 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn LP-based Sampling Policy for Multi-Armed Bandits with Side-Observations and Stochastic Availability
Mar 27, 2026We study the stochastic multi-armed bandit (MAB) problem where an underlying network structure enables side-observations across related actions. We use a bipartite graph to link actions to a set of unknowns, such that selecting an action reveals observations for all the unknowns it is connected to. While previous works rely on the assumption that all actions are permanently accessible, we investigate the more practical setting of stochastic availability, where the set of feasible actions (the "activation set") varies dynamically in each round. This framework models real-world systems with both structural dependencies and volatility, such as social networks where users provide side-information about their peers' preferences, yet are not always online to be queried. To address this challenge, we propose UCB-LP-A, a novel policy that leverages a Linear Programming (LP) approach to optimize exploration-exploitation trade-offs under stochastic availability. Unlike standard network bandit algorithms that assume constant access, UCB-LP-A computes an optimal sampling distribution over the realizable activation sets, ensuring that the necessary observations are gathered using only the currently active arms. We derive a theoretical upper bound on the regret of our policy, characterizing the impact of both the network structure and the activation probabilities. Finally, we demonstrate through numerical simulations that UCB-LP-A significantly outperforms existing heuristics that ignore either the side-information or the availability constraints.
BeST -- A Novel Source Selection Metric for Transfer Learning
Jan 19, 2025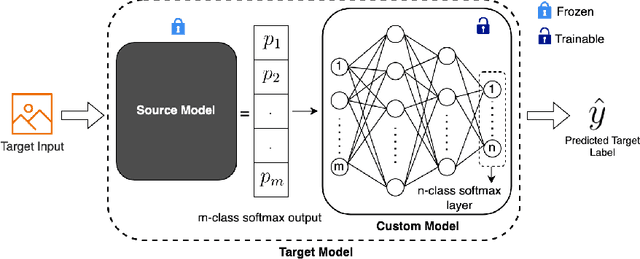

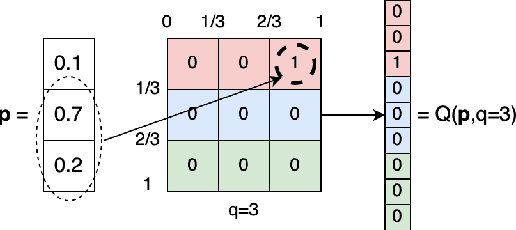

One of the most fundamental, and yet relatively less explored, goals in transfer learning is the efficient means of selecting top candidates from a large number of previously trained models (optimized for various "source" tasks) that would perform the best for a new "target" task with a limited amount of data. In this paper, we undertake this goal by developing a novel task-similarity metric (BeST) and an associated method that consistently performs well in identifying the most transferrable source(s) for a given task. In particular, our design employs an innovative quantization-level optimization procedure in the context of classification tasks that yields a measure of similarity between a source model and the given target data. The procedure uses a concept similar to early stopping (usually implemented to train deep neural networks (DNNs) to ensure generalization) to derive a function that approximates the transfer learning mapping without training. The advantage of our metric is that it can be quickly computed to identify the top candidate(s) for a given target task before a computationally intensive transfer operation (typically using DNNs) can be implemented between the selected source and the target task. As such, our metric can provide significant computational savings for transfer learning from a selection of a large number of possible source models. Through extensive experimental evaluations, we establish that our metric performs well over different datasets and varying numbers of data samples.