 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning methods for automatic evaluation of delayed enhancement-MRI. The results of the EMIDEC challenge
Aug 10, 2021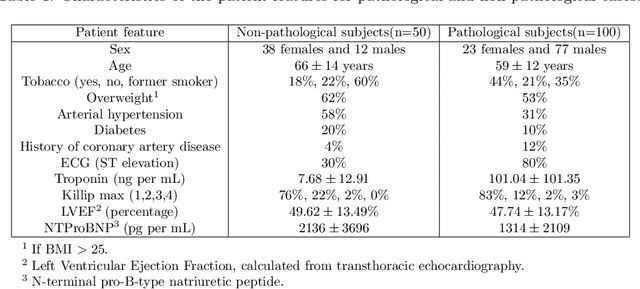

A key factor for assessing the state of the heart after myocardial infarction (MI) is to measure whether the myocardium segment is viable after reperfusion or revascularization therapy. Delayed enhancement-MRI or DE-MRI, which is performed several minutes after injection of the contrast agent, provides high contrast between viable and nonviable myocardium and is therefore a method of choice to evaluate the extent of MI. To automatically assess myocardial status, the results of the EMIDEC challenge that focused on this task are presented in this paper. The challenge's main objectives were twofold. First, to evaluate if deep learning methods can distinguish between normal and pathological cases. Second, to automatically calculate the extent of myocardial infarction. The publicly available database consists of 150 exams divided into 50 cases with normal MRI after injection of a contrast agent and 100 cases with myocardial infarction (and then with a hyperenhanced area on DE-MRI), whatever their inclusion in the cardiac emergency department. Along with MRI, clinical characteristics are also provided. The obtained results issued from several works show that the automatic classification of an exam is a reachable task (the best method providing an accuracy of 0.92), and the automatic segmentation of the myocardium is possible. However, the segmentation of the diseased area needs to be improved, mainly due to the small size of these areas and the lack of contrast with the surrounding structures.
Surgical Visual Domain Adaptation: Results from the MICCAI 2020 SurgVisDom Challenge
Feb 26, 2021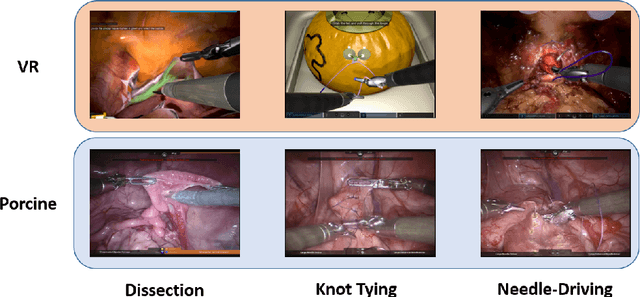
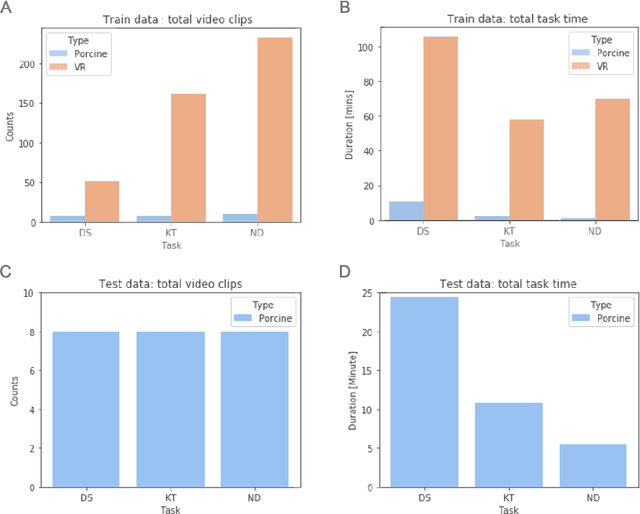
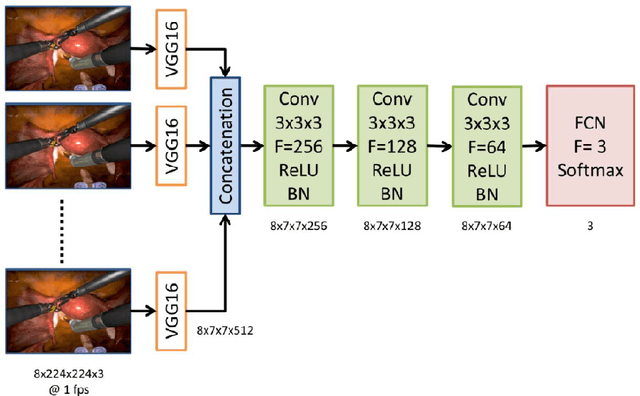
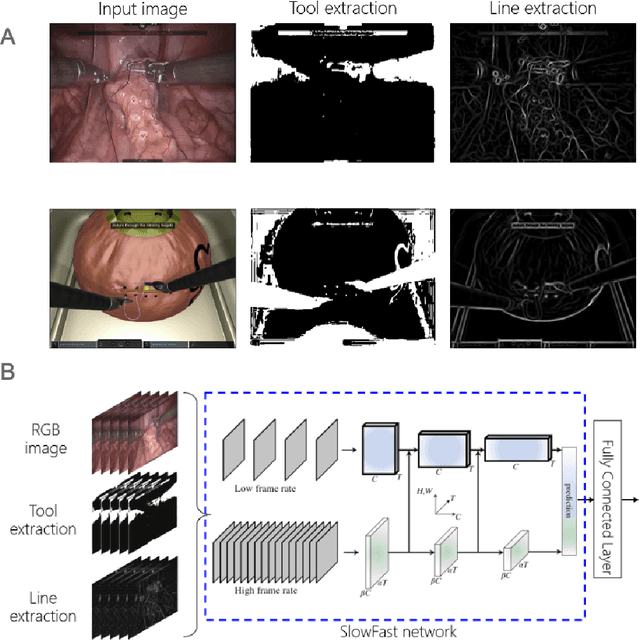
Surgical data science is revolutionizing minimally invasive surgery by enabling context-aware applications. However, many challenges exist around surgical data (and health data, more generally) needed to develop context-aware models. This work - presented as part of the Endoscopic Vision (EndoVis) challenge at the Medical Image Computing and Computer Assisted Intervention (MICCAI) 2020 conference - seeks to explore the potential for visual domain adaptation in surgery to overcome data privacy concerns. In particular, we propose to use video from virtual reality (VR) simulations of surgical