 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Industry Evaluation of Embedding-based Entity Alignment
Paper and Code
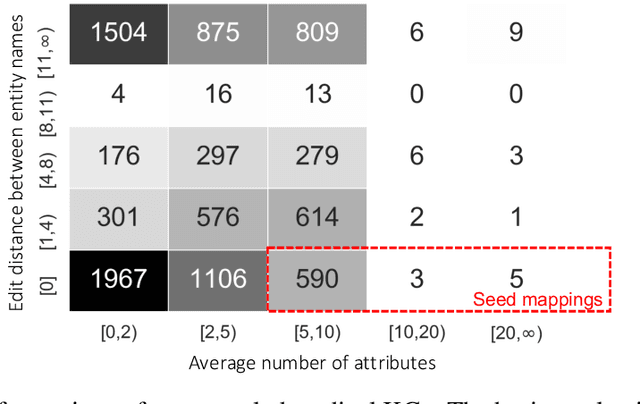

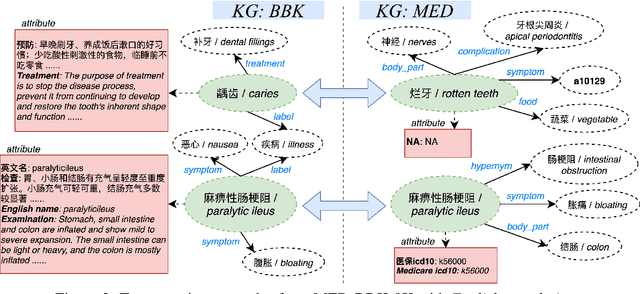
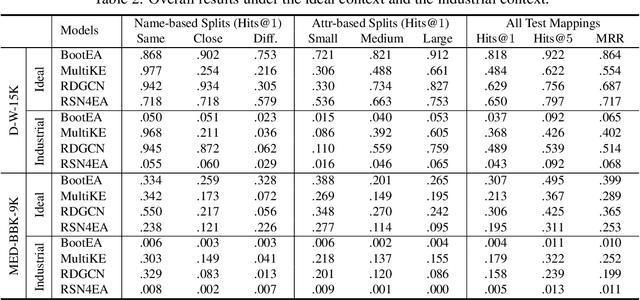
Embedding-based entity alignment has been widely investigated in recent years, but most proposed methods still rely on an ideal supervised learning setting with a large number of unbiased seed mappings for training and validation, which significantly limits their usage. In this study, we evaluate those state-of-the-art methods in an industrial context, where the impact of seed mappings with different sizes and different biases is explored. Besides the popular benchmarks from DBpedia and Wikidata, we contribute and evaluate a new industrial benchmark that is extracted from two heterogeneous knowledge graphs (KGs) under deployment for medical applications. The experimental results enable the analysis of the advantages and disadvantages of these alignment methods and the further discussion of suitable strategies for their industrial deployment.