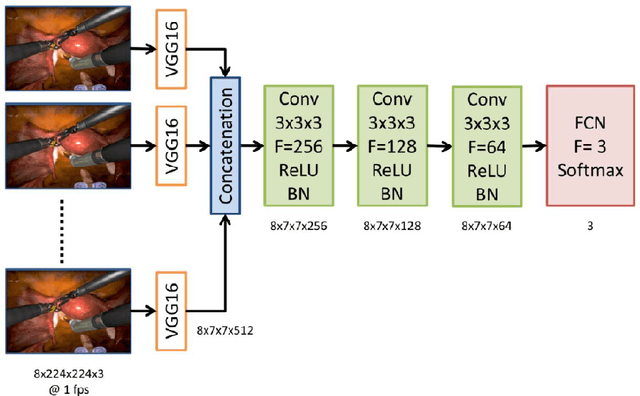
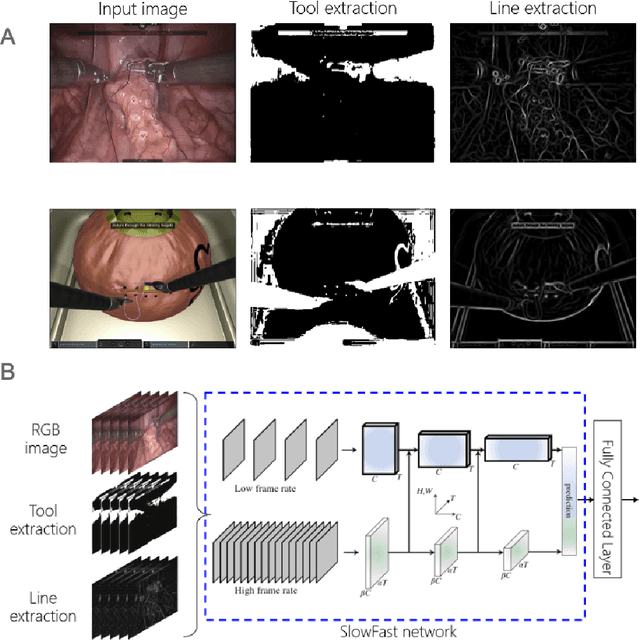
Surgical data science is revolutionizing minimally invasive surgery by enabling context-aware applications. However, many challenges exist around surgical data (and health data, more generally) needed to develop context-aware models. This work - presented as part of the Endoscopic Vision (EndoVis) challenge at the Medical Image Computing and Computer Assisted Intervention (MICCAI) 2020 conference - seeks to explore the potential for visual domain adaptation in surgery to overcome data privacy concerns. In particular, we propose to use video from virtual reality (VR) simulations of surgical exercises in robotic-assisted surgery to develop algorithms to recognize tasks in a clinical-like setting. We present the performance of the different approaches to solve visual domain adaptation developed by challenge participants. Our analysis shows that the presented models were unable to learn meaningful motion based features form VR data alone, but did significantly better when small amount of clinical-like data was also made available. Based on these results, we discuss promising methods and further work to address the problem of visual domain adaptation in surgical data science. We also release the challenge dataset publicly at https://www.synapse.org/surgvisdom2020.
Novel evaluation of surgical activity recognition models using task-based efficiency metrics
Jul 03, 2019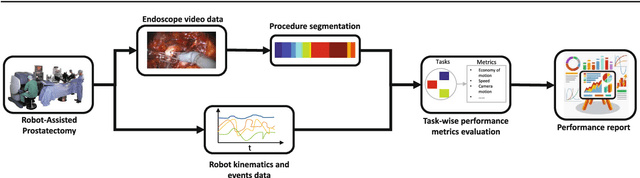

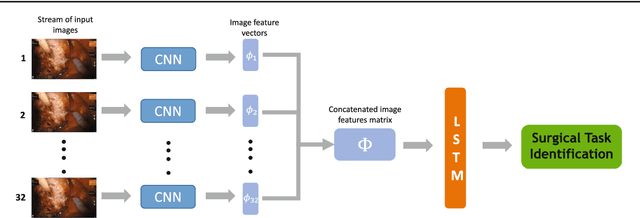
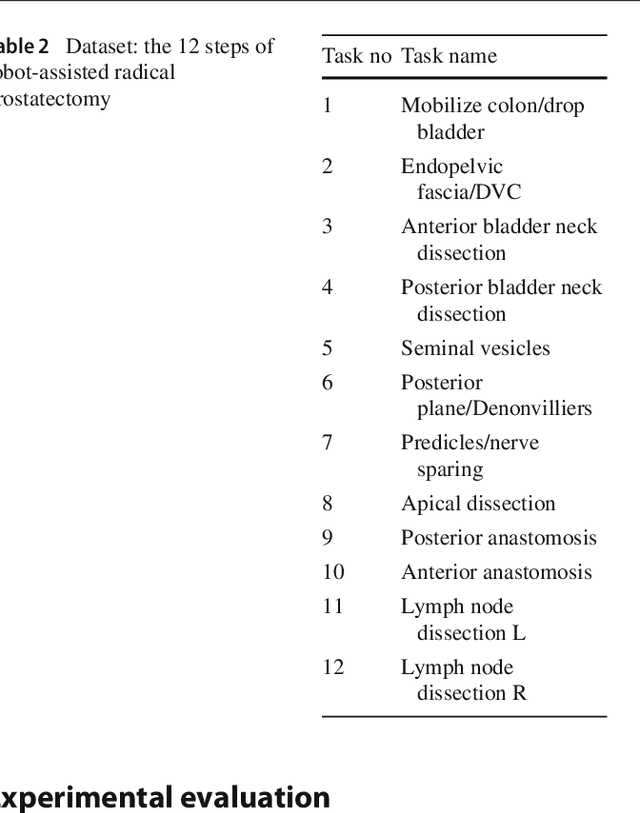
Purpose: Surgical task-based metrics (rather than entire procedure metrics) can be used to improve surgeon training and, ultimately, patient care through focused training interventions. Machine learning models to automatically recognize individual tasks or activities are needed to overcome the otherwise manual effort of video review. Traditionally, these models have been evaluated using frame-level accuracy. Here, we propose evaluating surgical activity recognition models by their effect on task-based efficiency metrics. In this way, we can determine when models have achieved adequate performance for providing surgeon feedback via metrics from individual tasks. Methods: We