exercises in robotic-assisted surgery to develop algorithms to recognize tasks in a clinical-like setting. We present the performance of the different approaches to solve visual domain adaptation developed by challenge participants. Our analysis shows that the presented models were unable to learn meaningful motion based features form VR data alone, but did significantly better when small amount of clinical-like data was also made available. Based on these results, we discuss promising methods and further work to address the problem of visual domain adaptation in surgical data science. We also release the challenge dataset publicly at https://www.synapse.org/surgvisdom2020.
Automatic Myocardial Infarction Evaluation from Delayed-Enhancement Cardiac MRI using Deep Convolutional Networks
Oct 30, 2020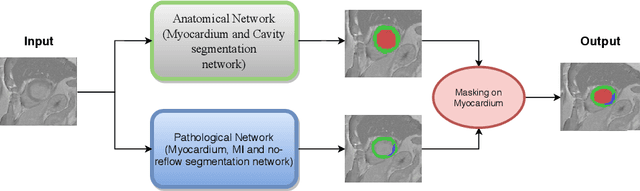

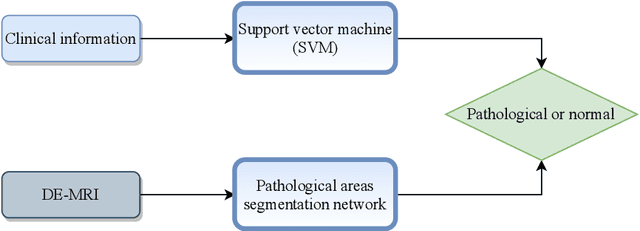
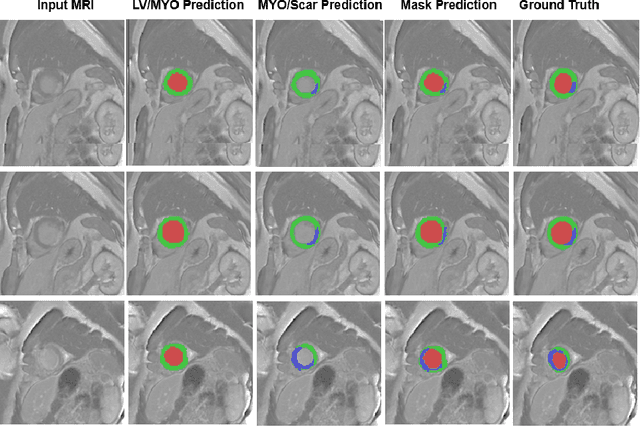
In this paper, we propose a new deep learning framework for an automatic myocardial infarction evaluation from clinical information and delayed enhancement-MRI (DE-MRI). The proposed framework addresses two tasks. The first task is automatic detection of myocardial contours, the infarcted area, the no-reflow area, and the left ventricular cavity from a short-axis DE-MRI series. It employs two segmentation neural networks. The first network is used to segment the anatomical structures such as the myocardium and left ventricular cavity. The second network is used to segment the pathological areas such as myocardial infarction, myocardial no-reflow, and normal myocardial region. The segmented myocardium region from the first network is further used to refine the second network's pathological segmentation results. The second task is to automatically classify a given case into normal or pathological from clinical information with or without DE-MRI. A cascaded support vector machine (SVM) is employed to classify a given case from its associated clinical information. The segmented pathological areas from DE-MRI are also used for the classification task. We evaluated our method on the 2020 EMIDEC MICCAI challenge dataset. It yielded an average Dice index of 0.93 and 0.84, respectively, for the left ventricular cavity and the myocardium. The classification from using only clinical information yielded 80% accuracy over five-fold cross-validation. Using the DE-MRI, our method can classify the cases with 93.3% accuracy. These experimental results reveal that the proposed method can automatically evaluate the myocardial infarction.
