 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEV-Patch-PF: Particle Filtering with BEV-Aerial Feature Matching for Off-Road Geo-Localization
Dec 17, 2025We propose BEV-Patch-PF, a GPS-free sequential geo-localization system that integrates a particle filter with learned bird's-eye-view (BEV) and aerial feature maps. From onboard RGB and depth images, we construct a BEV feature map. For each 3-DoF particle pose hypothesis, we crop the corresponding patch from an aerial feature map computed from a local aerial image queried around the approximate location. BEV-Patch-PF computes a per-particle log-likelihood by matching the BEV feature to the aerial patch feature. On two real-world off-road datasets, our method achieves 7.5x lower absolute trajectory error (ATE) on seen routes and 7.0x lower ATE on unseen routes than a retrieval-based baseline, while maintaining accuracy under dense canopy and shadow. The system runs in real time at 10 Hz on an NVIDIA Tesla T4, enabling practical robot deployment.
A Hybrid Technique for Plant Disease Identification and Localisation in Real-time
Dec 27, 2024



Over the past decade, several image-processing methods and algorithms have been proposed for identifying plant diseases based on visual data. DNN (Deep Neural Networks) have recently become popular for this task. Both traditional image processing and DNN-based methods encounter significant performance issues in real-time detection owing to computational limitations and a broad spectrum of plant disease features. This article proposes a novel technique for identifying and localising plant disease based on the Quad-Tree decomposition of an image and feature learning simultaneously. The proposed algorithm significantly improves accuracy and faster convergence in high-resolution images with relatively low computational load. Hence it is ideal for deploying the algorithm in a standalone processor in a remotely operated image acquisition and disease detection system, ideally mounted on drones and robots working on large agricultural fields. The technique proposed in this article is hybrid as it exploits the advantages of traditional image processing methods and DNN-based models at different scales, resulting in faster inference. The F1 score is approximately 0.80 for four disease classes corresponding to potato and tomato crops.
DATT: Deep Adaptive Trajectory Tracking for Quadrotor Control
Oct 17, 2023



Precise arbitrary trajectory tracking for quadrotors is challenging due to unknown nonlinear dynamics, trajectory infeasibility, and actuation limits. To tackle these challenges, we present Deep Adaptive Trajectory Tracking (DATT), a learning-based approach that can precisely track arbitrary, potentially infeasible trajectories in the presence of large disturbances in the real world. DATT builds on a novel feedforward-feedback-adaptive control structure trained in simulation using reinforcement learning. When deployed on real hardware, DATT is augmented with a disturbance estimator using L1 adaptive control in closed-loop, without any fine-tuning. DATT significantly outperforms competitive adaptive nonlinear and model predictive controllers for both feasible smooth and infeasible trajectories in unsteady wind fields, including challenging scenarios where baselines completely fail. Moreover, DATT can efficiently run online with an inference time less than 3.2 ms, less than 1/4 of the adaptive nonlinear model predictive control baseline
Deep Model Predictive Optimization
Oct 06, 2023



