 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge6G-AUTOR: Autonomic CSI-Free Transceiver via Realtime On-Device Signal Analytics
Jun 07, 2022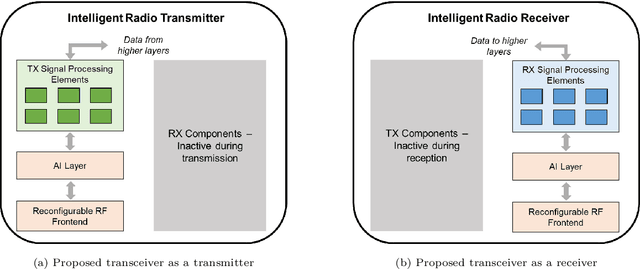
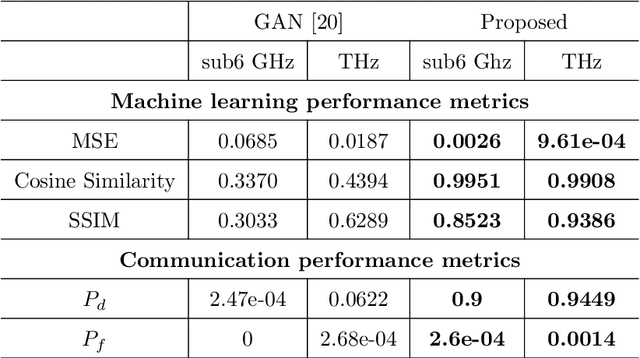

Next-generation wireless systems aim at fulfilling diverse application requirements but fundamentally rely on point-to-point transmission qualities. Aligning with recent AI-enabled wireless implementations, this paper introduces autonomic radios, 6G-AUTOR, that leverage novel algorithm-hardware separation platforms, softwarization of transmission (TX) and reception (RX) operations, and automatic reconfiguration of RF frontends, to support link performance and resilience. As a comprehensive transceiver solution, our design encompasses several ML-driven models, each enhancing a specific aspect of either TX or RX, leading to robust transceiver operation under tight constraints of future wireless systems. A data-driven radio management module was developed via deep Q-networks to support fast-reconfiguration of TX resource blocks (RB) and proactive multi-agent access. Also, a ResNet-inspired fast-beamforming solution was employed to enable robust communication to multiple receivers over the same RB, which has potential applications in realisation of cell-free infrastructures. As a receiver the system was equipped with a capability of ultra-broadband spectrum recognition. Apart from this, a fundamental tool - automatic modulation classification (AMC) which involves a complex correntropy extraction, followed by a convolutional neural network (CNN)-based classification, and a deep learning-based LDPC decoder were added to improve the reception quality and radio performance. Simulations of individual algorithms demonstrate that under appropriate training, each of the corresponding radio functions have either outperformed or have performed on-par with the benchmark solutions.
