 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparable Demonstrations are Important in In-Context Learning: A Novel Perspective on Demonstration Selection
Dec 12, 2023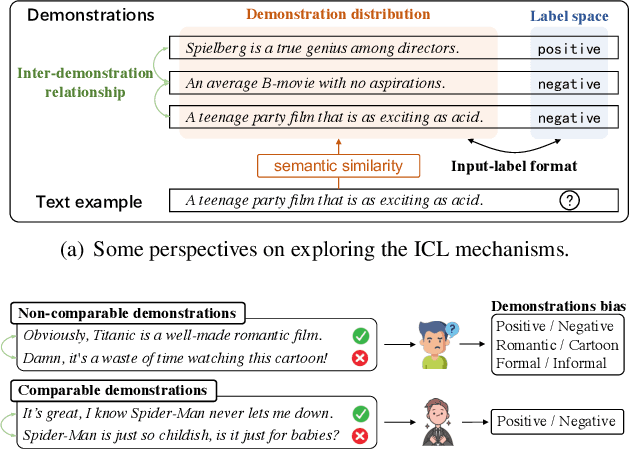

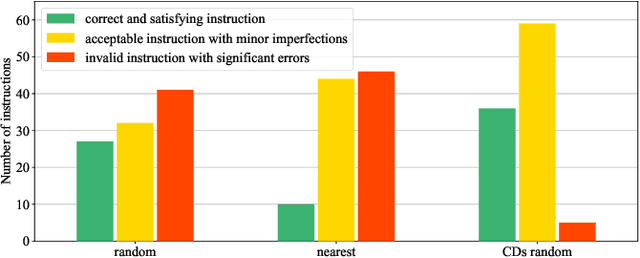

In-Context Learning (ICL) is an important paradigm for adapting Large Language Models (LLMs) to downstream tasks through a few demonstrations. Despite the great success of ICL, the limitation of the demonstration number may lead to demonstration bias, i.e. the input-label mapping induced by LLMs misunderstands the task's essence. Inspired by human experience, we attempt to mitigate such bias through the perspective of the inter-demonstration relationship. Specifically, we construct Comparable Demonstrations (CDs) by minimally editing the texts to flip the corresponding labels, in order to highlight the task's essence and eliminate potential spurious correlations through the inter-demonstration comparison. Through a series of experiments on CDs, we find that (1) demonstration bias does exist in LLMs, and CDs can significantly reduce such bias; (2) CDs exhibit good performance in ICL, especially in out-of-distribution scenarios. In summary, this study explores the ICL mechanisms from a novel perspective, providing a deeper insight into the demonstration selection strategy for ICL.
Can Large Language Models Serve as Rational Players in Game Theory? A Systematic Analysis
Dec 12, 2023
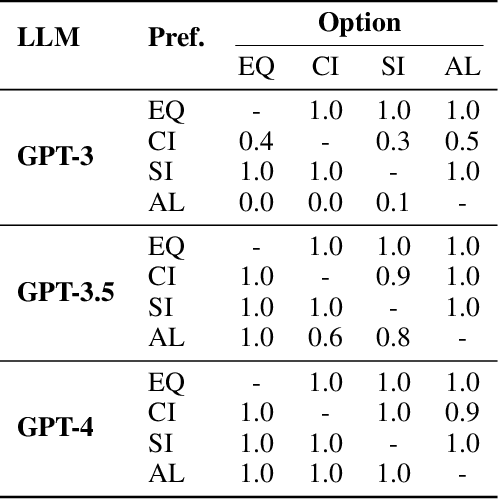