A major challenge in robotics is to design robust policies which enable complex and agile behaviors in the real world. On one end of the spectrum, we have model-free reinforcement learning (MFRL), which is incredibly flexible and general but often results in brittle policies. In contrast, model predictive control (MPC) continually re-plans at each time step to remain robust to perturbations and model inaccuracies. However, despite its real-world successes, MPC often under-performs the optimal strategy. This is due to model quality, myopic behavior from short planning horizons, and approximations due to computational constraints. And even with a perfect model and enough compute, MPC can get stuck in bad local optima, depending heavily on the quality of the optimization algorithm. To this end, we propose Deep Model Predictive Optimization (DMPO), which learns the inner-loop of an MPC optimization algorithm directly via experience, specifically tailored to the needs of the control problem. We evaluate DMPO on a real quadrotor agile trajectory tracking task, on which it improves performance over a baseline MPC algorithm for a given computational budget. It can outperform the best MPC algorithm by up to 27% with fewer samples and an end-to-end policy trained with MFRL by 19%. Moreover, because DMPO requires fewer samples, it can also achieve these benefits with 4.3X less memory. When we subject the quadrotor to turbulent wind fields with an attached drag plate, DMPO can adapt zero-shot while still outperforming all baselines. Additional results can be found at https://tinyurl.com/mr2ywmnw.
Fast and Real-time End to End Control in Autonomous Racing Cars Through Representation Learning
Nov 30, 2021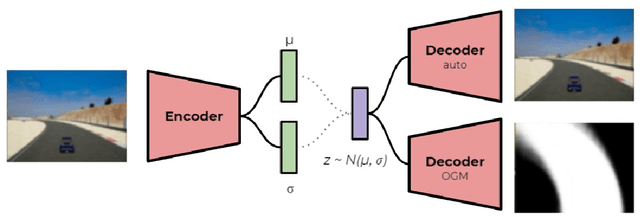

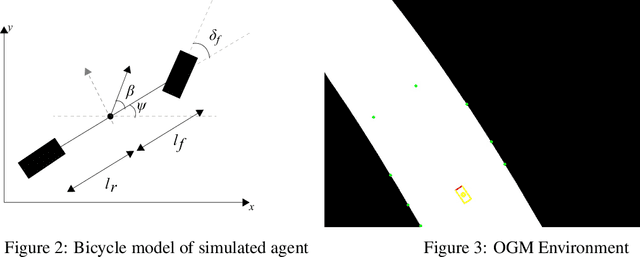

The challenges presented in an autonomous racing situation are distinct from those faced in regular autonomous driving and require faster end-to-end algorithms and consideration of a longer horizon in determining optimal current actions keeping in mind upcoming maneuvers and situations. In this paper, we propose an end-to-end method for autonomous racing that takes in as inputs video information from an onboard camera and determines final steering and throttle control actions. We use the following split to construct such a method (1) learning a low dimensional representation of the scene, (2) pre-generating the optimal trajectory for the given scene, and (3) tracking the predicted trajectory using a classical control method. In learning a low-dimensional representation of the scene, we use intermediate representations with a novel unsupervised trajectory planner to generate expert trajectories, and hence utilize them to directly predict race lines from a given front-facing input image. Thus, the proposed algorithm employs the best of two worlds - the robustness of learning-based approaches to perception and the accuracy of optimization-based approaches for trajectory generation in an end-to-end learning-based framework. We deploy and demonstrate our framework on CARLA, a photorealistic simulator for testing self-driving cars in realistic environments.
Memory Guided Road Detection
Jun 27, 2021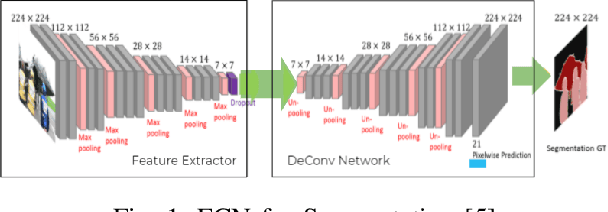


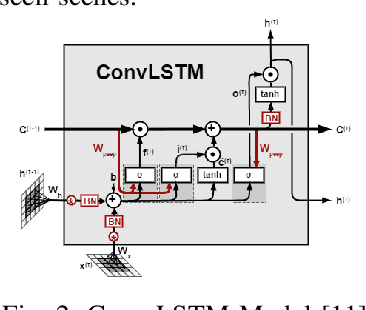
In self driving car applications, there is a requirement to predict the location of the lane given an input RGB front facing image. In this paper, we propose an architecture that allows us to increase the speed and robustness of road detection without a large hit in accuracy by introducing an underlying shared feature space that is propagated over time, which serves as a flowing dynamic memory. By utilizing the gist of previous frames, we train the network to predict the current road with a greater accuracy and lesser deviation from previous frames.