propose a new CNN-LSTM model, RP-Net-V2, to recognize the 12 steps of robotic-assisted radical prostatectomies (RARP). We evaluated our model both in terms of conventional methods (e.g. Jaccard Index, task boundary accuracy) as well as novel ways, such as the accuracy of efficiency metrics computed from instrument movements and system events. Results: Our proposed model achieves a Jaccard Index of 0.85 thereby outperforming previous models on robotic-assisted radical prostatectomies. Additionally, we show that metrics computed from tasks automatically identified using RP-Net-V2 correlate well with metrics from tasks labeled by clinical experts. Conclusions: We demonstrate that metrics-based evaluation of surgical activity recognition models is a viable approach to determine when models can be used to quantify surgical efficiencies. We believe this approach and our results illustrate the potential for fully automated, post-operative efficiency reports.
Surgical Activity Recognition in Robot-Assisted Radical Prostatectomy using Deep Learning
Jun 01, 2018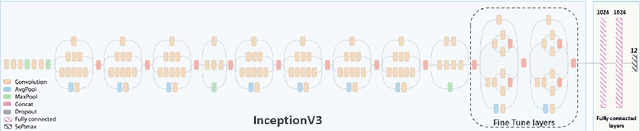
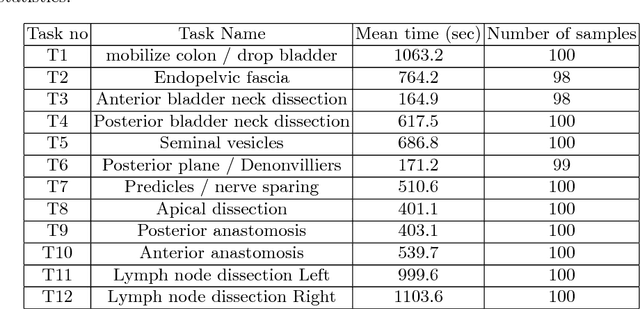

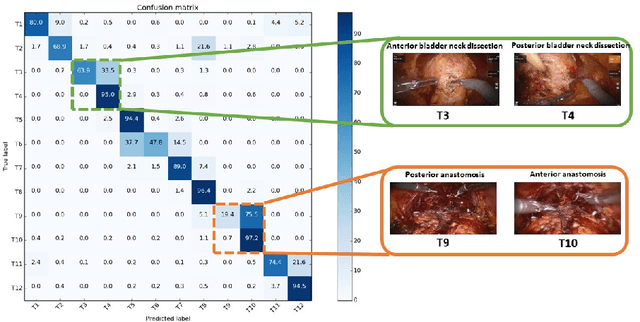
Adverse surgical outcomes are costly to patients and hospitals. Approaches to benchmark surgical care are often limited to gross measures across the entire procedure despite the performance of particular tasks being largely responsible for undesirable outcomes. In order to produce metrics from tasks as opposed to the whole procedure, methods to recognize automatically individual surgical tasks are needed. In this paper, we propose several approaches to recognize surgical activities in robot-assisted minimally invasive surgery using deep learning. We collected a clinical dataset of 100 robot-assisted radical prostatectomies (RARP) with 12 tasks each and propose `RP-Net', a modified version of InceptionV3 model, for image based surgical activity recognition. We achieve an average precision of 80.9% and average recall of 76.7% across all tasks using RP-Net which out-performs all other RNN and CNN based models explored in this paper. Our results suggest that automatic surgical activity recognition during RARP is feasible and can be the foundation for advanced analytics.