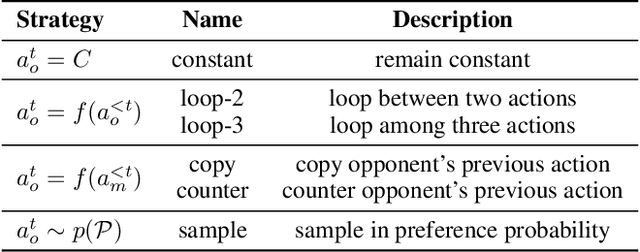
Game theory, as an analytical tool, is frequently utilized to analyze human behavior in social science research. With the high alignment between the behavior of Large Language Models (LLMs) and humans, a promising research direction is to employ LLMs as substitutes for humans in game experiments, enabling social science research. However, despite numerous empirical researches on the combination of LLMs and game theory, the capability boundaries of LLMs in game theory remain unclear. In this research, we endeavor to systematically analyze LLMs in the context of game theory. Specifically, rationality, as the fundamental principle of game theory, serves as the metric for evaluating players' behavior -- building a clear desire, refining belief about uncertainty, and taking optimal actions. Accordingly, we select three classical games (dictator game, Rock-Paper-Scissors, and ring-network game) to analyze to what extent LLMs can achieve rationality in these three aspects. The experimental results indicate that even the current state-of-the-art LLM (GPT-4) exhibits substantial disparities compared to humans in game theory. For instance, LLMs struggle to build desires based on uncommon preferences, fail to refine belief from many simple patterns, and may overlook or modify refined belief when taking actions. Therefore, we consider that introducing LLMs into game experiments in the field of social science should be approached with greater caution.
Chain-of-Thought Tuning: Masked Language Models can also Think Step By Step in Natural Language Understanding
Oct 18, 2023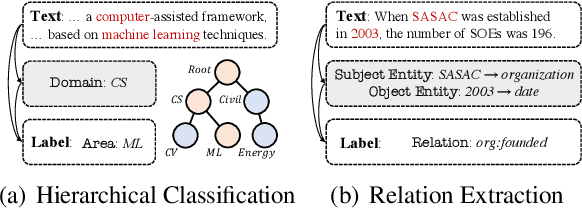
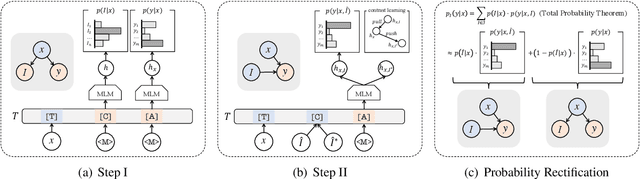
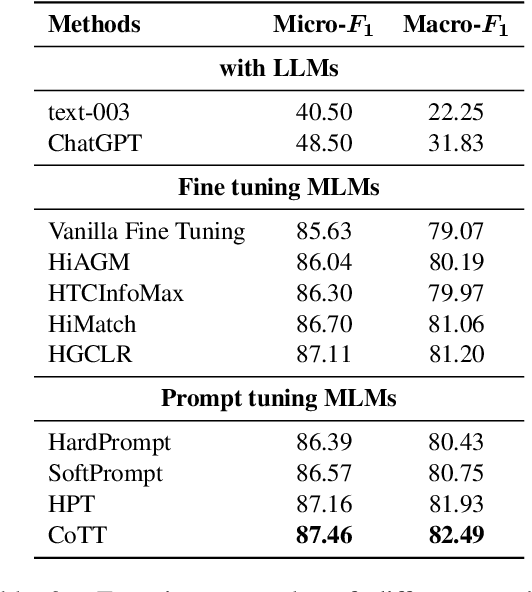
Chain-of-Thought (CoT) is a technique that guides Large Language Models (LLMs) to decompose complex tasks into multi-step reasoning through intermediate steps in natural language form. Briefly, CoT enables LLMs to think step by step. However, although many Natural Language Understanding (NLU) tasks also require thinking step by step, LLMs perform less well than small-scale Masked Language Models (MLMs). To migrate CoT from LLMs to MLMs, we propose Chain-of-Thought Tuning (CoTT), a two-step reasoning framework based on prompt tuning, to implement step-by-step thinking for MLMs on NLU tasks. From the perspective of CoT, CoTT's two-step framework enables MLMs to implement task decomposition; CoTT's prompt tuning allows intermediate steps to be used in natural language form. Thereby, the success of CoT can be extended to NLU tasks through MLMs. To verify the effectiveness of CoTT, we conduct experiments on two NLU tasks: hierarchical classification and relation extraction, and the results show that CoTT outperforms baselines and achieves state-of-the-art performance.
Accurate Use of Label Dependency in Multi-Label Text Classification Through the Lens of Causality
Oct 11, 2023Multi-Label Text Classification (MLTC) aims to assign the most relevant labels to each given text. Existing methods demonstrate that label dependency can help to improve the model's performance. However, the introduction of label dependency may cause the model to suffer from unwanted prediction bias. In this study, we attribute the bias to the model's misuse of label dependency, i.e., the model tends to utilize the correlation shortcut in label dependency rather than fusing text information and label dependency for prediction. Motivated by causal inference, we propose a CounterFactual Text Classifier (CFTC) to eliminate the correlation bias, and make causality-based predictions. Specifically, our CFTC first adopts the predict-then-modify backbone to extract precise label information embedded in label dependency, then blocks the correlation shortcut through the counterfactual de-bias technique with the help of the human causal graph. Experimental results on three datasets demonstrate that our CFTC significantly outperforms the baselines and effectively eliminates the correlation bias in datasets.
Unlock the Potential of Counterfactually-Augmented Data in Out-Of-Distribution Generalization
Oct 10, 2023