Zero-Touch Network on Industrial IoT: An End-to-End Machine Learning Approach
Apr 26, 2022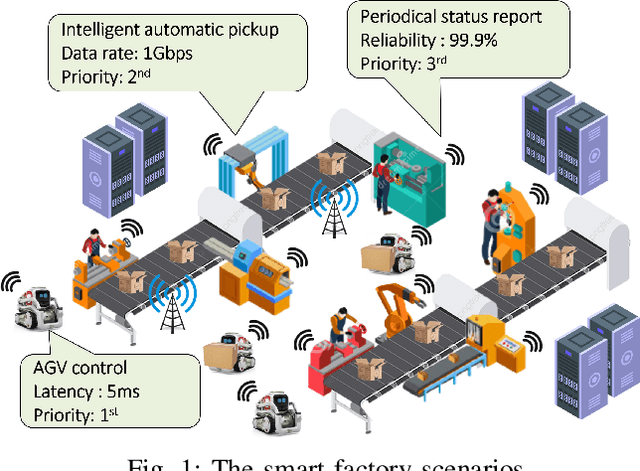
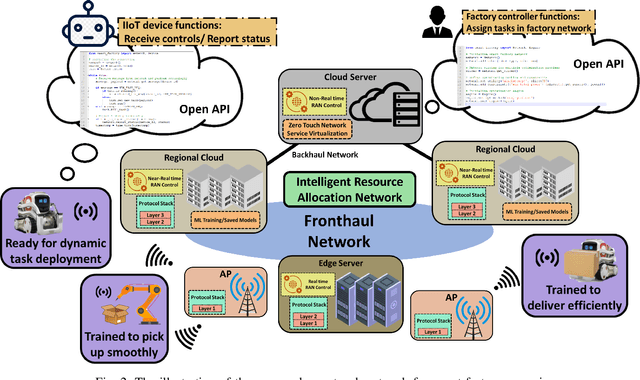
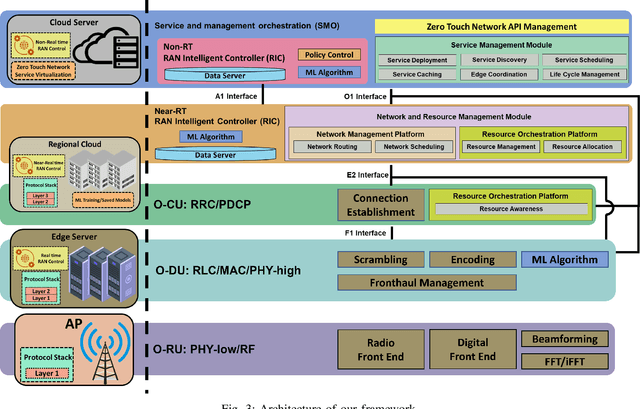
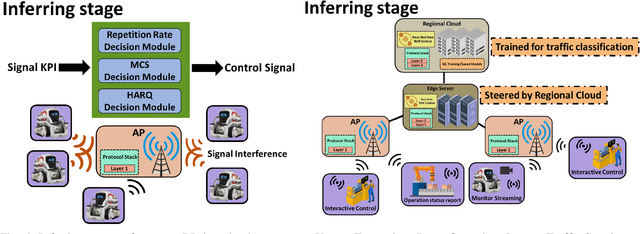
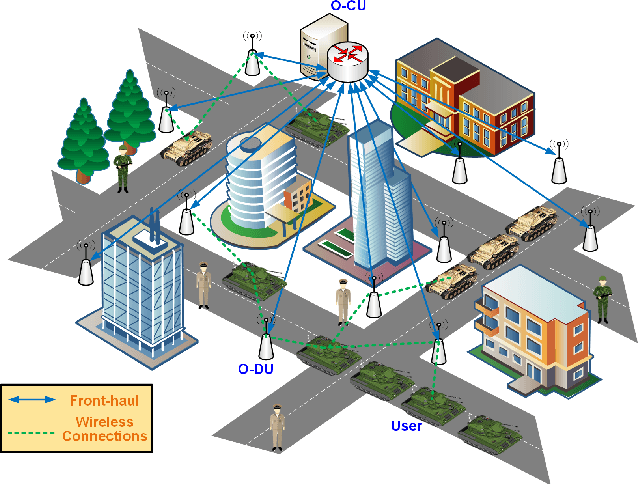
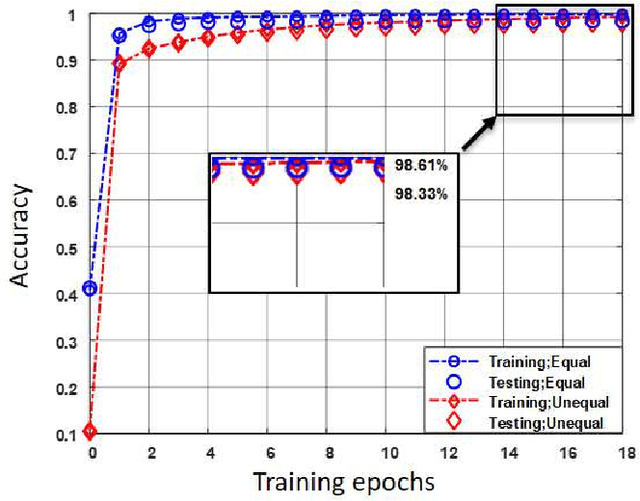
Industry 4.0-enabled smart factory is expected to realize the next revolution for manufacturers. Although artificial intelligence (AI) technologies have improved productivity, current use cases belong to small-scale and single-task operations. To unbound the potential of smart factory, this paper develops zero-touch network systems for intelligent manufacturing and facilitates distributed AI applications in both training and inferring stages in a large-scale manner. The open radio access network (O-RAN) architecture is first introduced for the zero-touch platform to enable globally controlling communications and computation infrastructure capability in the field. The designed serverless framework allows intelligent and efficient learning assignments and resource allocations. Hence, requested learning tasks can be assigned to appropriate robots, and the underlying infrastructure can be used to support the learning tasks without expert knowledge. Moreover, due to the proposed network system's flexibility, powerful AI-enabled networking algorithms can be utilized to ensure service-level agreements and superior performances for factory workloads. Finally, three open research directions of backward compatibility, end-to-end enhancements, and cybersecurity are discussed for zero-touch smart factory.