Deep generative model-driven multimodal prostate segmentation in radiotherapy
Oct 23, 2019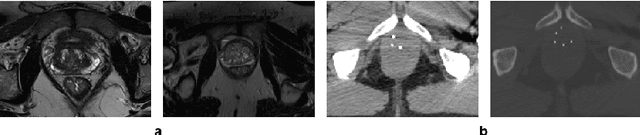
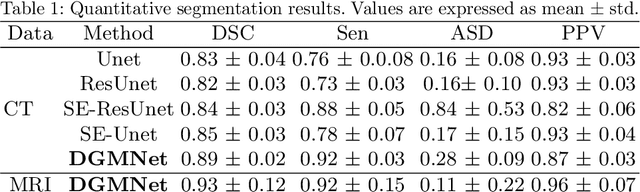
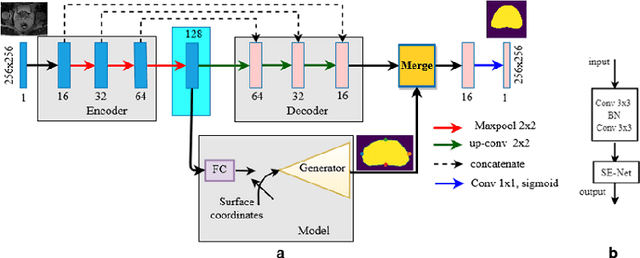
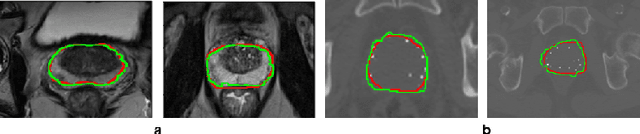
Deep learning has shown unprecedented success in a variety of applications, such as computer vision and medical image analysis. However, there is still potential to improve segmentation in multimodal images by embedding prior knowledge via learning-based shape modeling and registration to learn the modality invariant anatomical structure of organs. For example, in radiotherapy automatic prostate segmentation is essential in prostate cancer diagnosis, therapy, and post-therapy assessment from T2-weighted MR or CT images. In this paper, we present a fully automatic deep generative model-driven multimodal prostate segmentation method using convolutional neural network (DGMNet). The novelty of our method comes with its embedded generative neural network for learning-based shape modeling and its ability to adapt for different imaging modalities via learning-based registration. The proposed method includes a multi-task learning framework that combines a convolutional feature extraction and an embedded regression and classification based shape modeling. This enables the network to predict the deformable shape of an organ. We show that generative neural networkbased shape modeling trained on a reliable contrast imaging modality (such as MRI) can be directly applied to low contrast imaging modality (such as CT) to achieve accurate prostate segmentation. The method was evaluated on MRI and CT datasets acquired from different clinical centers with large variations in contrast and scanning protocols. Experimental results reveal that our method can be used to automatically and accurately segment the prostate gland in different imaging modalities.
3D landmark detection for augmented reality based otologic procedures
Sep 04, 2019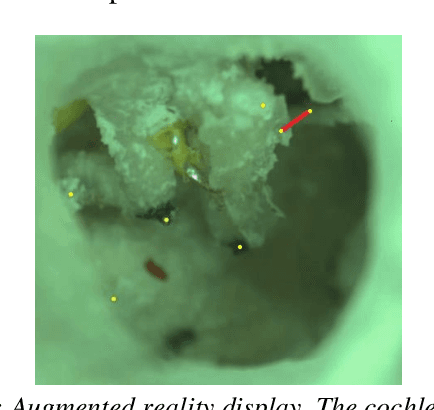
Ear consists of the smallest bones in the human body and does not contain significant amount of distinct landmark points that may be used to register a preoperative CT-scan with the surgical video in an augmented reality framework. Learning based algorithms may be used to help the surgeons to identify landmark points. This paper presents a convolutional neural network approach to landmark detection in preoperative ear CT images and then discusses an augmented reality system that can be used to visualize the cochlear axis on an otologic surgical video.