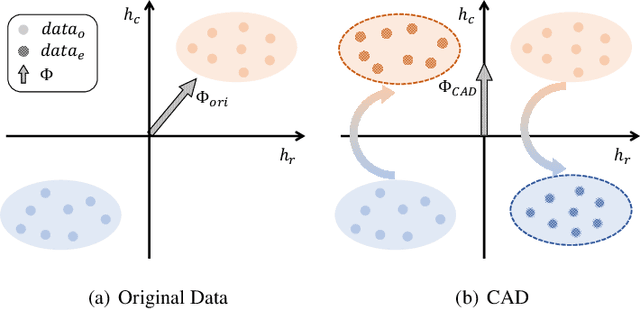

Counterfactually-Augmented Data (CAD) -- minimal editing of sentences to flip the corresponding labels -- has the potential to improve the Out-Of-Distribution (OOD) generalization capability of language models, as CAD induces language models to exploit domain-independent causal features and exclude spurious correlations. However, the empirical results of CAD's OOD generalization are not as efficient as anticipated. In this study, we attribute the inefficiency to the myopia phenomenon caused by CAD: language models only focus on causal features that are edited in the augmentation operation and exclude other non-edited causal features. Therefore, the potential of CAD is not fully exploited. To address this issue, we analyze the myopia phenomenon in feature space from the perspective of Fisher's Linear Discriminant, then we introduce two additional constraints based on CAD's structural properties (dataset-level and sentence-level) to help language models extract more complete causal features in CAD, thereby mitigating the myopia phenomenon and improving OOD generalization capability. We evaluate our method on two tasks: Sentiment Analysis and Natural Language Inference, and the experimental results demonstrate that our method could unlock the potential of CAD and improve the OOD generalization performance of language models by 1.0% to 5.9%.
Improving the Out-Of-Distribution Generalization Capability of Language Models: Counterfactually-Augmented Data is not Enough
Feb 18, 2023Counterfactually-Augmented Data (CAD) has the potential to improve language models' Out-Of-Distribution (OOD) generalization capability, as CAD induces language models to exploit causal features and exclude spurious correlations. However, the empirical results of OOD generalization on CAD are not as efficient as expected. In this paper, we attribute the inefficiency to Myopia Phenomenon caused by CAD: language models only focus on causal features that are edited in the augmentation and exclude other non-edited causal features. As a result, the potential of CAD is not fully exploited. Based on the structural properties of CAD, we design two additional constraints to help language models extract more complete causal features contained in CAD, thus improving the OOD generalization capability. We evaluate our method on two tasks: Sentiment Analysis and Natural Language Inference, and the experimental results demonstrate that our method could unlock CAD's potential and improve language models' OOD generalization capability.
MaxGNR: A Dynamic Weight Strategy via Maximizing Gradient-to-Noise Ratio for Multi-Task Learning
Feb 18, 2023



