 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Variance Penalties and Domain Shift Robustness
Paper and Code

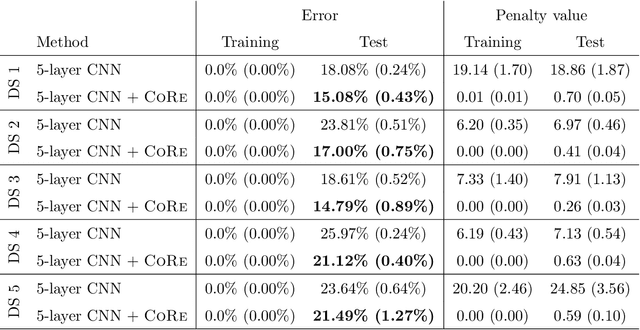


When training a deep network for image classification, one can broadly distinguish between two types of latent features of images that will drive the classification. Following the notation of Gong et al. (2016), we can divide latent features into (i) "core" features $X^\text{core}$ whose distribution $X^\text{core}\vert Y$ does not change substantially across domains and (ii) "style" features $X^{\text{style}}$ whose distribution $X^{\text{style}}\vert Y$ can change substantially across domains. These latter orthogonal features would generally include features such as rotation, image quality or brightness but also more complex ones like hair color or posture for images of persons. Guarding against future adversarial domain shifts implies that the influence of the second type of style features in the prediction has to be limited. We assume that the domain itself is not observed and hence a latent variable. We do assume, however, that we can sometimes observe a typically discrete identifier or $\mathrm{ID}$ variable. We know in some applications, for example, that two images show the same person, and $\mathrm{ID}$ then refers to the identity of the person. The method requires only a small fraction of images to have an $\mathrm{ID}$ variable. We group data samples if they share the same class and identifier $(Y,\mathrm{ID})=(y,\mathrm{id})$ and penalize the conditional variance of the prediction if we condition on $(Y,\mathrm{ID})$. Using this approach is shown to protect against shifts in the distribution of the style variables for both regression and classification models. Specifically, the conditional variance penalty CoRe is shown to be equivalent to minimizing the risk under noise interventions in a regression setting and is shown to lead to adversarial risk consistency in a partially linear classification setting.