 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Language Models Serve as Rational Players in Game Theory? A Systematic Analysis
Dec 12, 2023
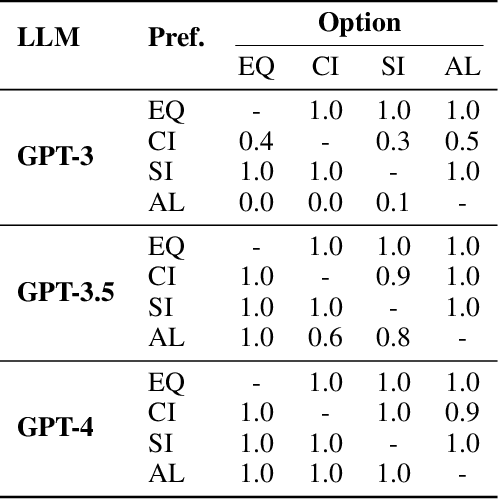

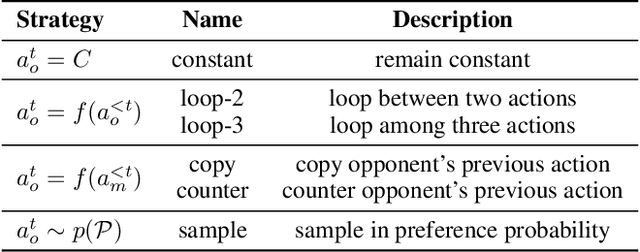
Game theory, as an analytical tool, is frequently utilized to analyze human behavior in social science research. With the high alignment between the behavior of Large Language Models (LLMs) and humans, a promising research direction is to employ LLMs as substitutes for humans in game experiments, enabling social science research. However, despite numerous empirical researches on the combination of LLMs and game theory, the capability boundaries of LLMs in game theory remain unclear. In this research, we endeavor to systematically analyze LLMs in the context of game theory. Specifically, rationality, as the fundamental principle of game theory, serves as the metric for evaluating players' behavior -- building a clear desire, refining belief about uncertainty, and taking optimal actions. Accordingly, we select three classical games (dictator game, Rock-Paper-Scissors, and ring-network game) to analyze to what extent LLMs can achieve rationality in these three aspects. The experimental results indicate that even the current state-of-the-art LLM (GPT-4) exhibits substantial disparities compared to humans in game theory. For instance, LLMs struggle to build desires based on uncommon preferences, fail to refine belief from many simple patterns, and may overlook or modify refined belief when taking actions. Therefore, we consider that introducing LLMs into game experiments in the field of social science should be approached with greater caution.