When modeling related tasks in computer vision, Multi-Task Learning (MTL) can outperform Single-Task Learning (STL) due to its ability to capture intrinsic relatedness among tasks. However, MTL may encounter the insufficient training problem, i.e., some tasks in MTL may encounter non-optimal situation compared with STL. A series of studies point out that too much gradient noise would lead to performance degradation in STL, however, in the MTL scenario, Inter-Task Gradient Noise (ITGN) is an additional source of gradient noise for each task, which can also affect the optimization process. In this paper, we point out ITGN as a key factor leading to the insufficient training problem. We define the Gradient-to-Noise Ratio (GNR) to measure the relative magnitude of gradient noise and design the MaxGNR algorithm to alleviate the ITGN interference of each task by maximizing the GNR of each task. We carefully evaluate our MaxGNR algorithm on two standard image MTL datasets: NYUv2 and Cityscapes. The results show that our algorithm outperforms the baselines under identical experimental conditions.
Dependent Multi-Task Learning with Causal Intervention for Image Captioning
May 18, 2021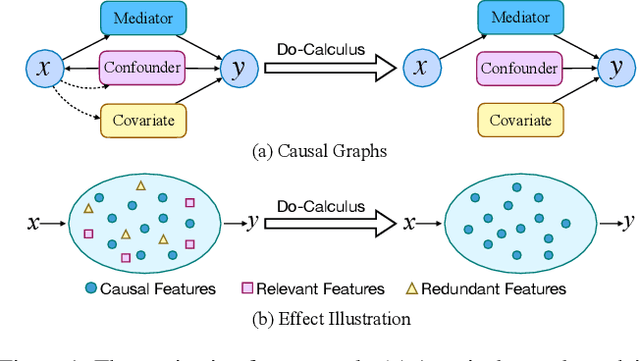

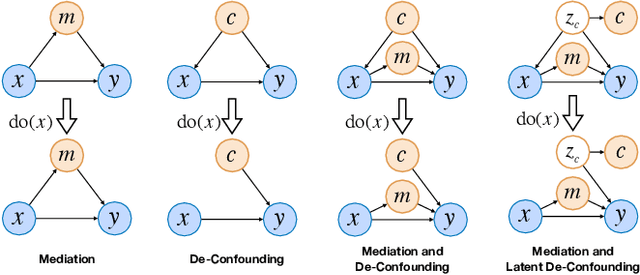

Recent work for image captioning mainly followed an extract-then-generate paradigm, pre-extracting a sequence of object-based features and then formulating image captioning as a single sequence-to-sequence task. Although promising, we observed two problems in generated captions: 1) content inconsistency where models would generate contradicting facts; 2) not informative enough where models would miss parts of important information. From a causal perspective, the reason is that models have captured spurious statistical correlations between visual features and certain expressions (e.g., visual features of "long hair" and "woman"). In this paper, we propose a dependent multi-task learning framework with the causal intervention (DMTCI). Firstly, we involve an intermediate task, bag-of-categories generation, before the final task, image captioning. The intermediate task would help the model better understand the visual features and thus alleviate the content inconsistency problem. Secondly, we apply Pearl's do-calculus on the model, cutting off the link between the visual features and possible confounders and thus letting models focus on the causal visual features. Specifically, the high-frequency concept set is considered as the proxy confounders where the real confounders are inferred in the continuous space. Finally, we use a multi-agent reinforcement learning (MARL) strategy to enable end-to-end training and reduce the inter-task error accumulations. The extensive experiments show that our model outperforms the baseline models and achieves competitive performance with state-of-the-art models.