 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Shape Priors by Pairwise Comparison for Robust Semantic Segmentation
Paper and Code
Apr 23, 2022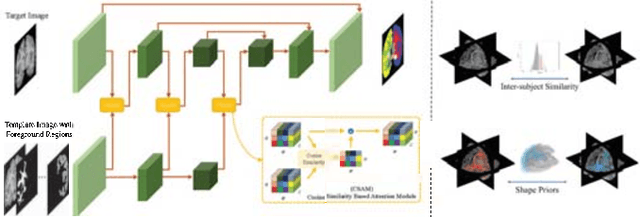
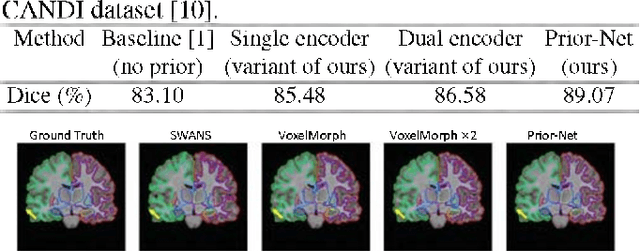
Semantic segmentation is important in medical image analysis. Inspired by the strong ability of traditional image analysis techniques in capturing shape priors and inter-subject similarity, many deep learning (DL) models have been recently proposed to exploit such prior information and achieved robust performance. However, these two types of important prior information are usually studied separately in existing models. In this paper, we propose a novel DL model to model both type of priors within a single framework. Specifically, we introduce an extra encoder into the classic encoder-decoder structure to form a Siamese structure for the encoders, where one of them takes a target image as input (the image-encoder), and the other concatenates a template image and its foreground regions as input (the template-encoder). The template-encoder encodes the shape priors and appearance characteristics of each foreground class in the template image. A cosine similarity based attention module is proposed to fuse the information from both encoders, to utilize both types of prior information encoded by the template-encoder and model the inter-subject similarity for each foreground class. Extensive experiments on two public datasets demonstrate that our proposed method can produce superior performance to competing methods.