Privacy-Preserving Serverless Edge Learning with Decentralized Small Data
Dec 01, 2021


In the last decade, data-driven algorithms outperformed traditional optimization-based algorithms in many research areas, such as computer vision, natural language processing, etc. However, extensive data usages bring a new challenge or even threat to deep learning algorithms, i.e., privacy-preserving. Distributed training strategies have recently become a promising approach to ensure data privacy when training deep models. This paper extends conventional serverless platforms with serverless edge learning architectures and provides an efficient distributed training framework from the networking perspective. This framework dynamically orchestrates available resources among heterogeneous physical units to efficiently fulfill deep learning objectives. The design jointly considers learning task requests and underlying infrastructure heterogeneity, including last-mile transmissions, computation abilities of mobile devices, edge and cloud computing centers, and devices battery status. Furthermore, to significantly reduce distributed training overheads, small-scale data training is proposed by integrating with a general, simple data classifier. This low-load enhancement can seamlessly work with various distributed deep models to improve communications and computation efficiencies during the training phase. Finally, open challenges and future research directions encourage the research community to develop efficient distributed deep learning techniques.
The CoSTAR Block Stacking Dataset: Learning with Workspace Constraints
Mar 12, 2019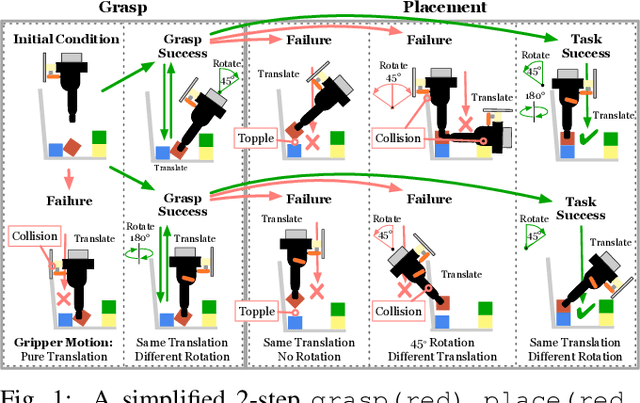

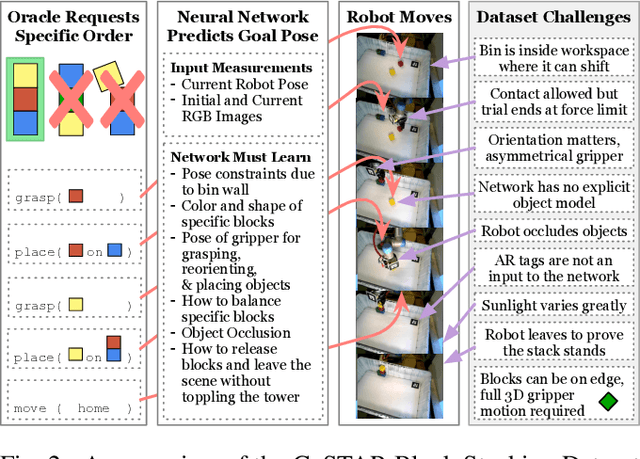

A robot can now grasp an object more effectively than ever before, but once it has the object what happens next? We show that a mild relaxation of the task and workspace constraints implicit in existing object grasping datasets can cause neural network based grasping algorithms to fail on even a simple block stacking task when executed under more realistic circumstances. To address this, we introduce the JHU CoSTAR Block Stacking Dataset (BSD), where a robot interacts with 5.1 cm colored blocks to complete an order-fulfillment style block stacking task. It contains dynamic scenes and real time-series data in a less constrained environment than comparable datasets. There are nearly 12,000 stacking attempts and over 2 million frames of real data. We discuss the ways in which this dataset provides a valuable resource for a broad range of other topics of investigation. We find that hand-designed neural networks that work on prior datasets do not generalize to this task. Thus, to establish a baseline for this dataset, we demonstrate an automated search of neural network based models using a novel multiple-input HyperTree MetaModel, and find a final model which makes reasonable 3D pose predictions for grasping and stacking on our dataset. The CoSTAR BSD, code, and instructions are available at https://sites.google.com/site/costardataset.